Xenium技术可以解决两个维度的问题
- 细胞在哪里——如何精确地勾划出细胞的形态和边界
- 当我们有了细胞边界的信息后,感兴趣的分析靶点,包括RNA和蛋白的位置在哪里
- 当我们有了这两个维度的信息,就可以在组织原位上进行单个细胞范围内的表达量计算counting;当我们知道了每一个细胞范围内的,不同的分子表达谱的分布,我们自然就能理解细胞的身份、状态以及细胞之间潜在的互作
Xenium技术的工作流程
- 整个工作流程需要3天,如果使用了5K的panel,可能需要延长到6天
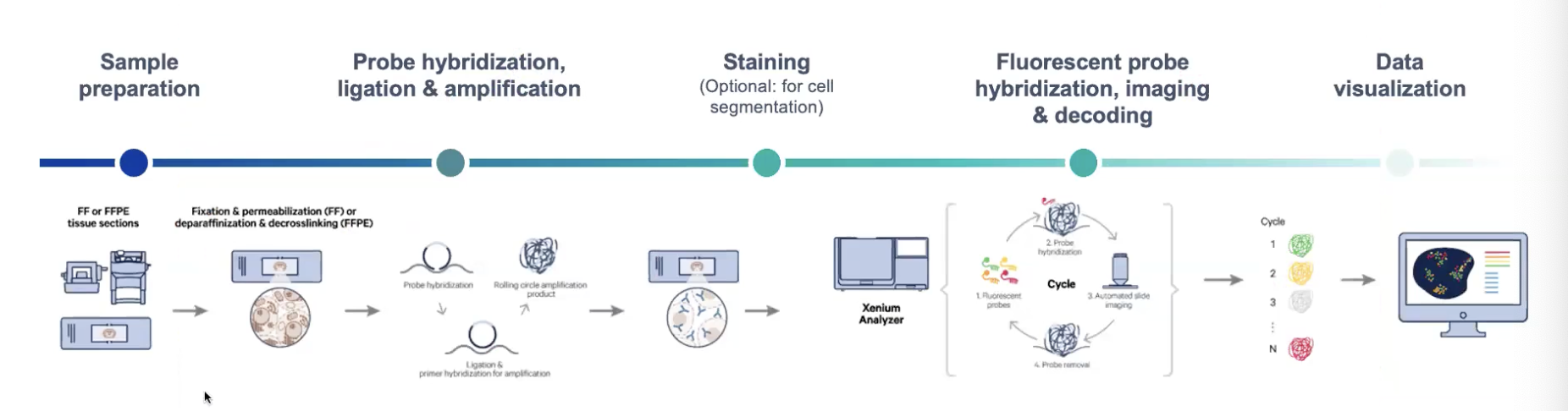
- 样品切片-贴片-脱蜡-解交联/透化
- 探针杂交-连接-扩增
- 染色:oligo标记的染色
- 荧光探针杂交,扩增,成像和解码(500个基因对应着15轮cycle,5000个基因需要32个cycle)
- 数据可视化
Xenium技术的原理
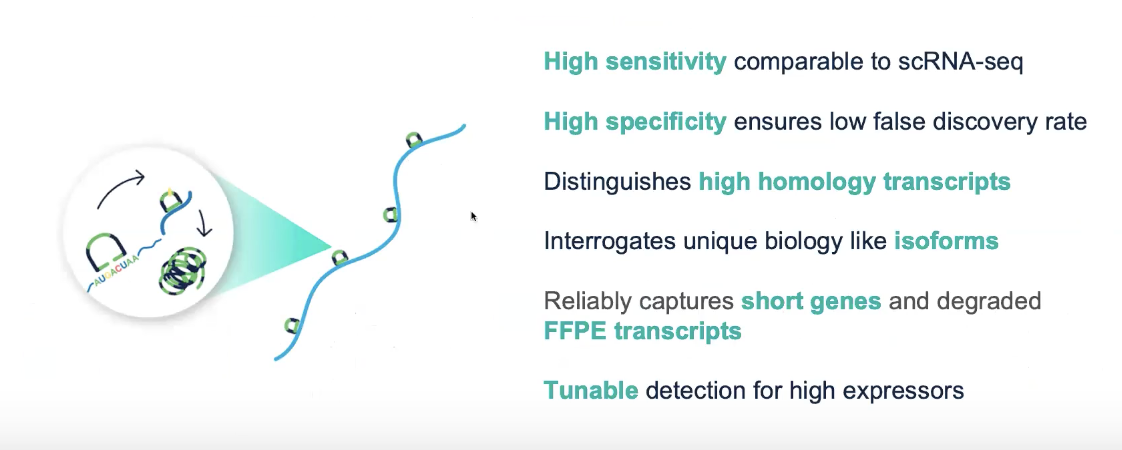
- 挂锁探针的设计原理与滚环扩增的信号
- 探针设计了双杂交区域,针对转录本的特定区域
- 探针与转录本结合后,会由DNA连接酶进行连接,从而形成闭环的探针
- 闭环的探针会被扩增,扩增后基因特异性的绿色barcode会被扩增,信号从而得到放大
- 可以区分高度同源的转录本、可变剪接和融合基因
- 通过原位成像的原理去区分不同的RNA的位置
Xenium数据的分析
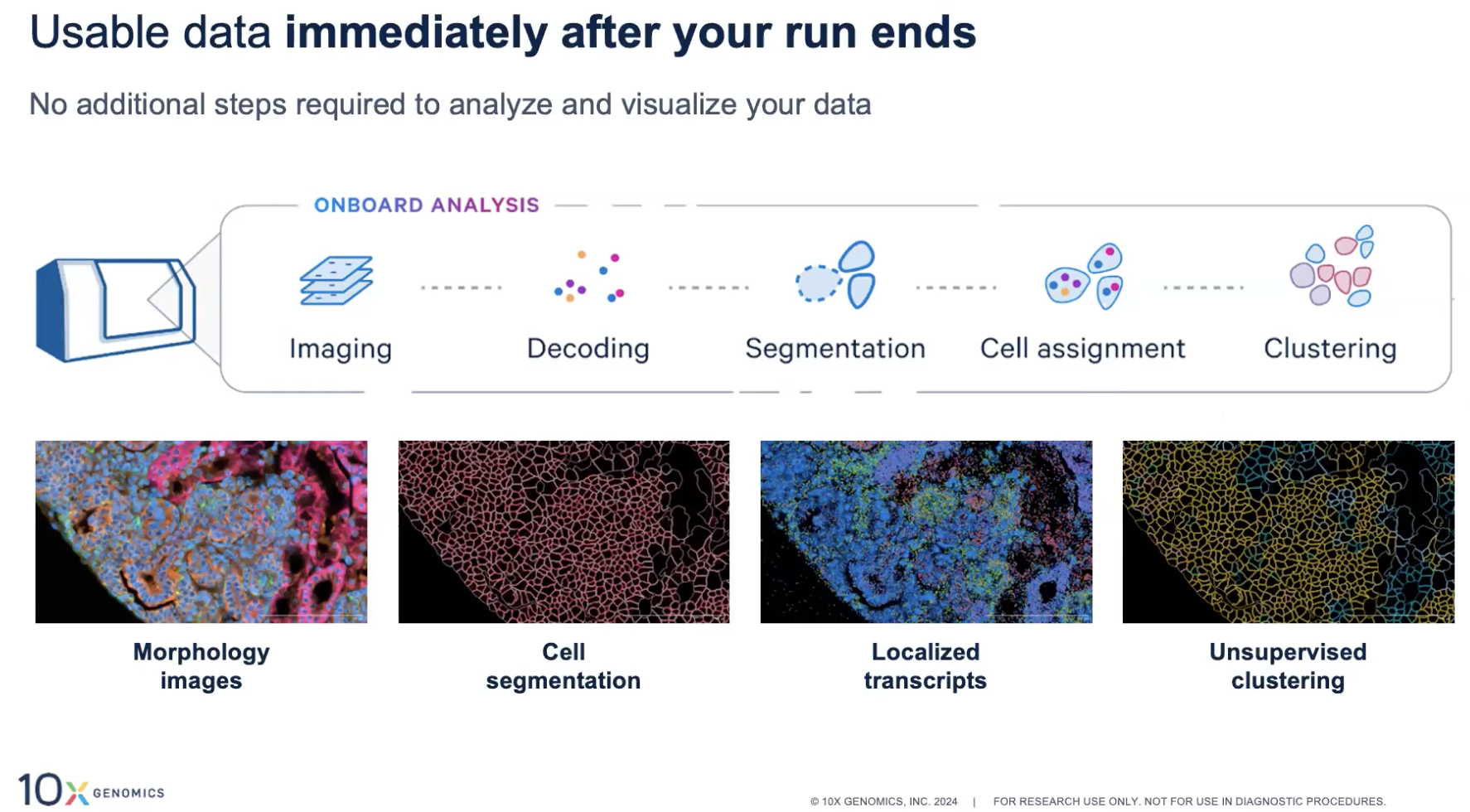
细胞位置的精确分割Cell Segmentation
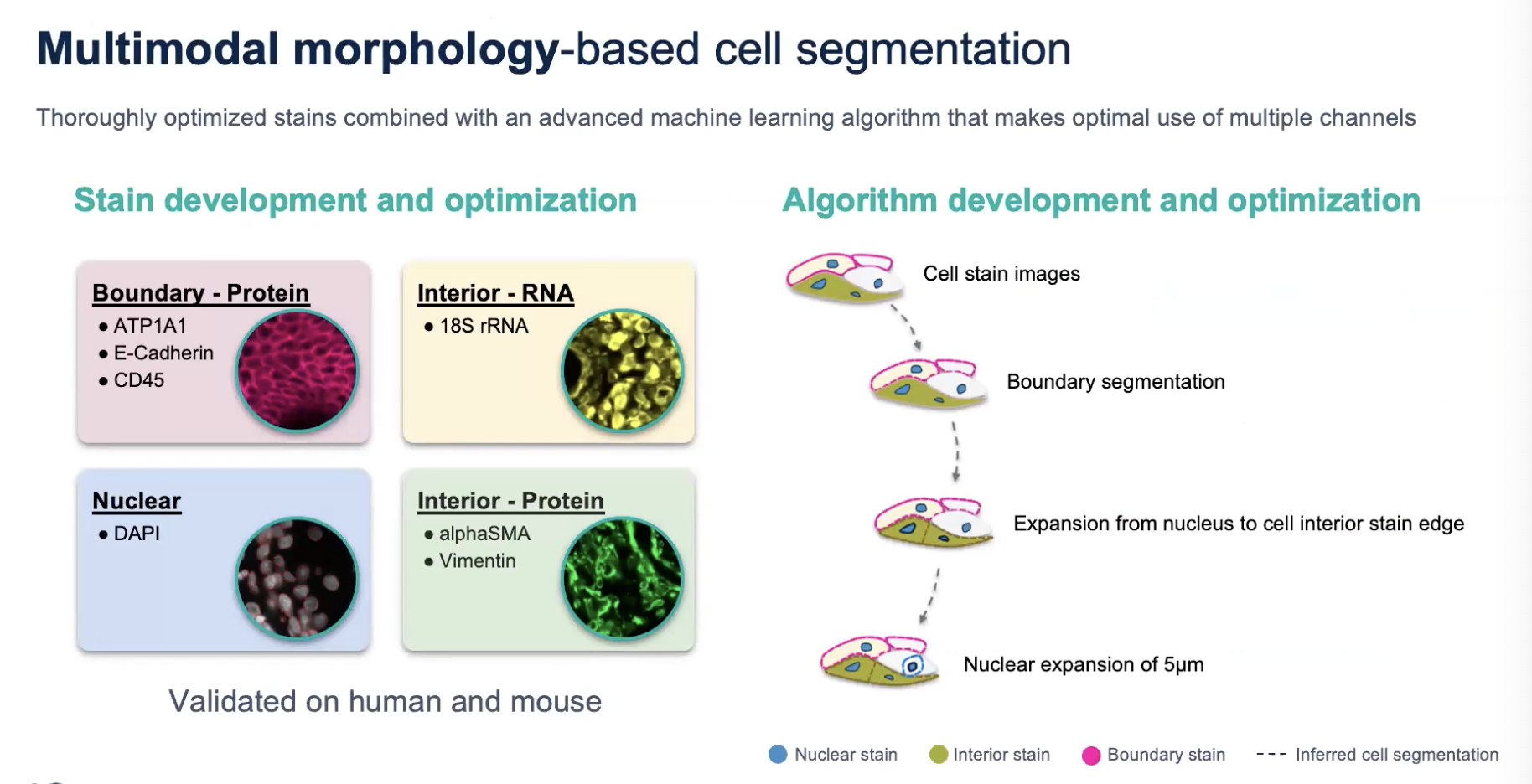
- 对细胞膜、细胞内容物(RNA和蛋白)以及细胞核进行染色,分成4个channel
- 首先利用细胞膜信息,也就是说细胞膜的优先级是最高的,如果细胞膜的完整性是可以确定的,那无论这个区域内是否存在细胞核,或存在几个细胞核,都会被我们界定为一个细胞,这个区域内的所有RNA都会被指派进来
- 如果细胞膜染色不能解决问题,那我们会进一步利用细胞质的信息,无论是蛋白质还是RNA,来实现对细胞轮廓的清晰界定
- 如果上述三种物质仍然不能解决细胞轮廓的界定,那我们会最后尝试利用细胞核的染色信息,在细胞核的染色上向外扩张5μm来实现对细胞边界的界定;如果在5μm扩张之前就遇到了细胞的边界,算法也会提前停止
- 这样的算法可以获得更加真实的结果(相比于之前只染细胞核,然后向外扩张15μm的版本)
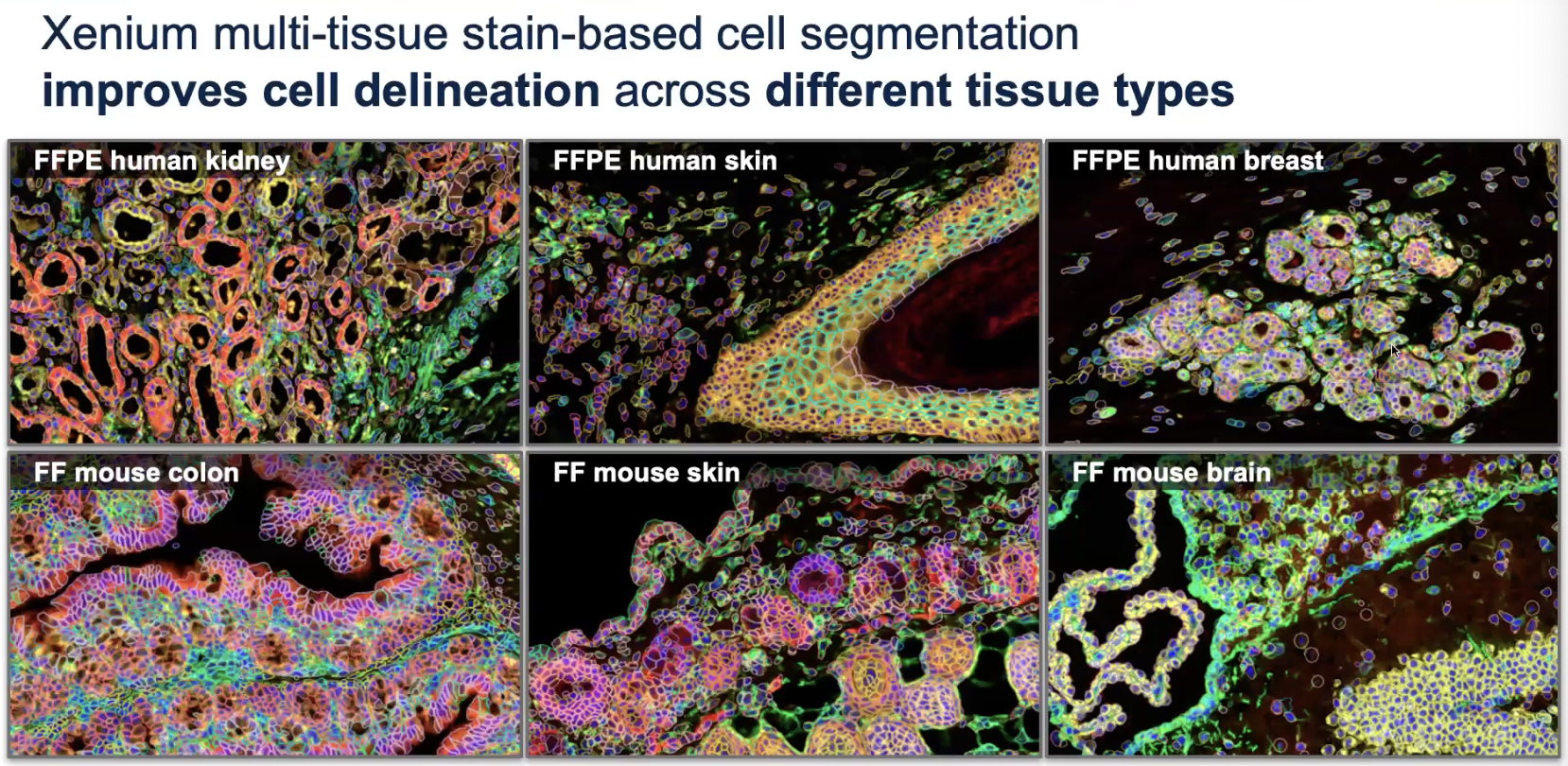
- 对于不同的组织,不同的channel对segmentation的贡献是不同的
Xenium 5K Pan Tissue & Pathway
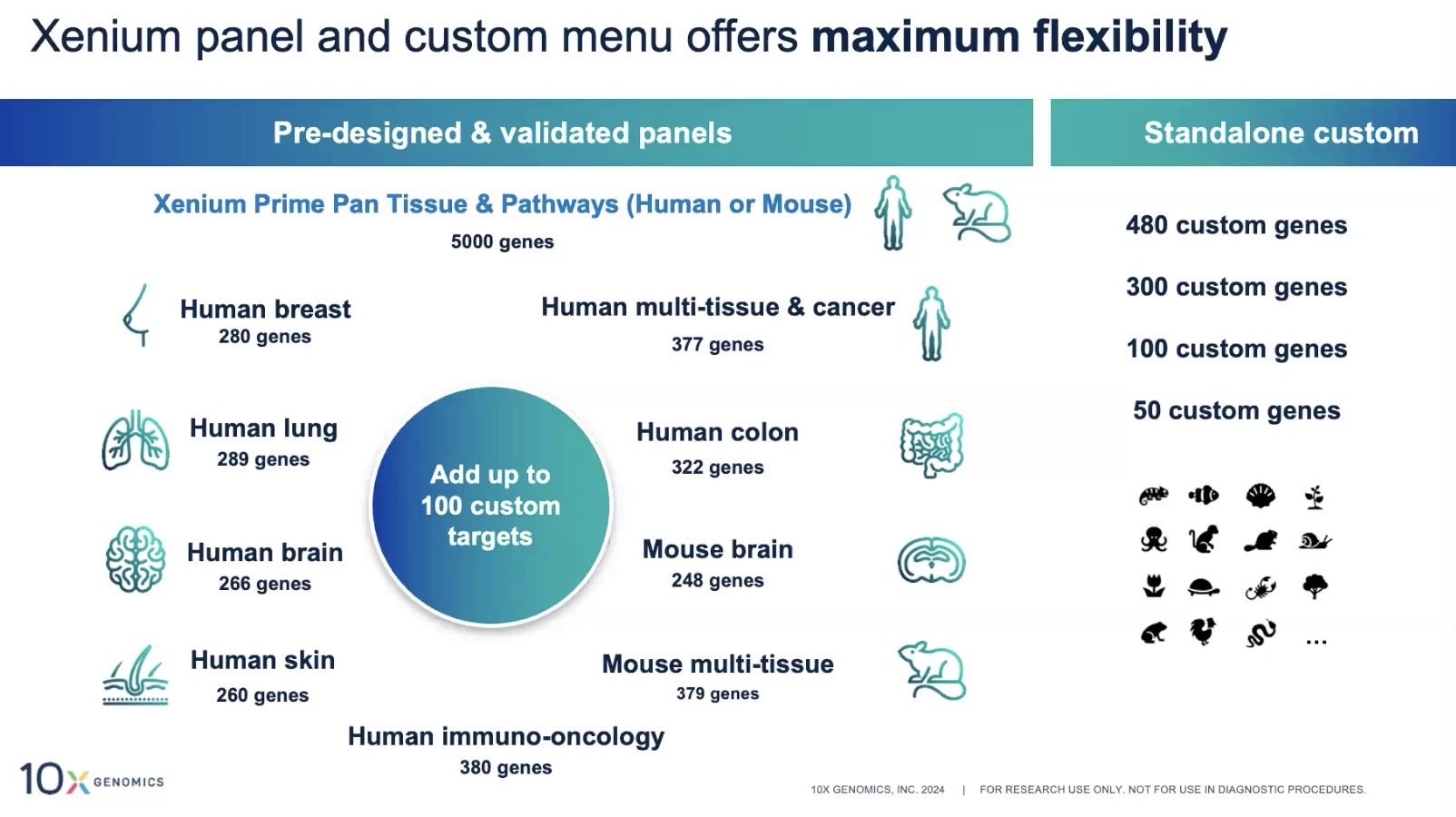
- 不同于V1版本的,针对不同的组织和疾病类型设计的panel,5K Pan-Tissue是更加综合性筛选的大panel,可以对不同的组织和类型中,筛选出Cell Typing Marker,重要的信号通路筛选,药物相关的靶点,Cell-Cell Signaling Marker
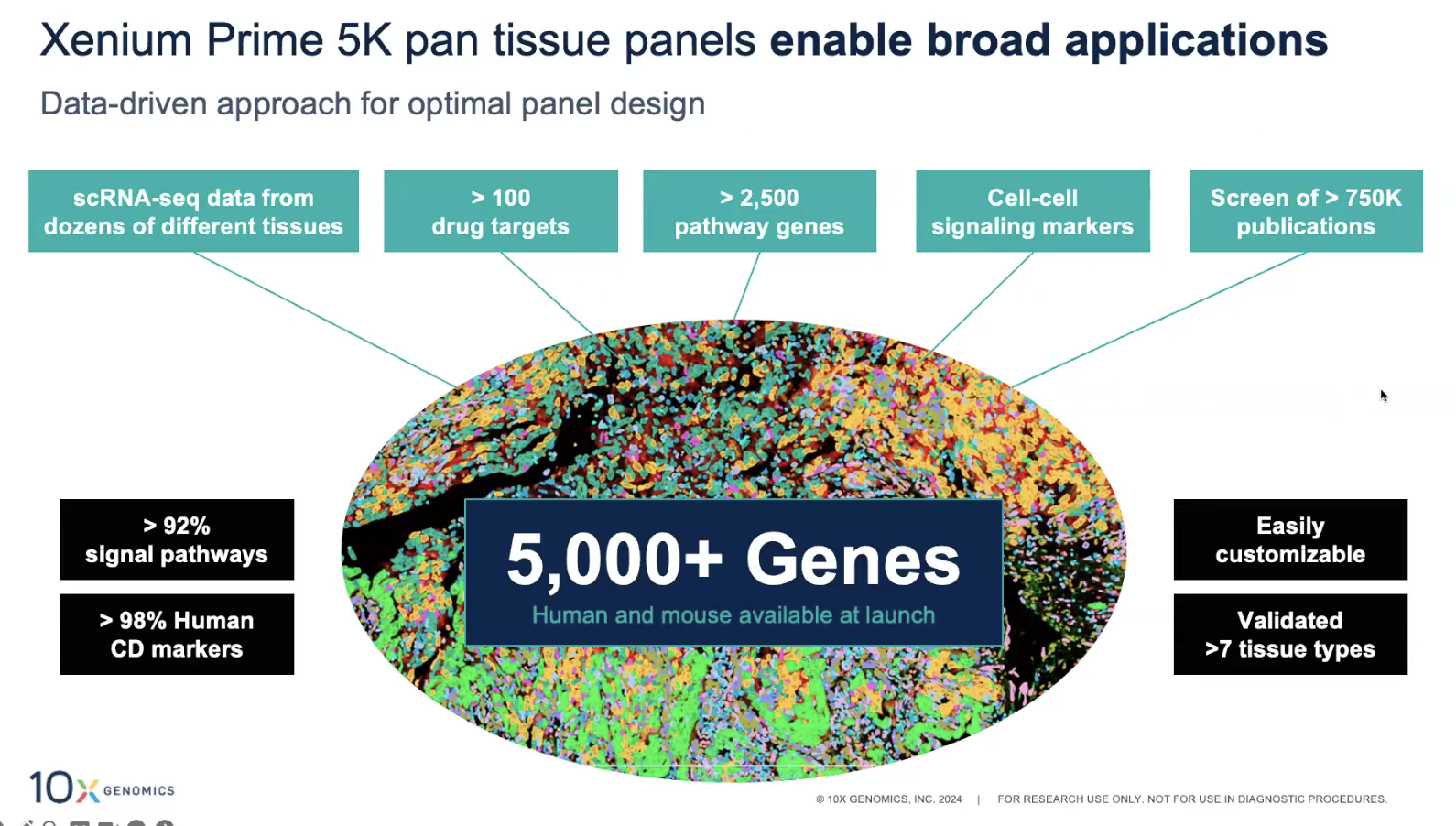
- 在5K panel的研发过程中,10x对不同的组织进行了测试;如果感兴趣的组织没有在这些tested tissue中,仍然是可以使用的

Xenium panel的大小
- 基准框fiducial frame:12✖️24mm
- 组织的大小:不要超过10.5✖️22.5mm
Xenium样品
人肝癌样本
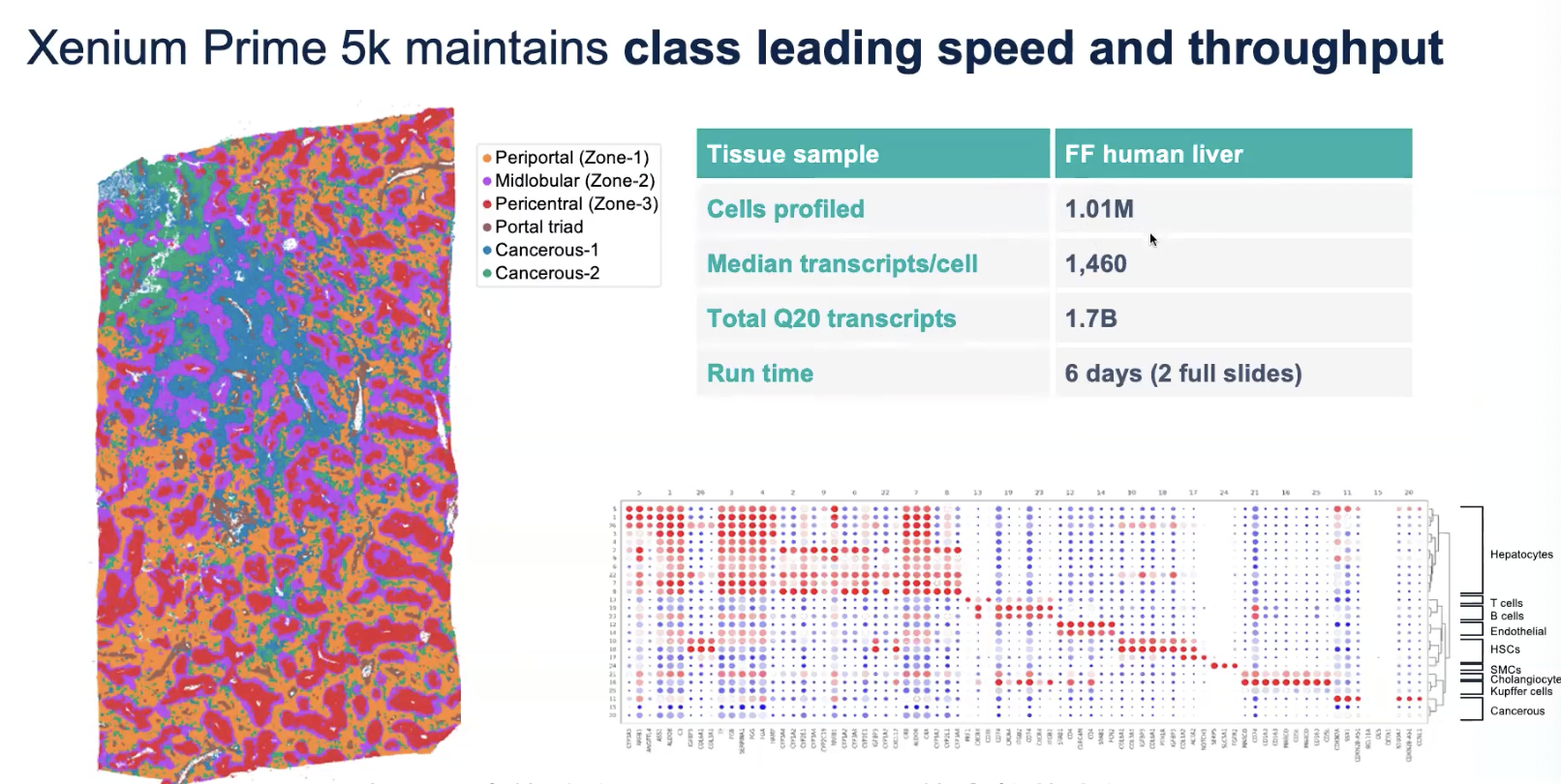
- Fresh Frozen样品,1✖️2cm
- 在这个样品之中,发现了不同种类的细胞在空间上的分布是不同的,整个样品中得到了超过了100万的细胞,平均每个细胞捕捉到了不到1500条转录本,两张slides放满decode花了6天
肺癌的FFPE样本
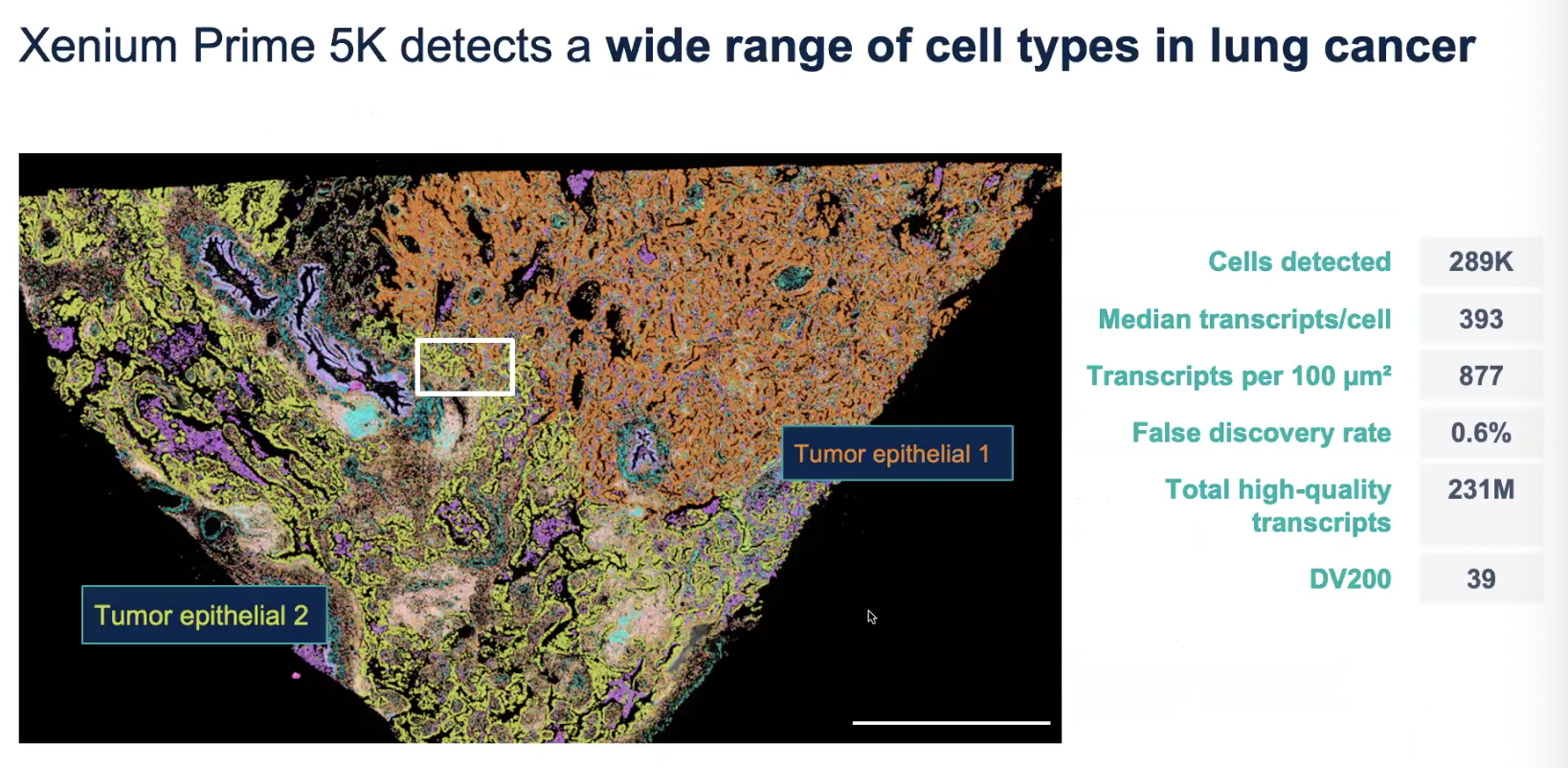
- FFPE样品的质量不佳,DV200值只有39
- 捕捉到的细胞数量和每个细胞捕捉到的转录本的数量都很低
- number of transcript per cell的值和组织中的细胞类型、平均的细胞大小和细胞的转录活跃程度、panel与组织中的细胞类型的相关程度等都有关,也和样本的讲解程度也有关联
FFPE的肝和乳腺样本
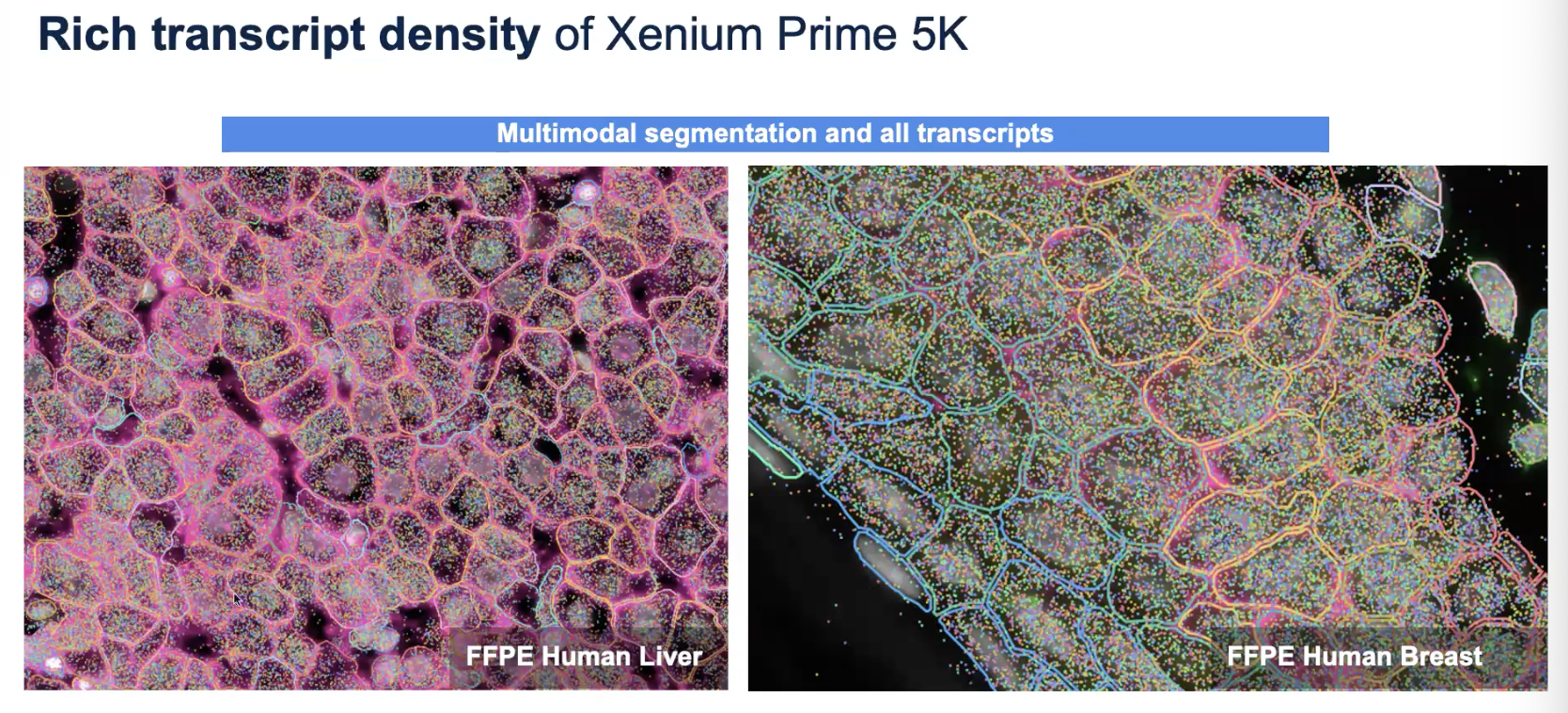
- 100平方微米的转录本数目是一个独立于组织细胞类型的指标,可以有效地反应组织的质量
- 我们最后看到的信息都是transcript with cells segmented ,对于那些不在细胞中的转录本,会被我们直接作为背景忽略(除非感兴趣的是病毒的序列)
小的panel能满足实验设计就继续用
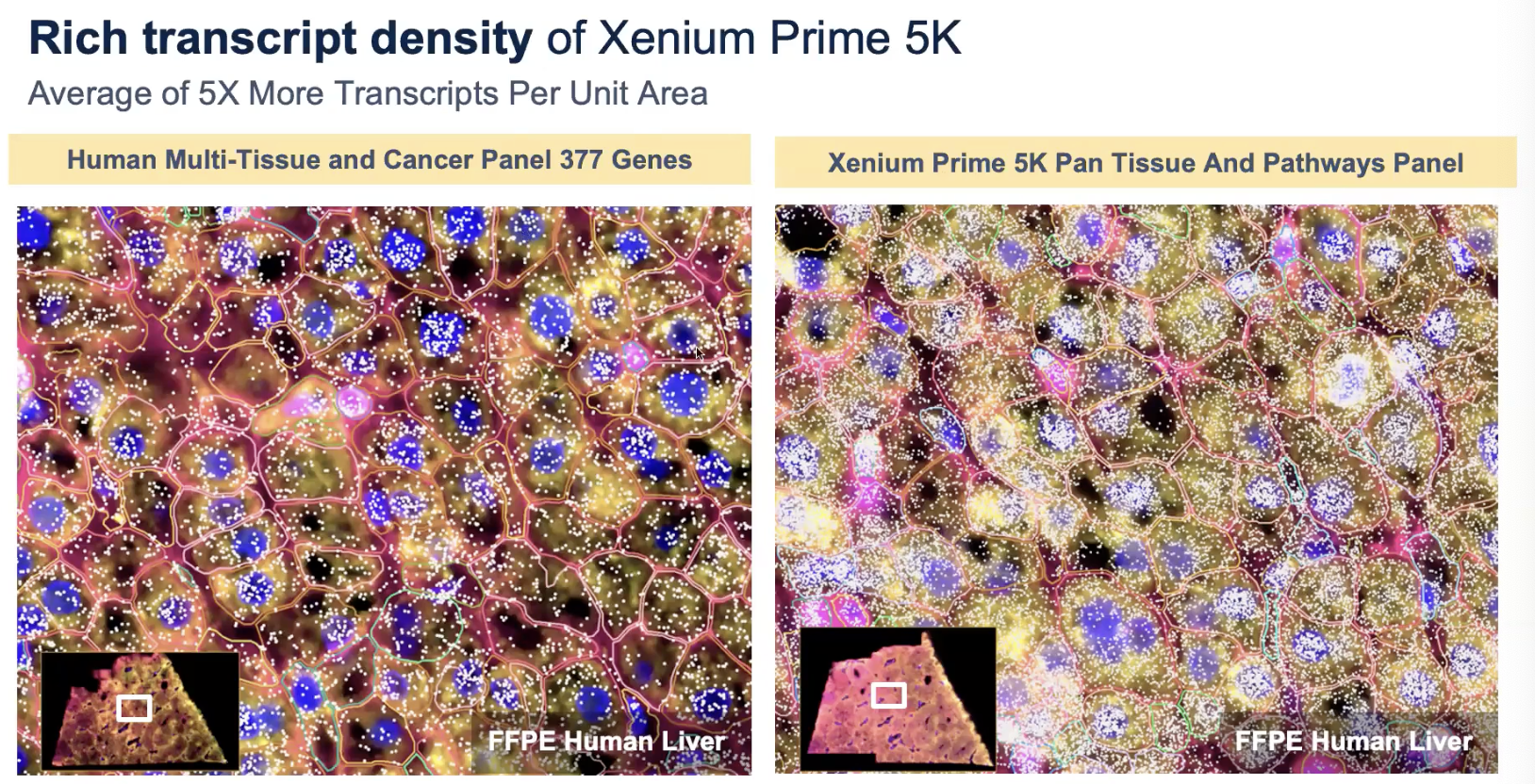
- 可以使用小的panel结合新的cell segmentation method去实现更好的细胞分割效果
- 但是,5K的大panel可以带来更多通路上的discovery
- 使用5K的panel可以看到捕获的转录本的数量大大增加了(5倍),意味着可以覆盖的生物学通路数量大大增加了
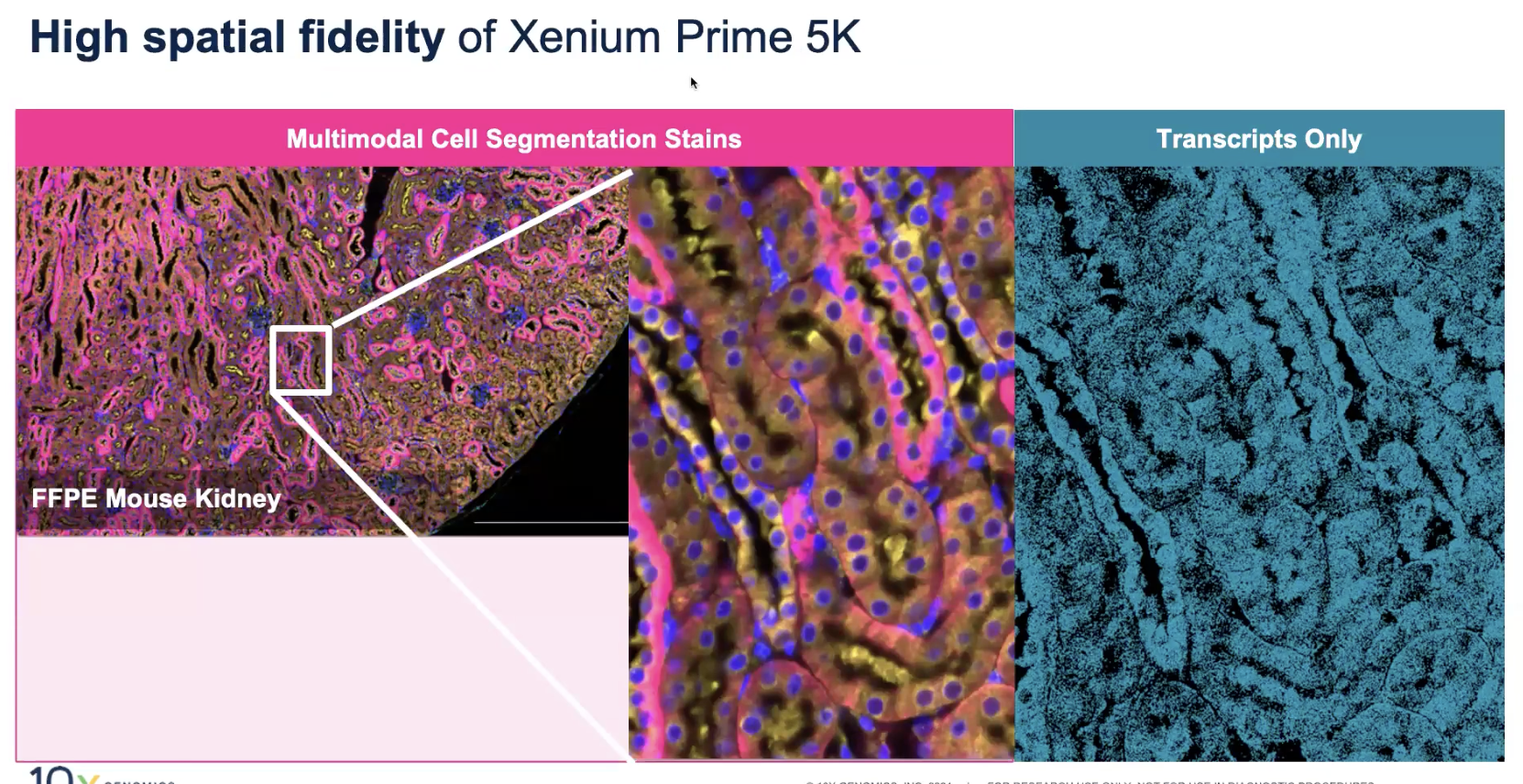
- 上图是小鼠的肾脏样本,哪怕是纯转录本的图谱,也能一定程度上去重现组织和微环境当中的结构;合并了每个细胞的边界和生物学通路的信息,我们可以在这一堆生物学信号中去挖掘,组织微环境中有哪些细胞,这些细胞在干什么
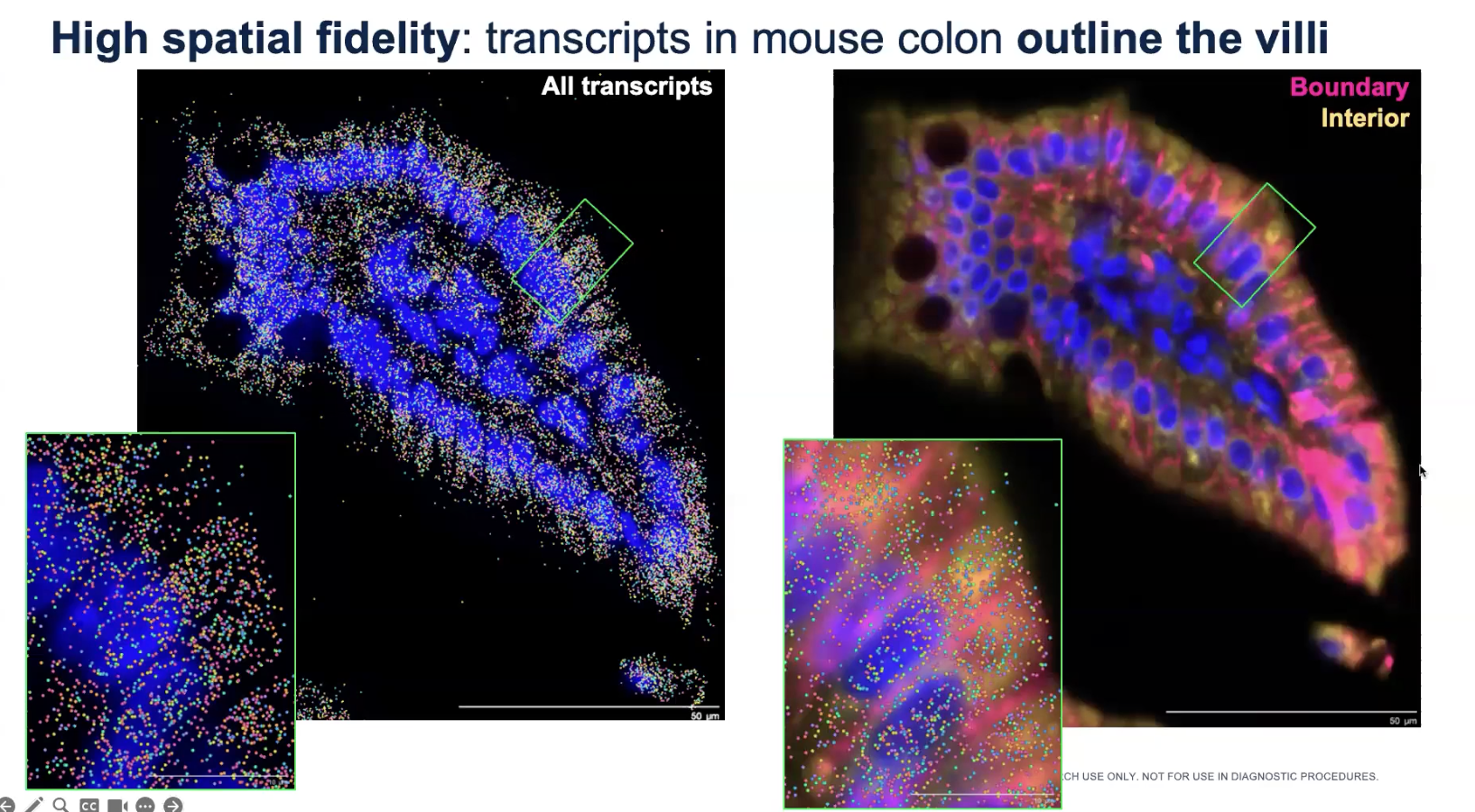
- 上图是小鼠的结肠样本,我们看到DAPI+转录本的数据就已经足够重现小鼠肠道细胞的结构,展示了cell segmentation的方法是非常准确的,此外,transcript localization的精度也非常高,把这两个信息进行重叠后就可以对功能学进行进一步的注释和研究
在5k panel中可以添加最多100个基因
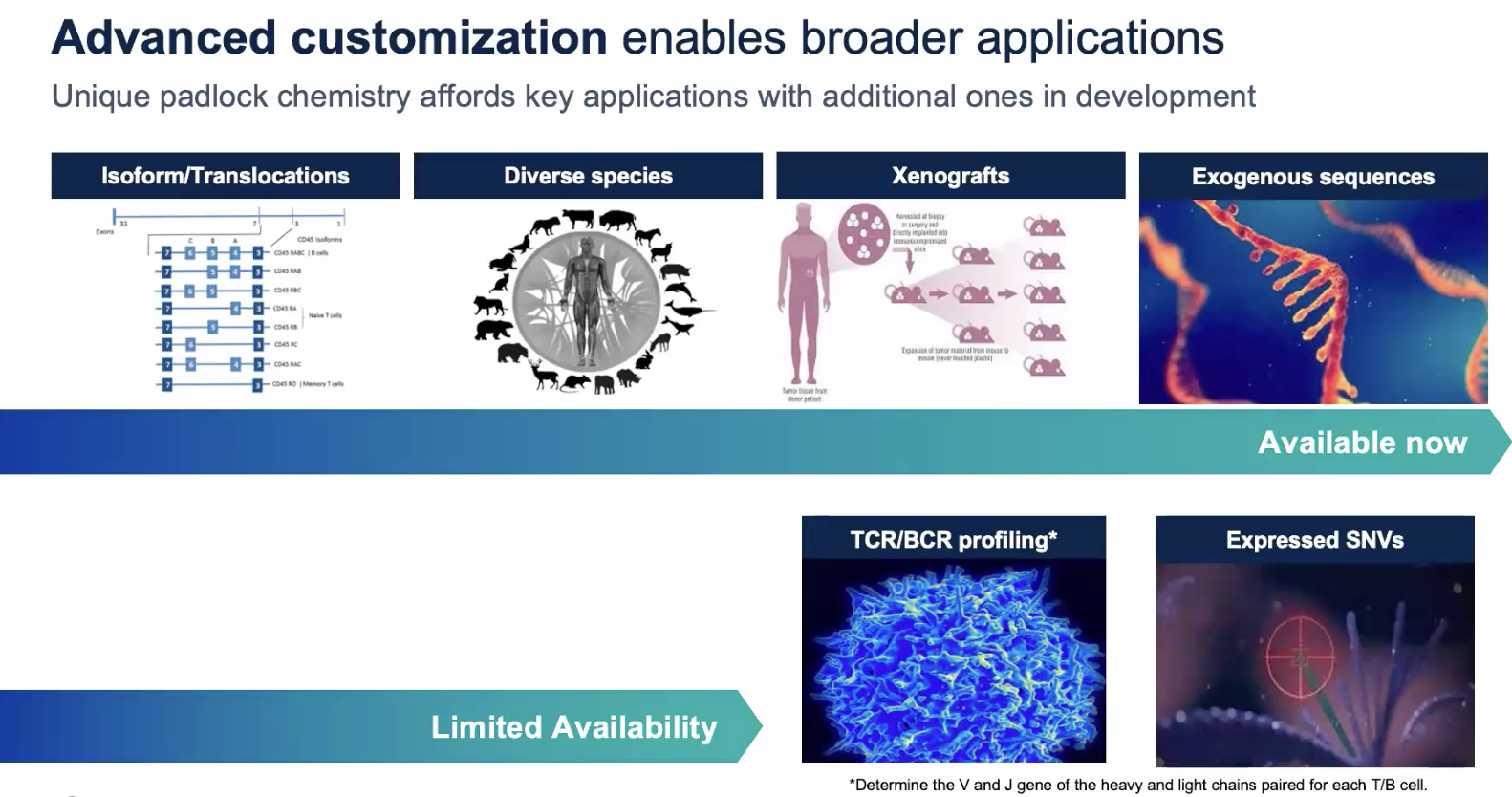
- 人和小鼠可以添加最多100个基因到5K的panel中
- 其他物种stand-alone的panel定制支持480个gene
- 高级定制
- TCR/BCR,SNV等暂时不太可用
Xenium支持各种FF和FFPE样本
- 我们可以把一个物种的不同组织放到一张片子上去进行拼片,增加效率同时减少一个样本的成本
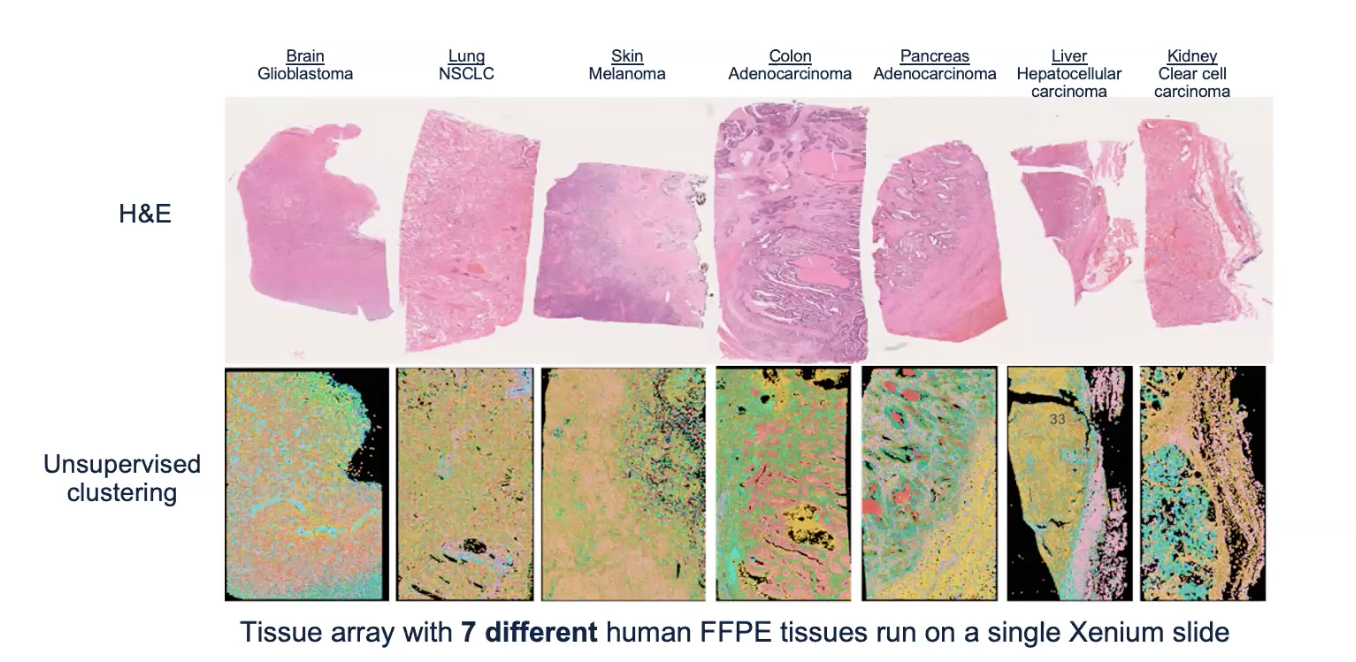

- Xenium的protocal对FFPE和FF都是标准化的手册,无需对特定的组织类型分别进行实验前的各种优化(除了骨组织去钙化)
Xenium样本支持各种后续处理
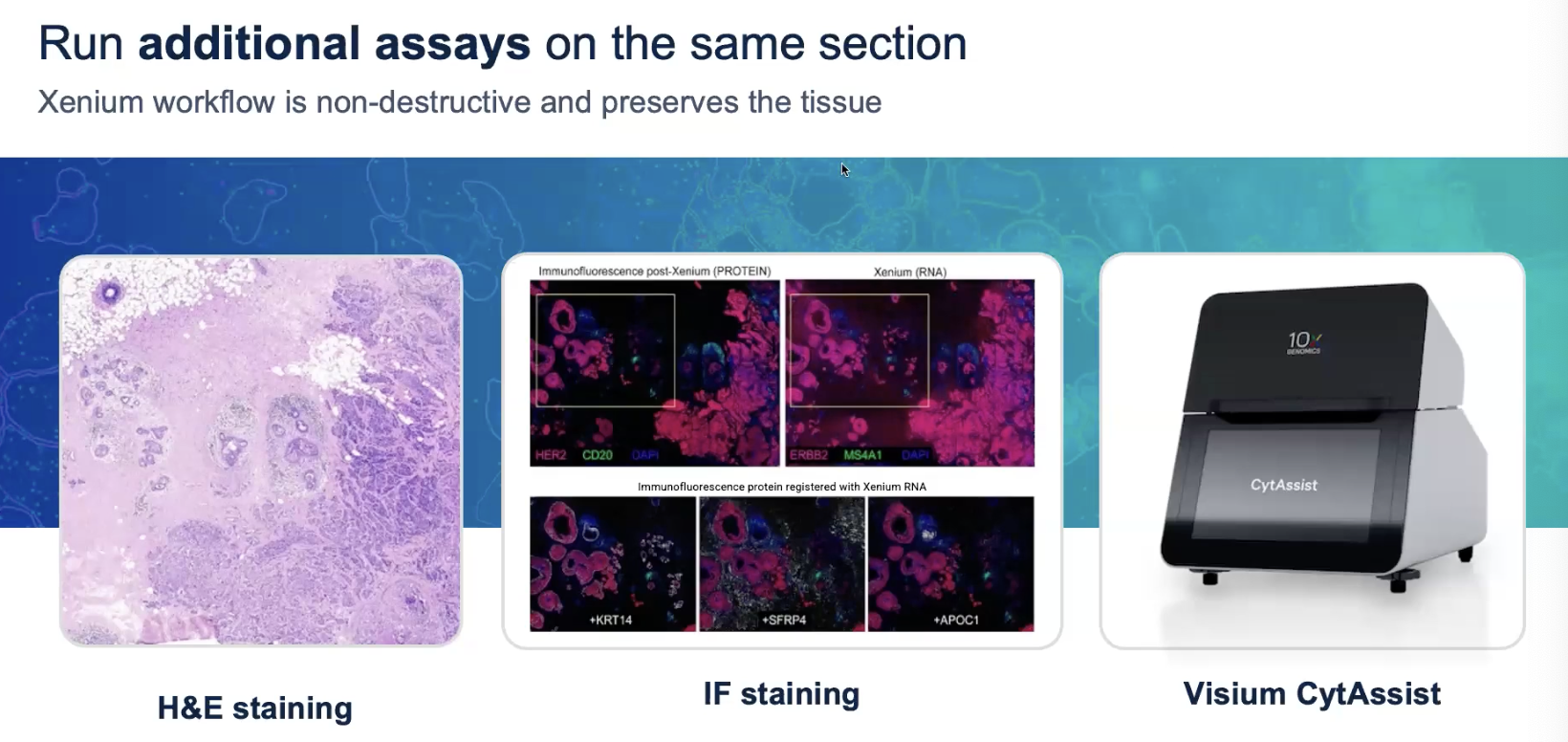
- HE染色
- 免疫荧光
- Visium CytAssist/HD
预览Xenium分析数据:Xenium Explorer
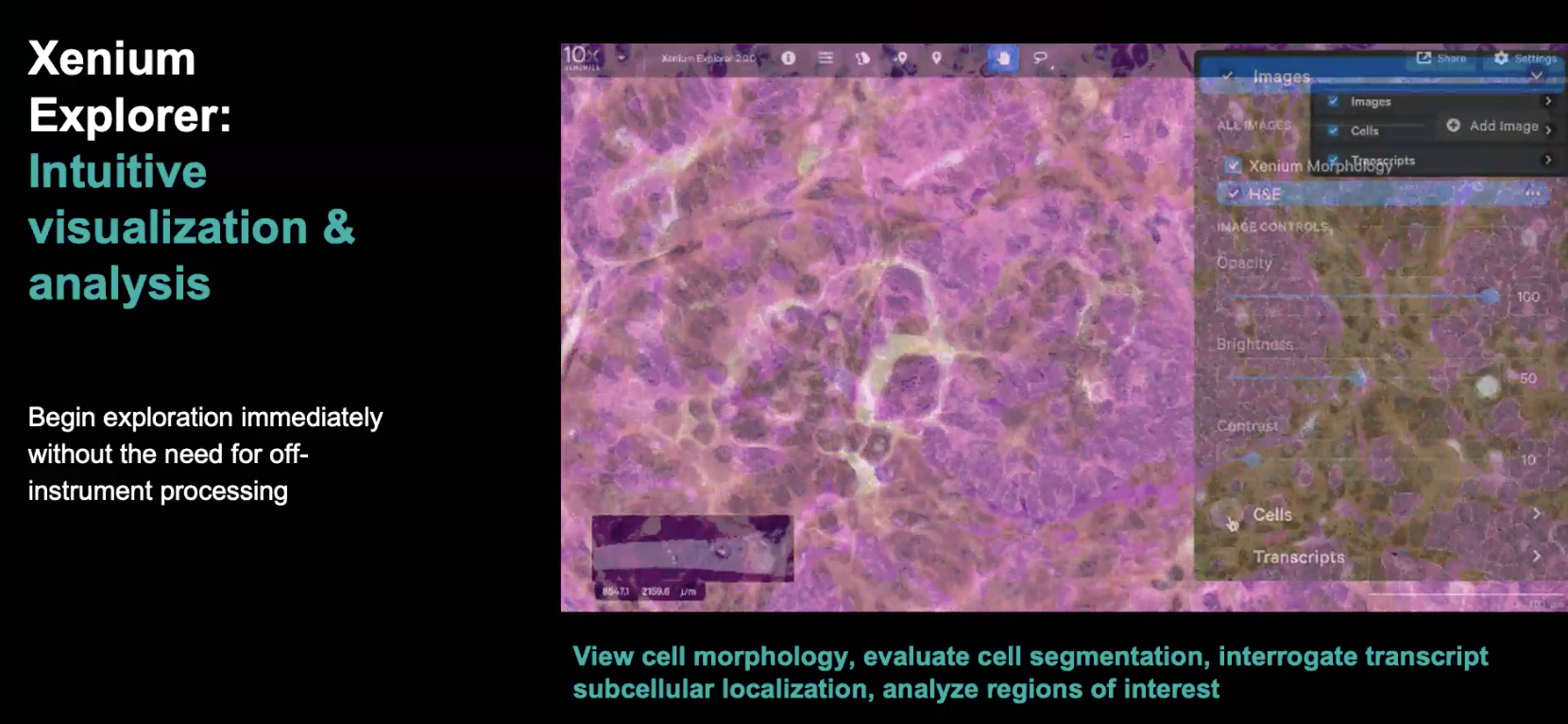
- 随着5K的comprehensive panel的推出,Xenium已经逐渐从中下游的验证技术,朝着single cell和全转录组的空间技术的方向移动了一大步
Xenium Prime Workfolow
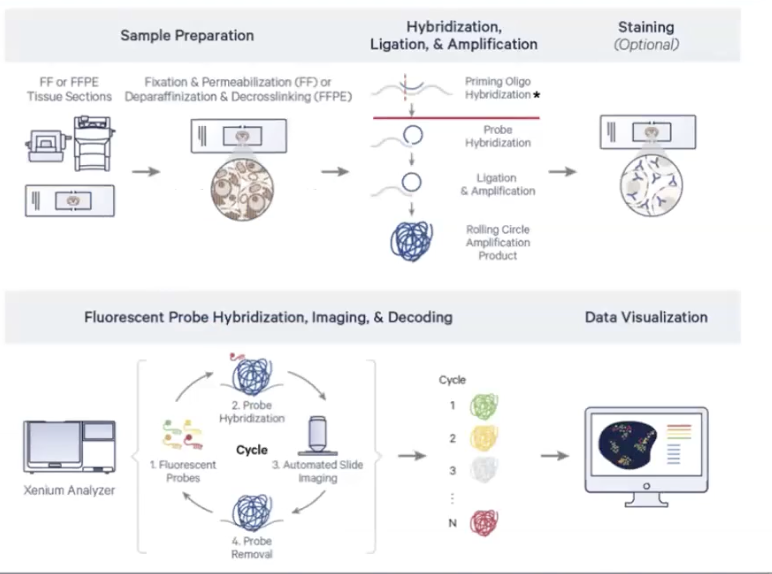
- 样本的制备:切片、贴片(可以拼片),一次实验通量是两张玻璃片,所以能够获得非常多的数据
- FF样本:切片后固定和透化
- FFPE样本:脱蜡和解交联
- 在探针杂交前,多了一步杂交的过程(将引物的寡聚核苷酸与样本进行交联),为了使5000个基因的探针更好的与样本准确结合
- 可选的多模态染色(为了更准确的细胞分割)
- 上机
- 500个基因的panel:最长不会超过3天,包含结果输出
- 5000个基因的panel:最长不会超过1周
10x官网提供了对应的workflow protocal
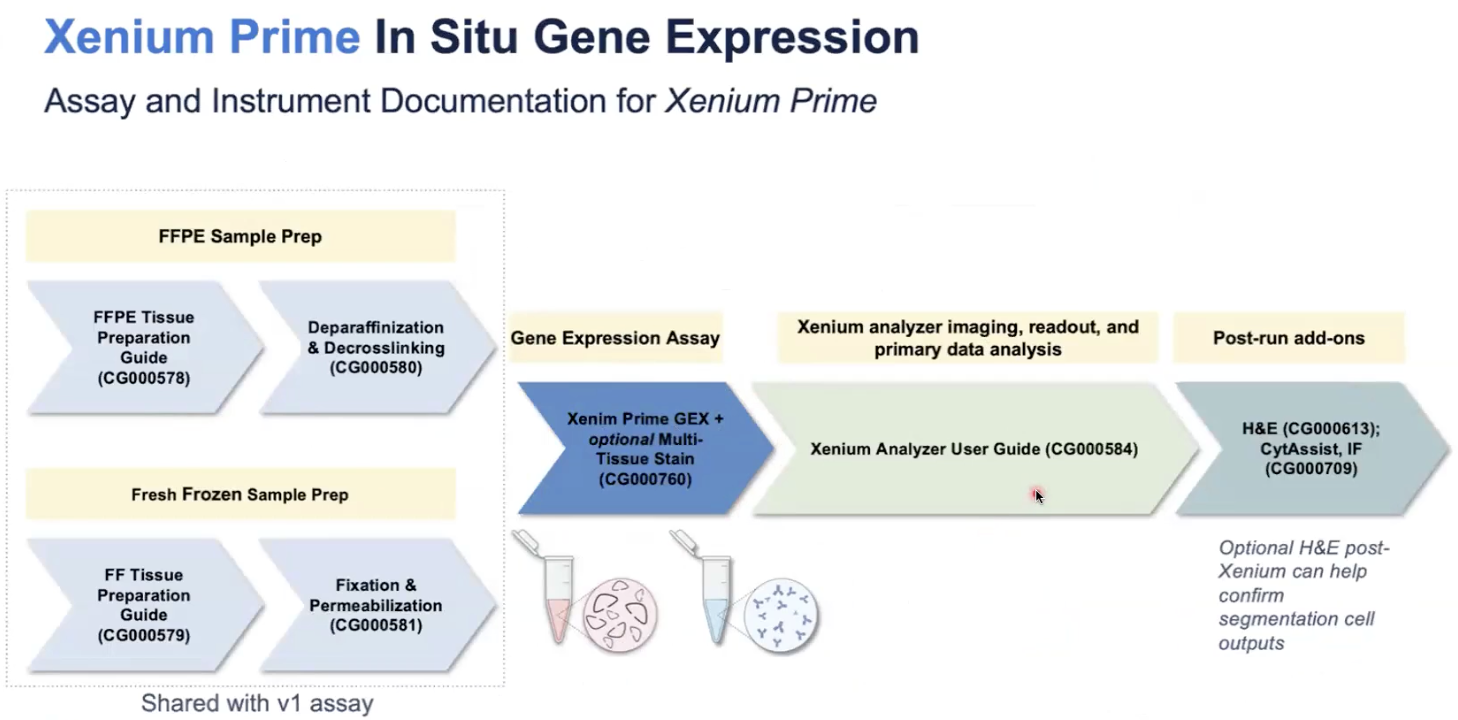
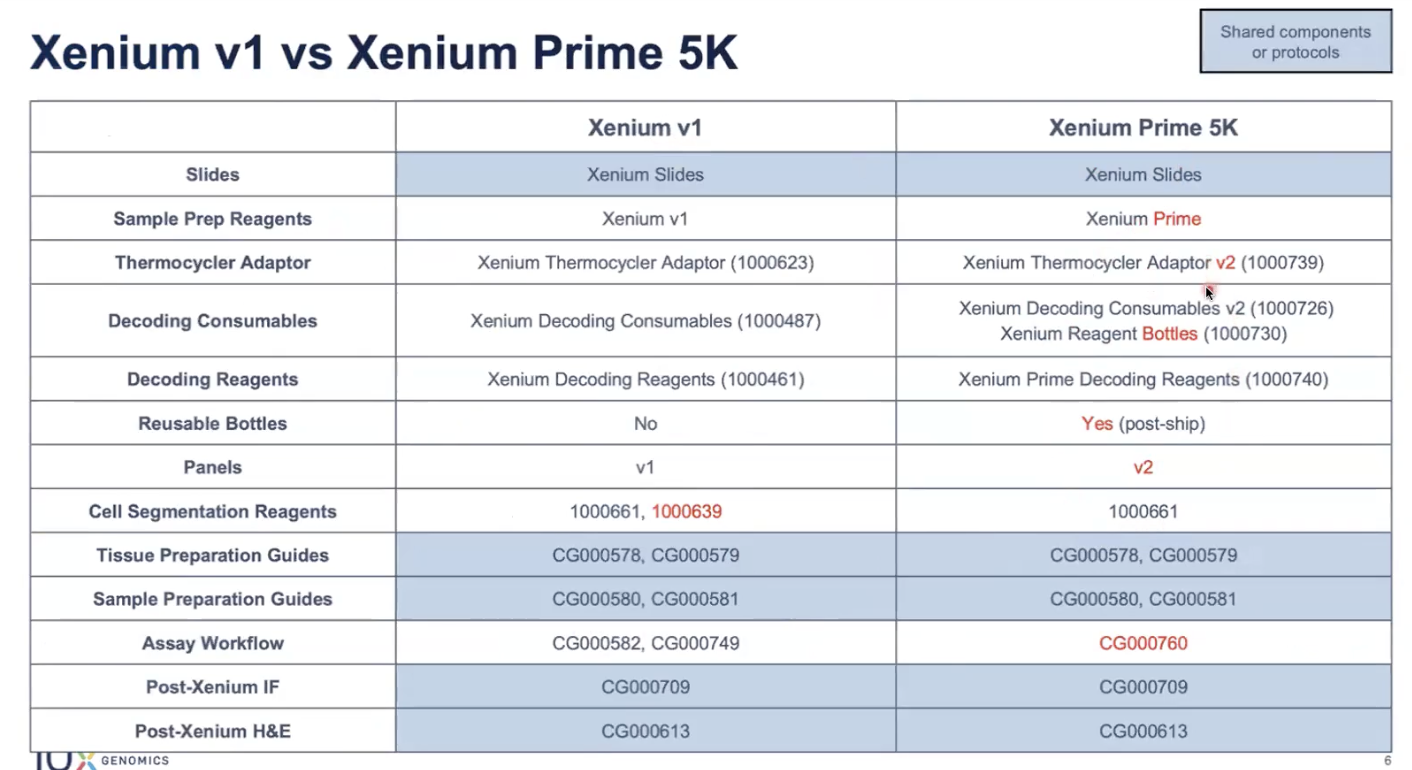
不同版本的Xenium实验需要不同的试剂
Xenium实验样本的QC要求

- 进行切片的DAPI染细胞核——查看细胞核的形态,细胞核的完整性和清晰度
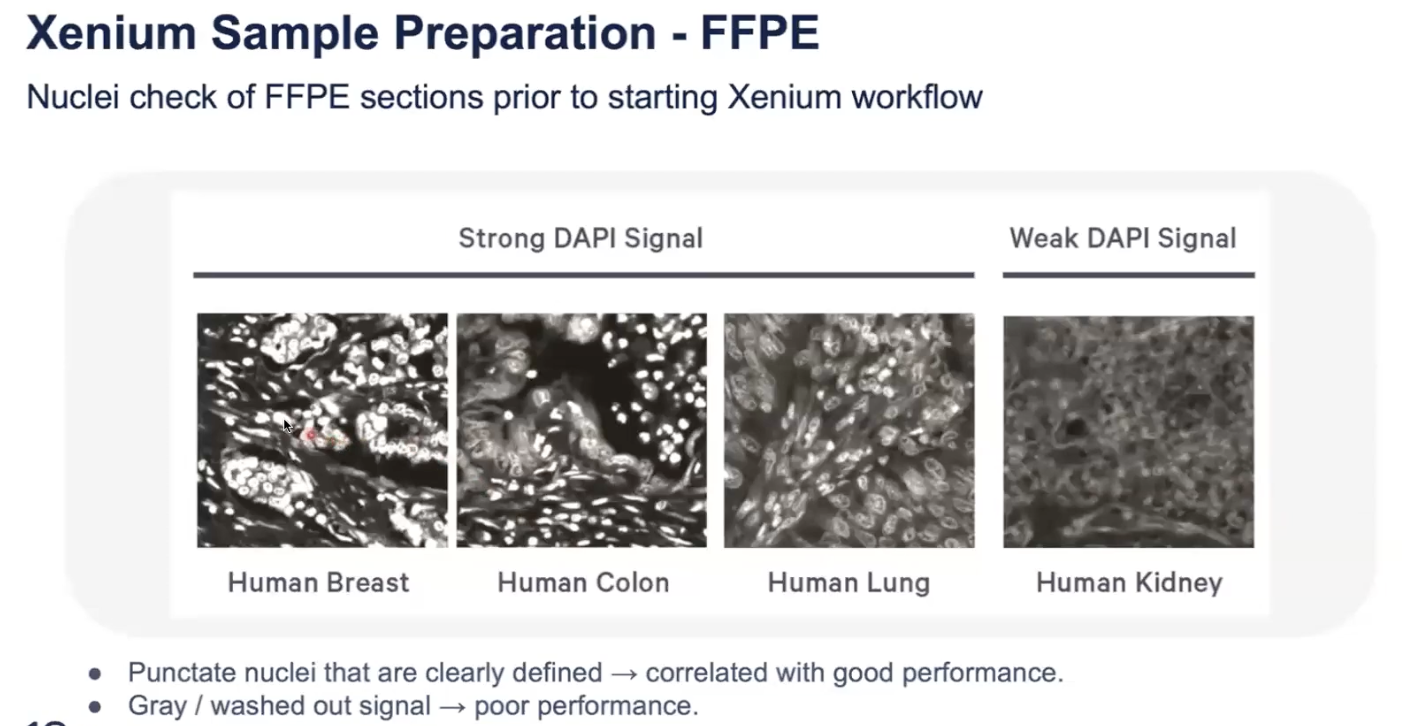
- HE染色和DV200(>30%)同前
- 如果是FF样本,可以把DV200换成RIN,去观察RNA的完整性,希望RIN>7(新鲜),或RIN>4(陈旧)
组织芯片 v.s. 组织微阵列
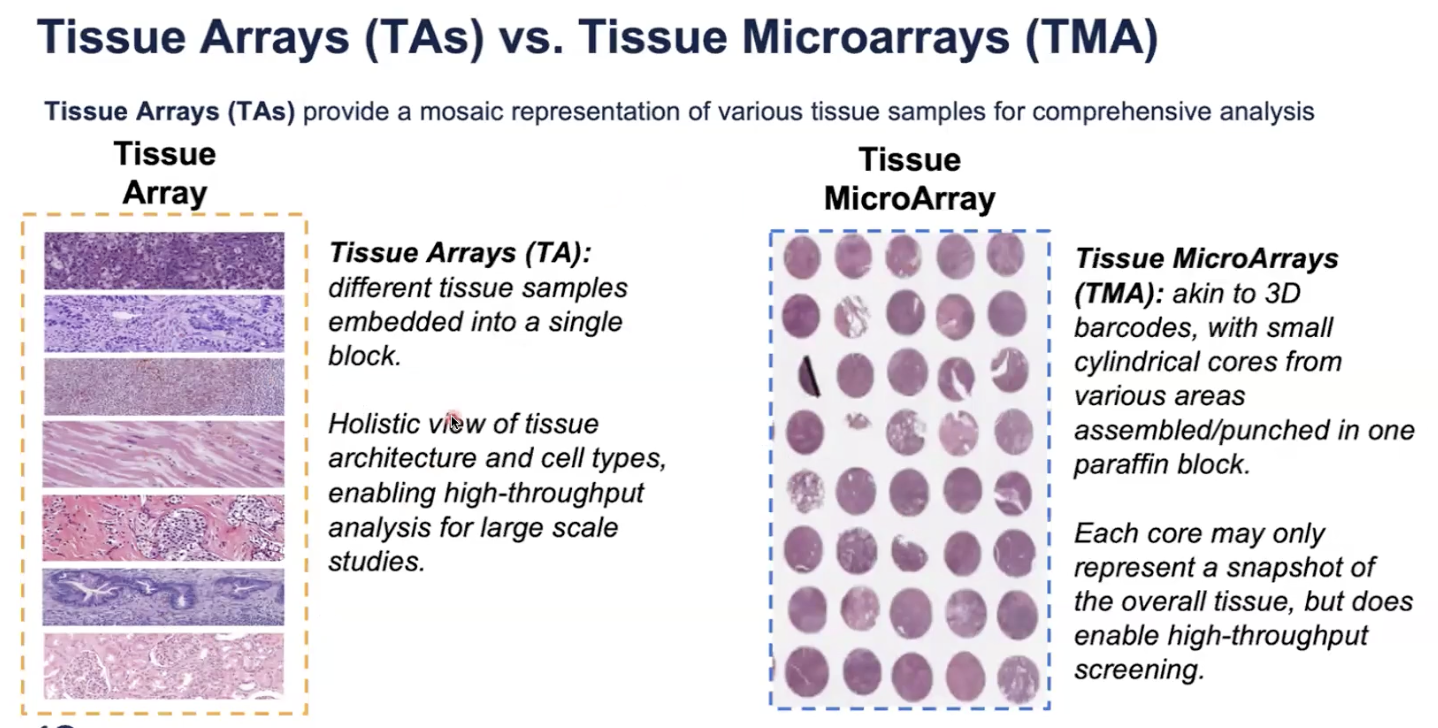
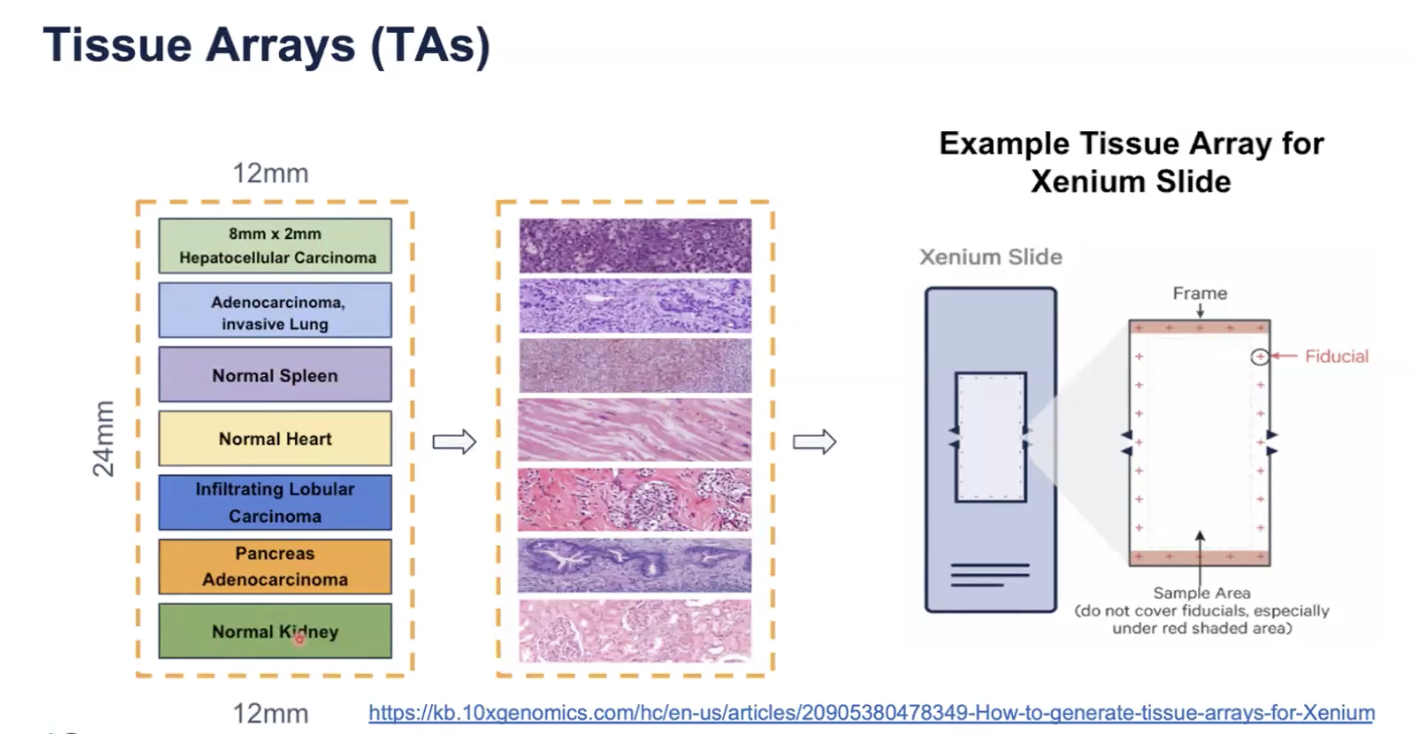
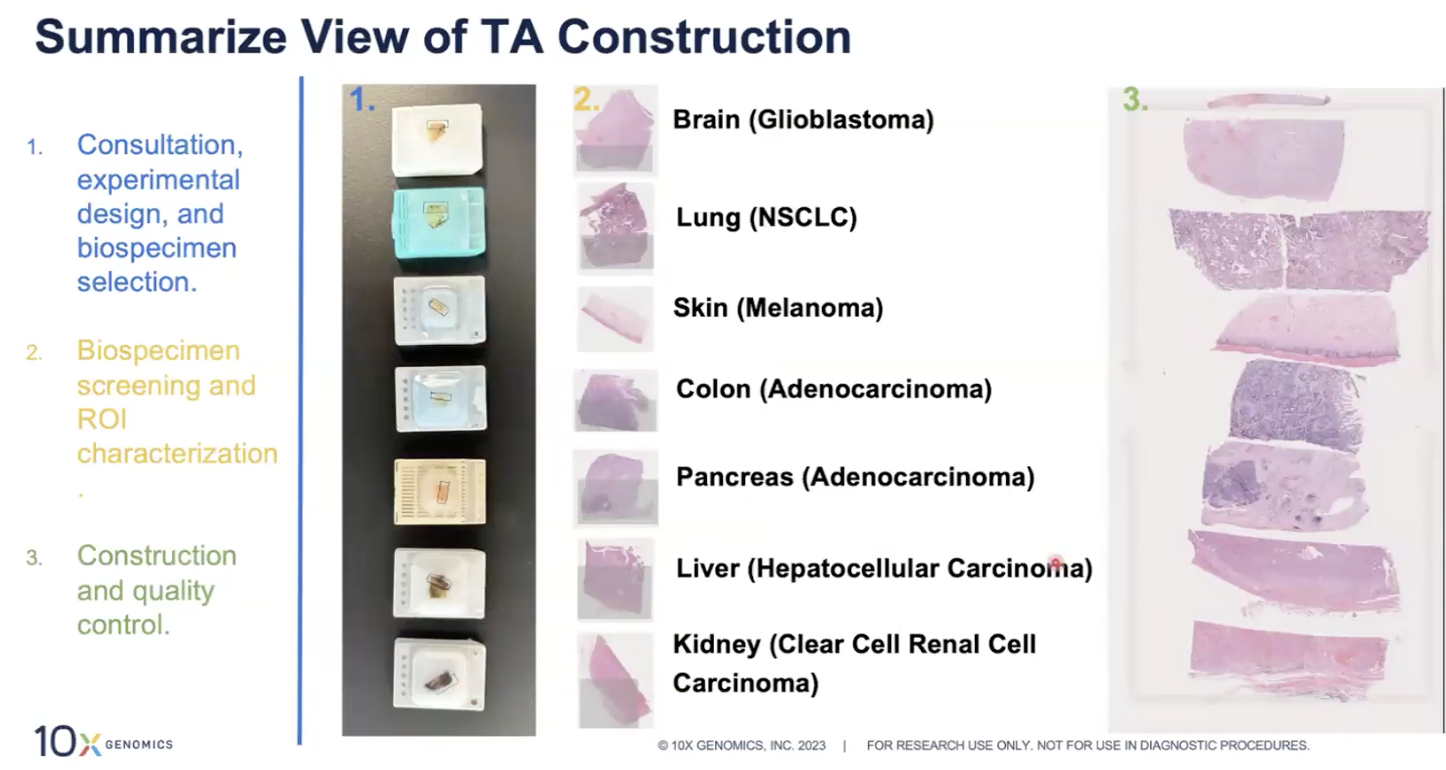
- 10x官网提供教程如何制备Tissue Array,另外Xenium也兼容传统的TMA样本进行分析
- 对于TA,需要每个样本都来自同一物种,也就是兼容同一panel,推荐每个tissue大小为2✖️8mm,这样一张玻片可以贴7片,贴片的时候要避开fiducial frame
选择与自定义panel
- 官网提供panel定制的教程和工具

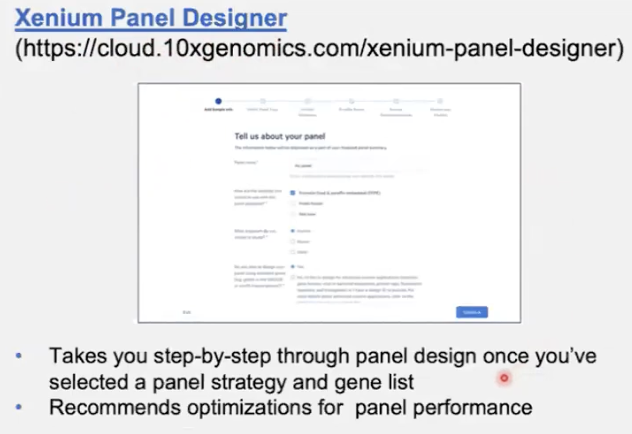
- 官网提供panel选择工具,输入自己感兴趣的基因就可以了
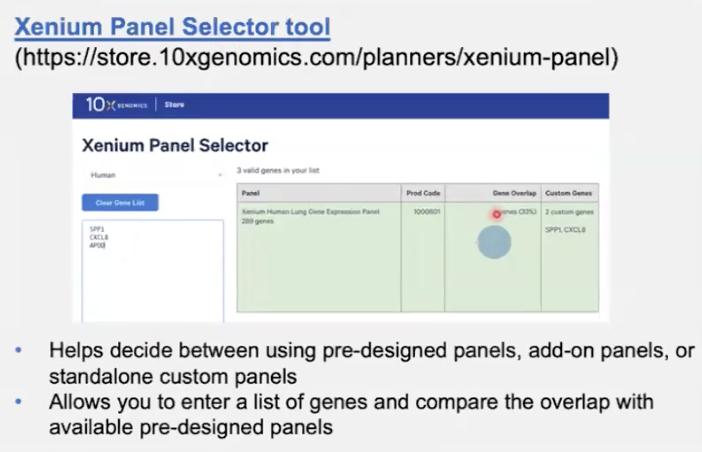
- Xenium Panel定制工具已经升级到了3.0的版本
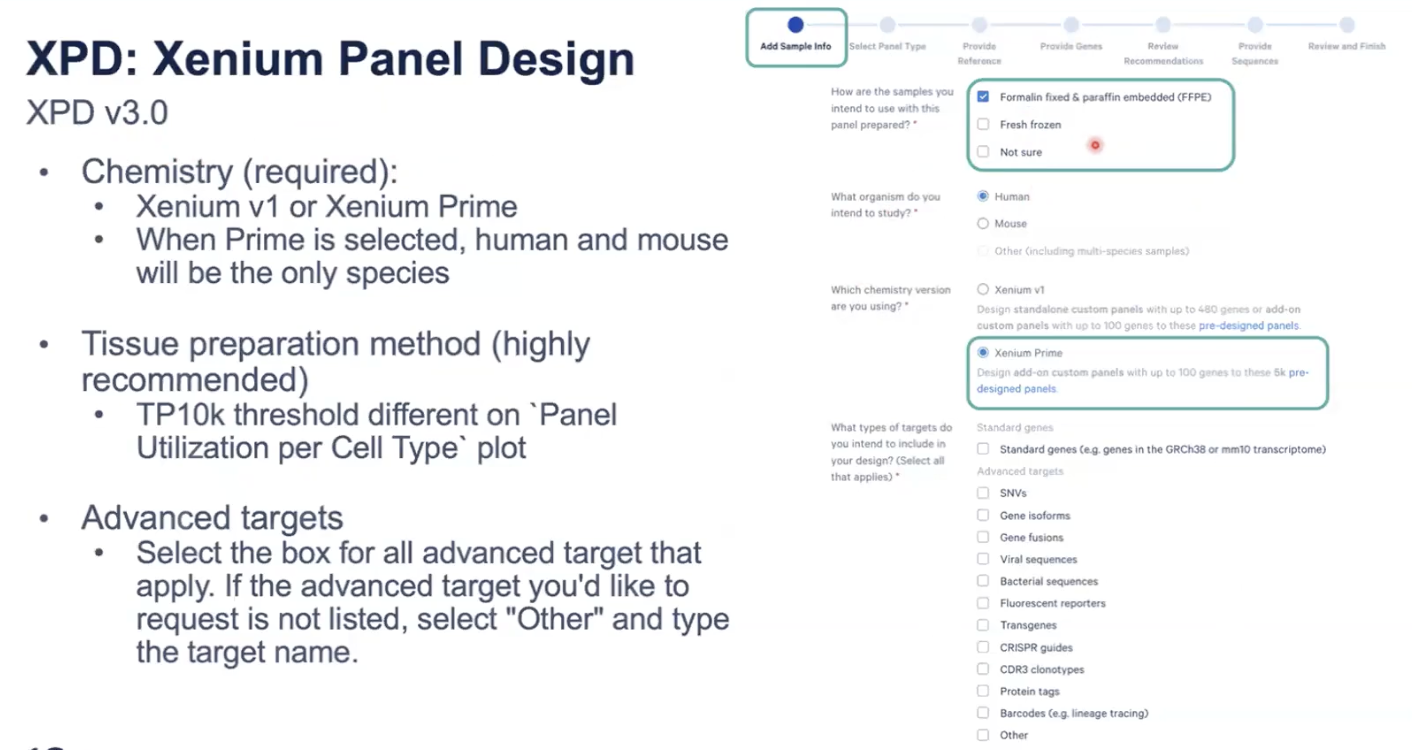
- 样本是FF还是FFPE很重要
- 5K的panel(Xenium Primer)上可以额外增加最多100个定制基因
- Xenium Primer只能兼容人和小鼠的样本定制,如果换用V1版本的试剂,就兼容其他的物种了
- standard gene可以在官网进行自定义,但是如果是其他的基因类型,就要进入高级定制
- 如果选择standard gene以外的内容,就要进入高级定制,需要用户先和销售进行商务合同的签订,然后和10x生信团队去与用户联系,进行高级的探针设计
Xenium数据分析要用到的软件

仪器中自带的分析软件
- 也就是Xenium Onboard Analysis(XOA)
- 运行完实验后就可以进行分析
Xenium Explorer
- 分析和可视化Onboard Analysis得到的数据
- Windows和MacOS上都可以运行
Xenium Ranger
- Linux系统
- 重新分析XOA得到的数据(比如细胞分割)
第三方工具

软件兼容性
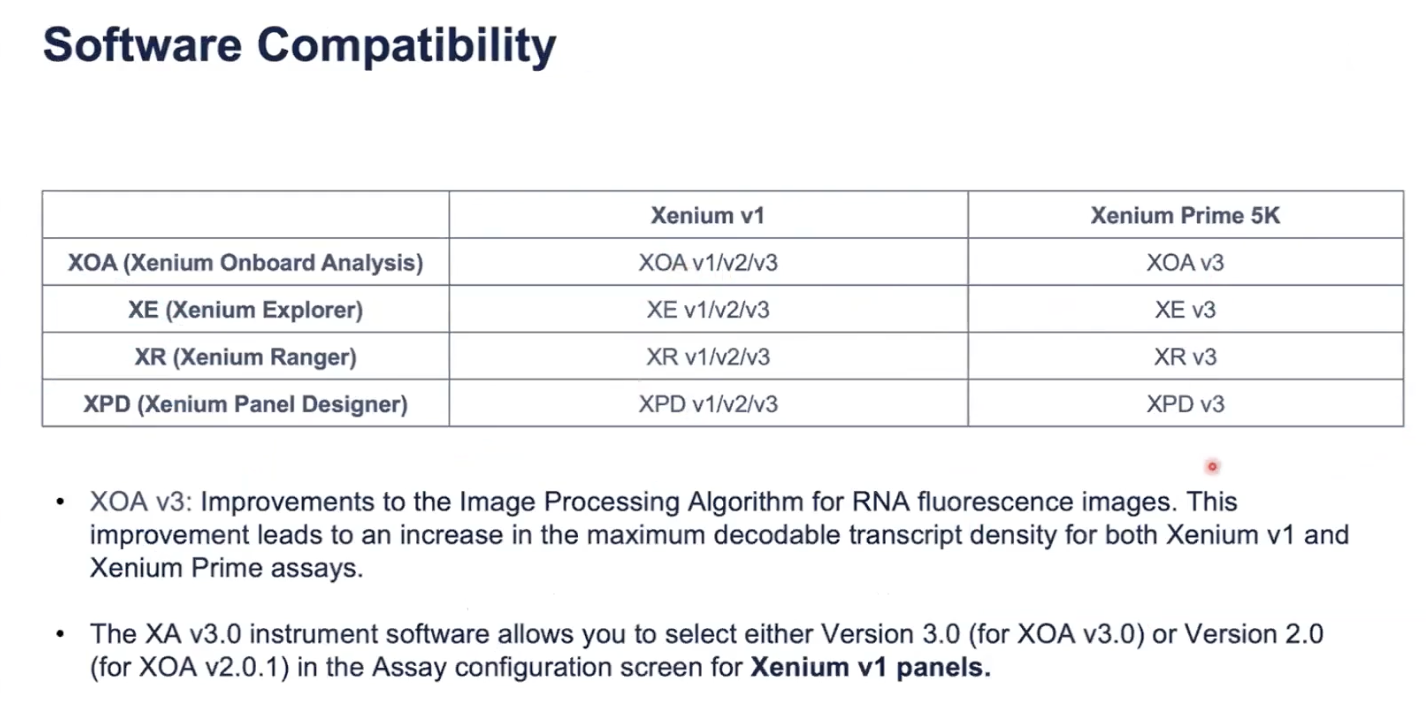
- 想做Primer的实验就一定要将实验室里的仪器软件升级到最新的版本,最新的版本仍然支持之前的V1的试剂
- 最新版本的实验更新了更好的成像算法,对转录本的荧光检出会更加有效,但是不用担心批次效应,因为最新版本的软件也支持之前的分析算法
第三方工具

- 新的细胞分割算法(basal,fictional)
- 空闲分析
示例:Xenium的5K淋巴结panel
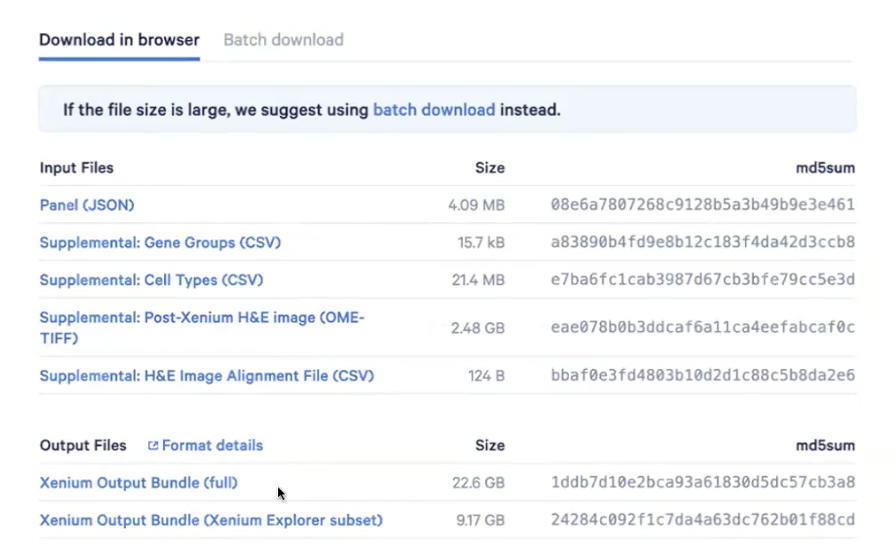
- 数据来源在这里
- 在这个panel中,使用的实际上只有4624个gene,在研发过程中设计的panel
- 可以下载Output文件,然后通过Xenium Explorer进行打开和可视化
- 可以点击View Summary来了解这个样本的质量控制数据
- Summary页的样本关键信息
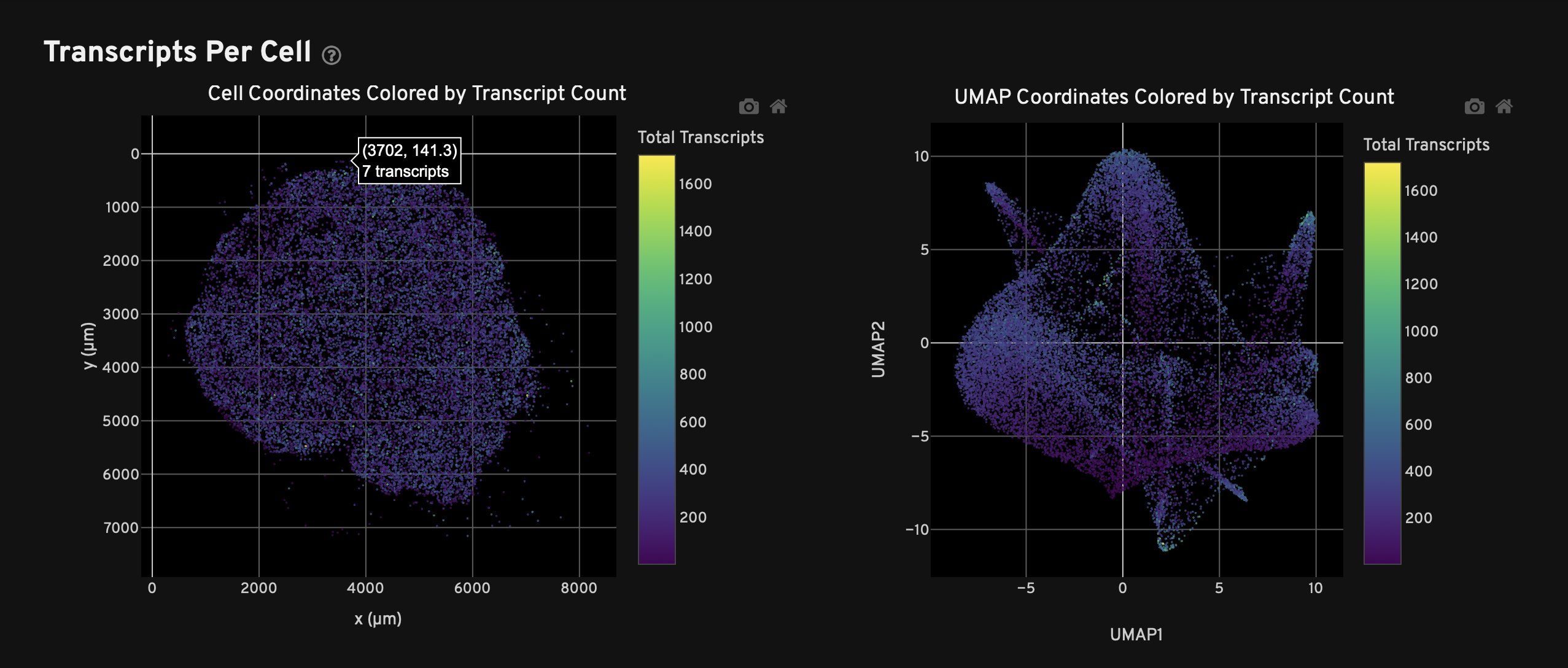
- 细胞数、中位转录本的数量,细胞核转录本的数量和总RNA检出数目
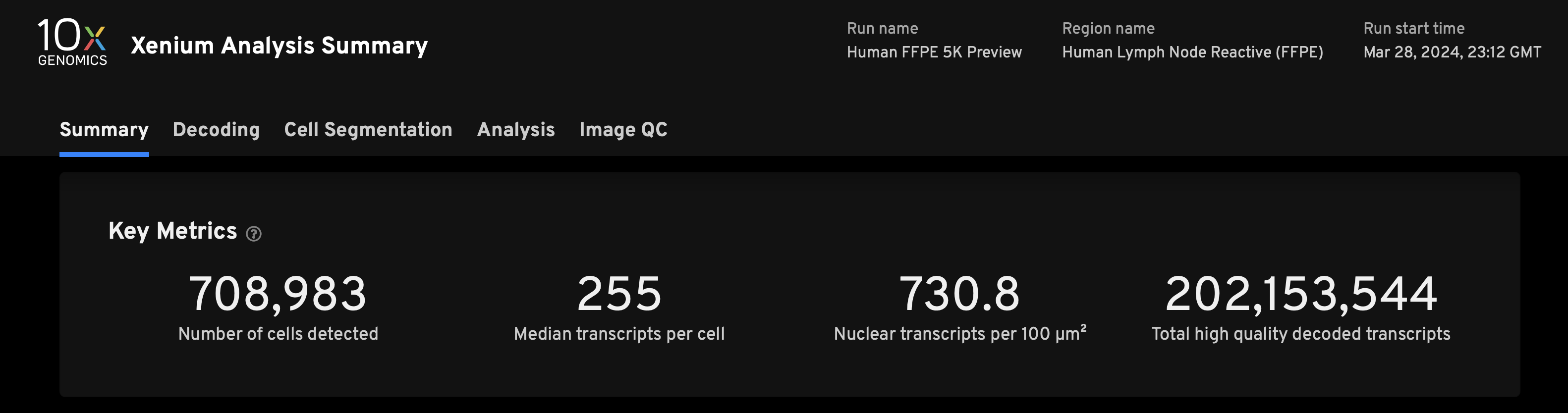
- 展示出的样本面积是整个样本面积的不到1/3,但已经获得了非常惊人的数量的细胞和转录本

- Decoding页面的关键信息:解码的转录本的信息
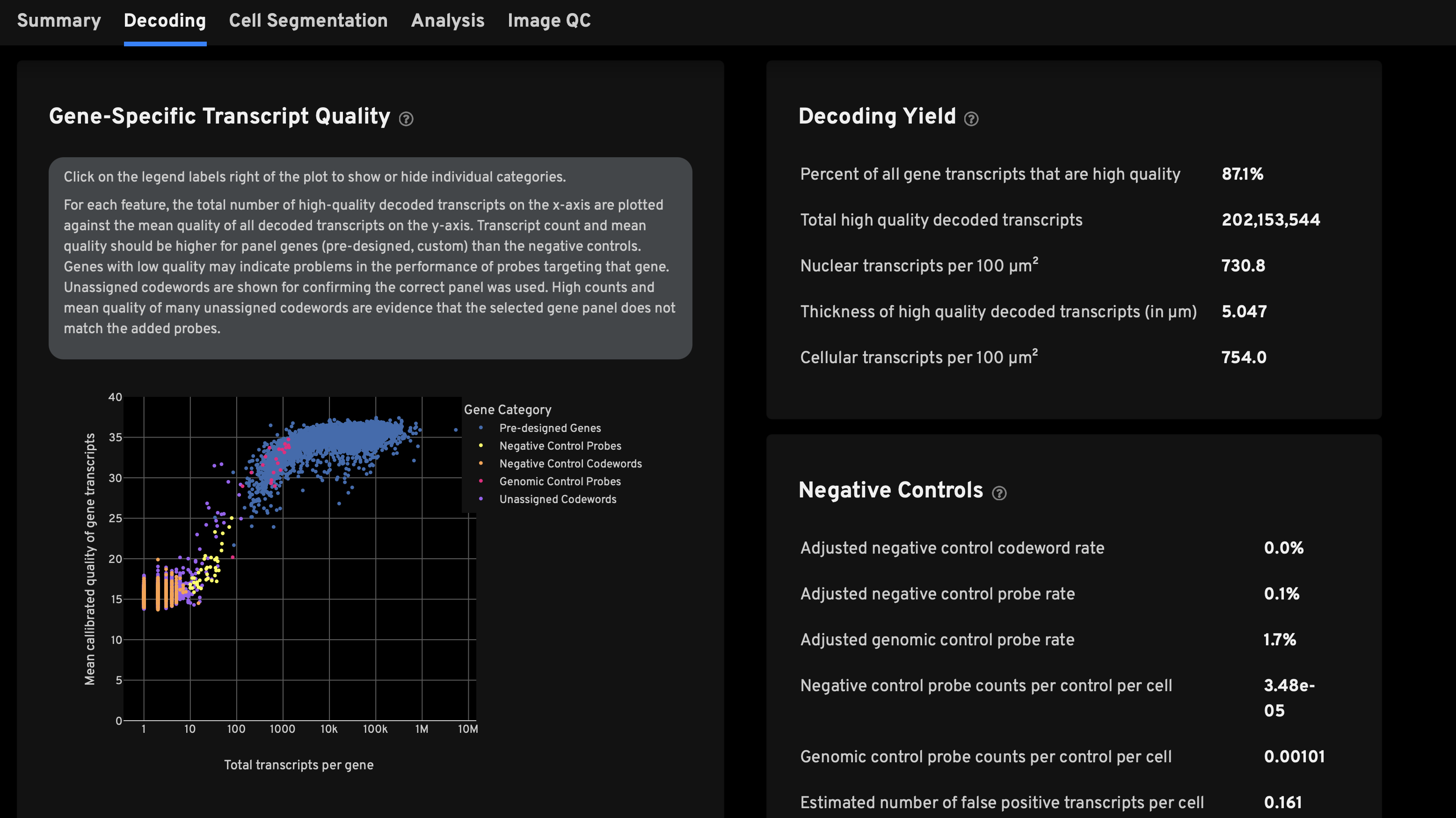
- 目标的基因的打分:越高越好
- 解码的转录本的数量等参数,对照的阴性基因越低越好
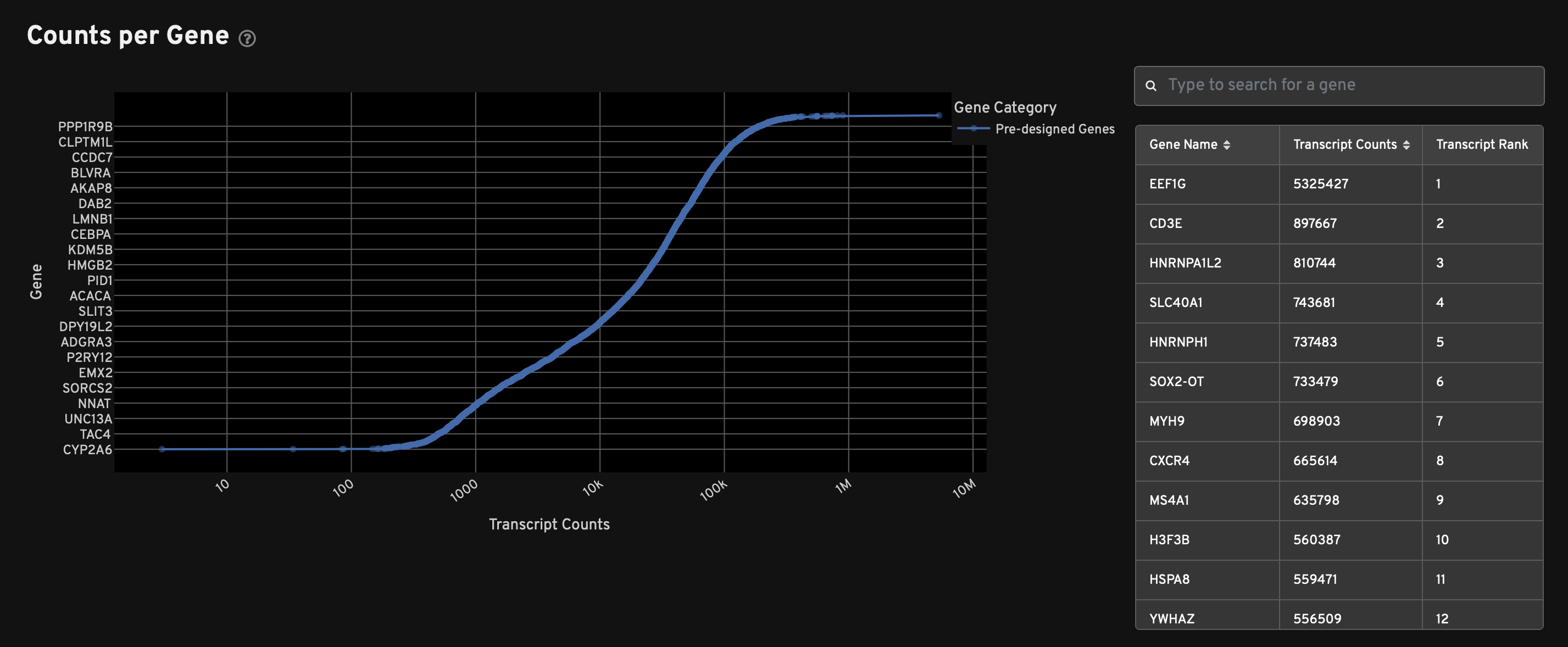
- 各个基因的名称和检出的转录本的数量(从高到低排列)
- Cell Segmentation页面
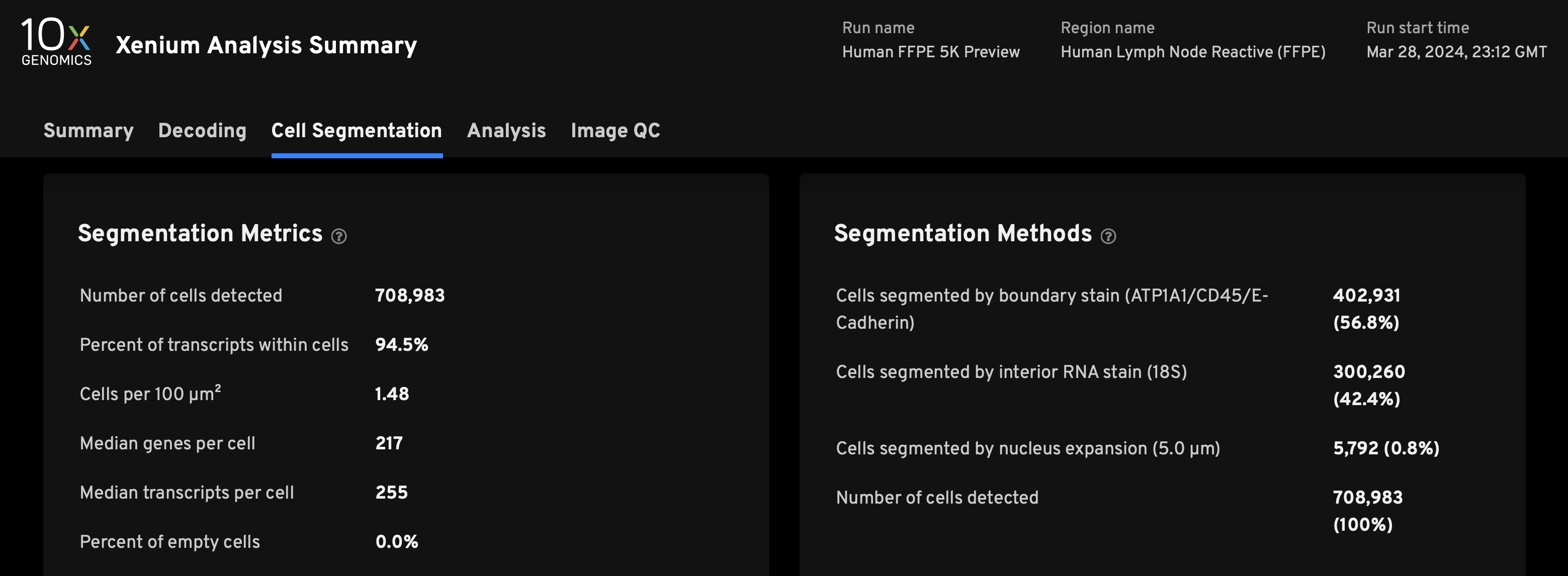
- 可以了解不同比例的分割channel分出的细胞的数量(希望DAPI核染外扩分出的细胞尽量小,因为不一定准)
- 94.5%的转录本都在已经识别的分割的细胞内部
- 统计图:细胞尺寸、细胞基因数和细胞转录本数
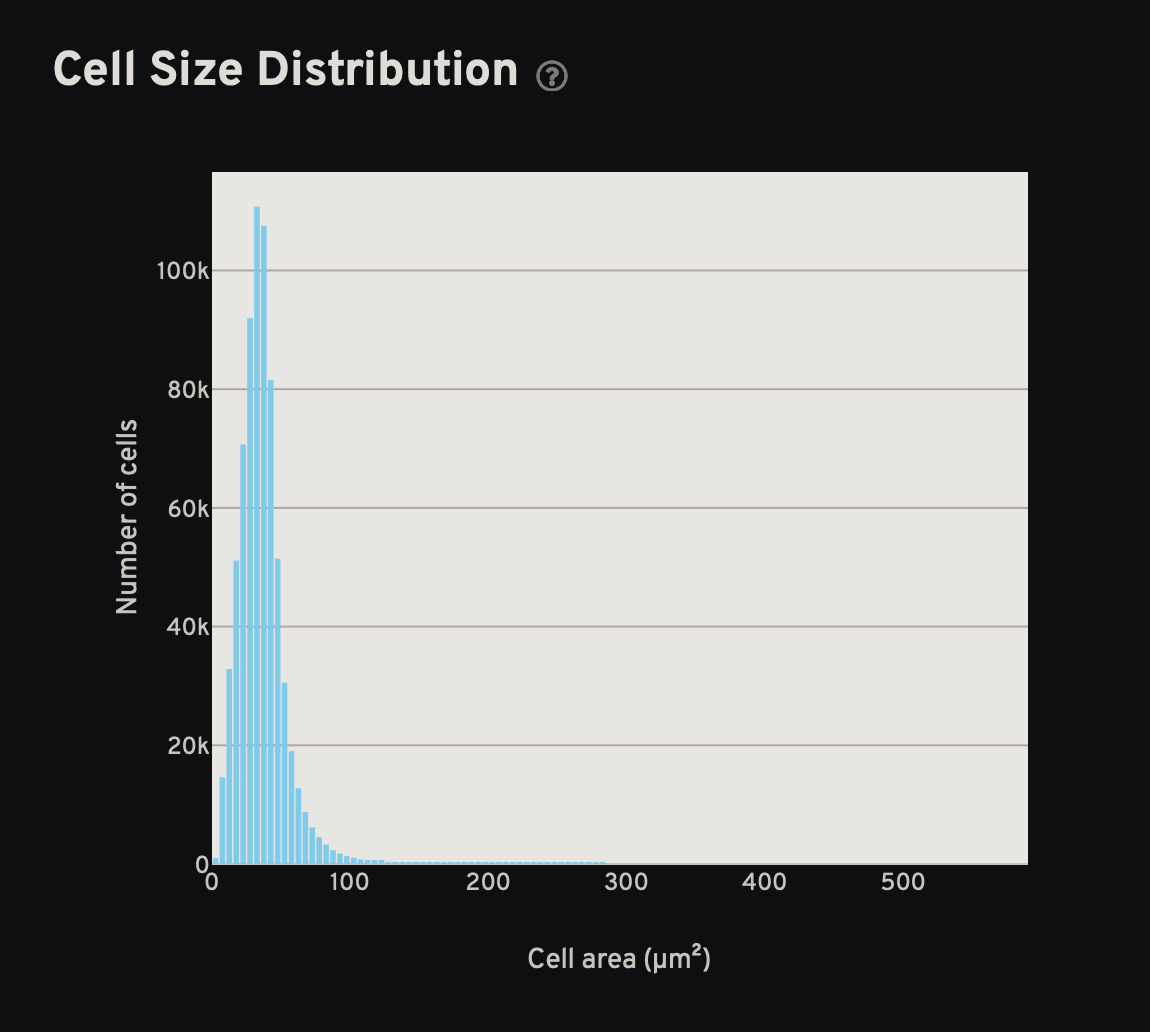
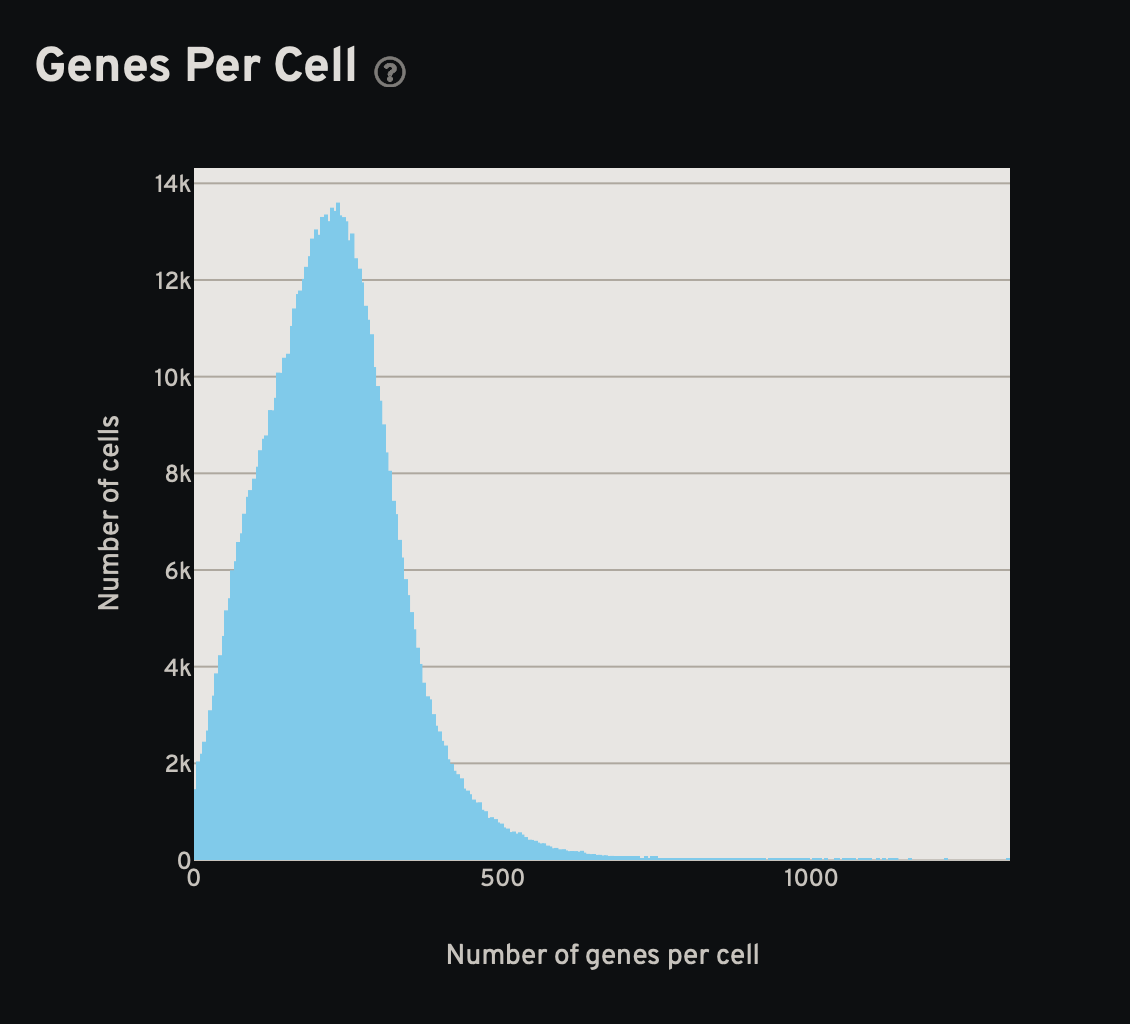
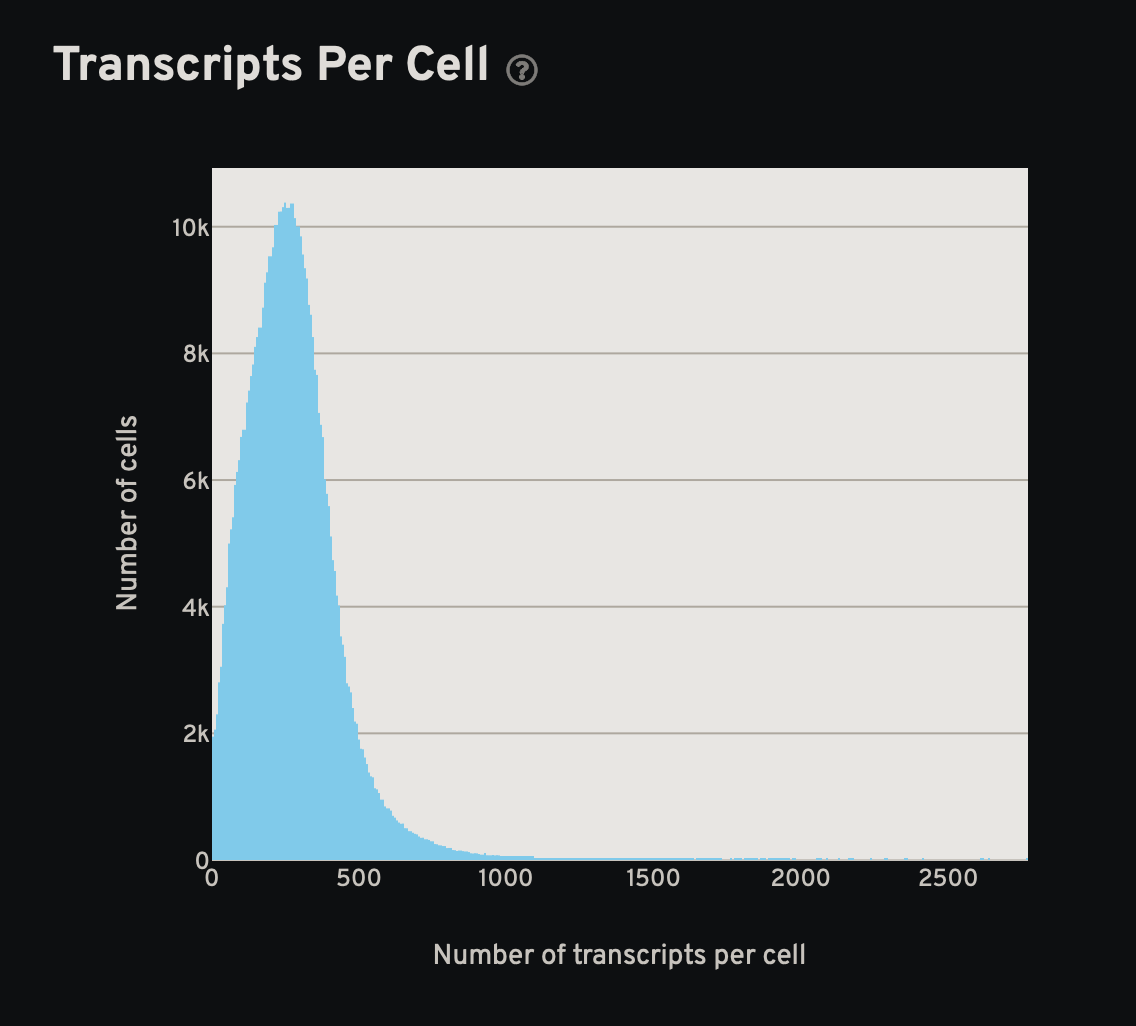
- 分析页面的结果
- Image QC页面
- 可以把我们下载的文件通过Xenium Explorer打开,放大后可以发现是多模式(不局限于DAPI核染)的结果
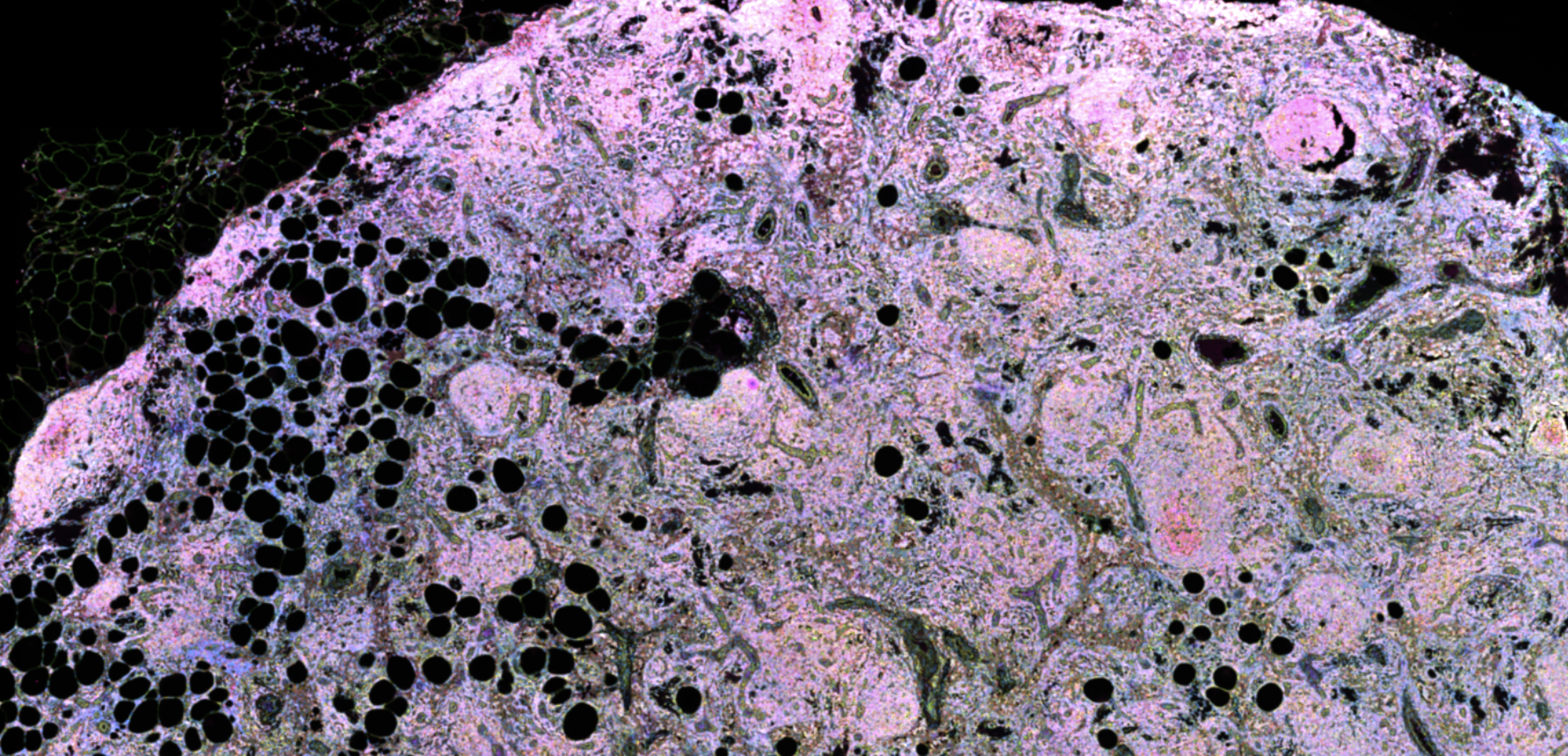
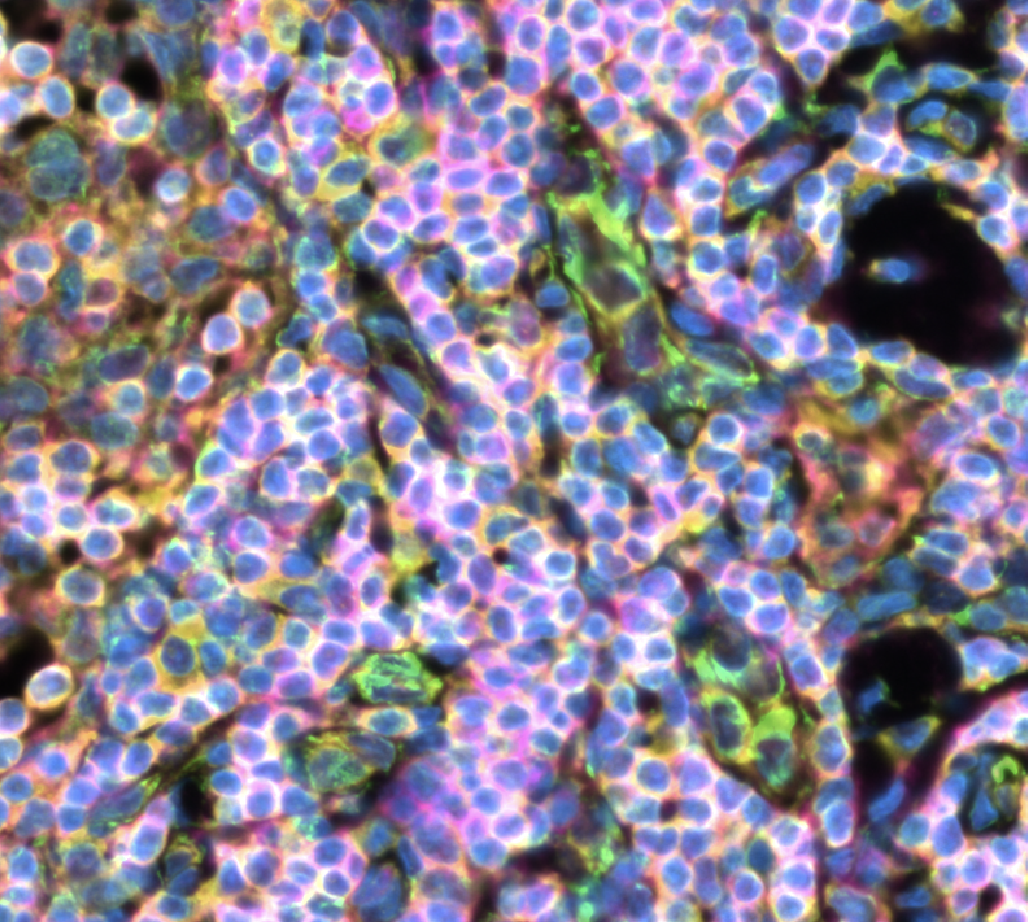
- 软件可以叠加HE染色或免疫荧光的结果,在图片第一次导入的时候,要自己进行对齐alignment,在对齐后Xenium会生成文件,供后续记录对齐结果使用
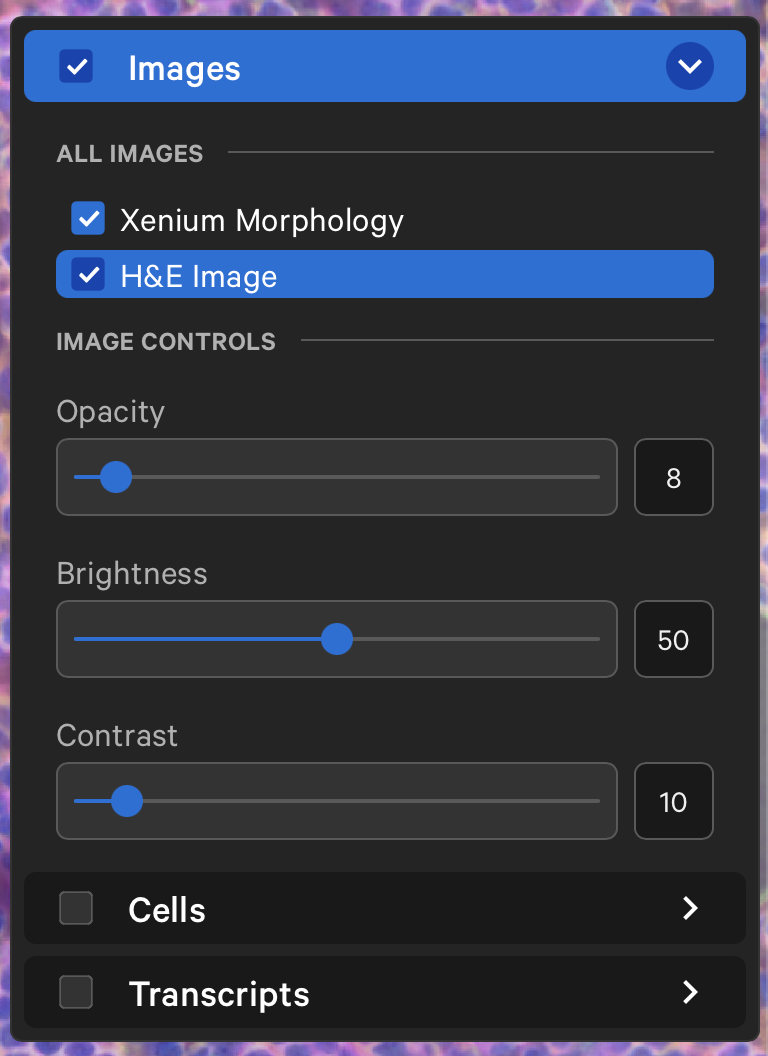
- 我们可以调整HE图片的透明度
- 对于cell页面,我们可以观察到细胞分割的情况

- 也可以结合Images选项的Xenium形态学和HE染色结果去查看
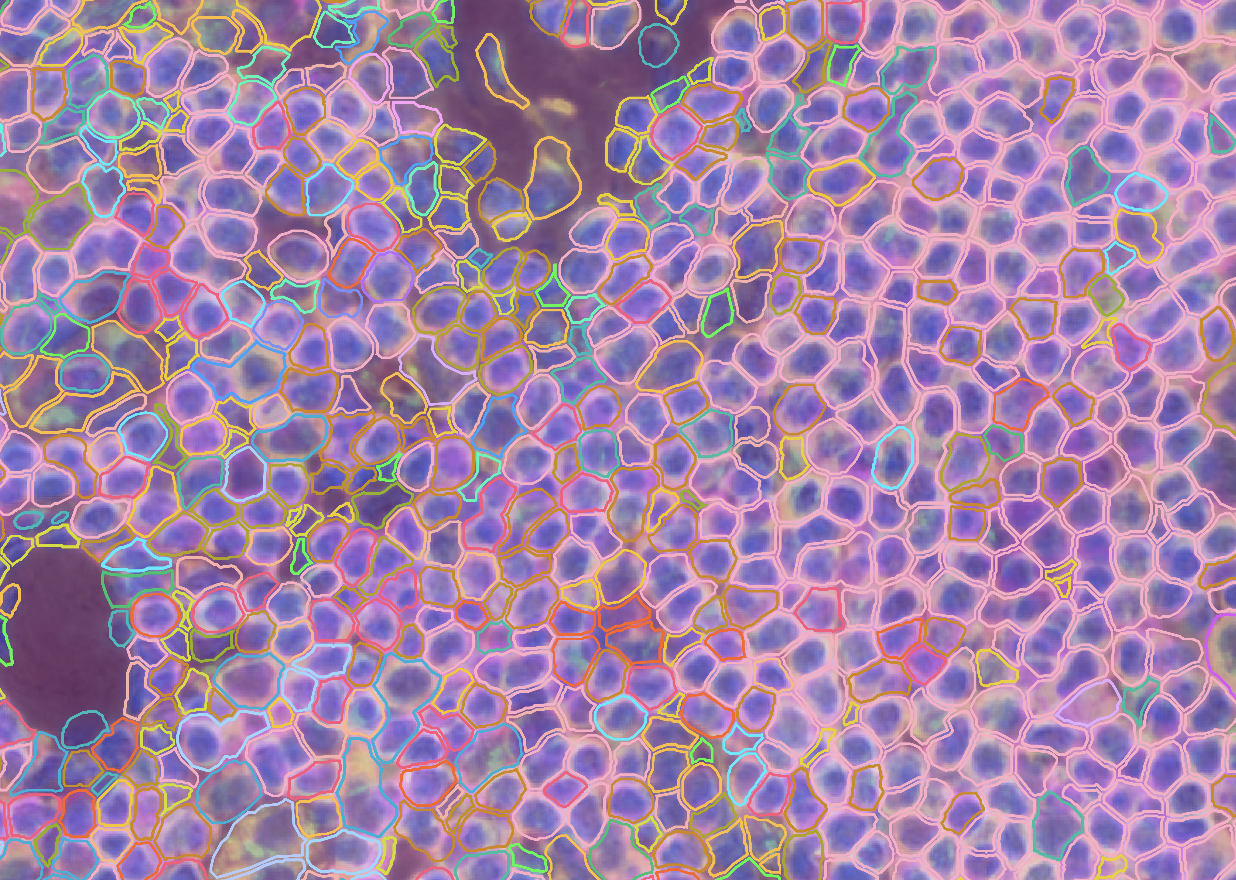
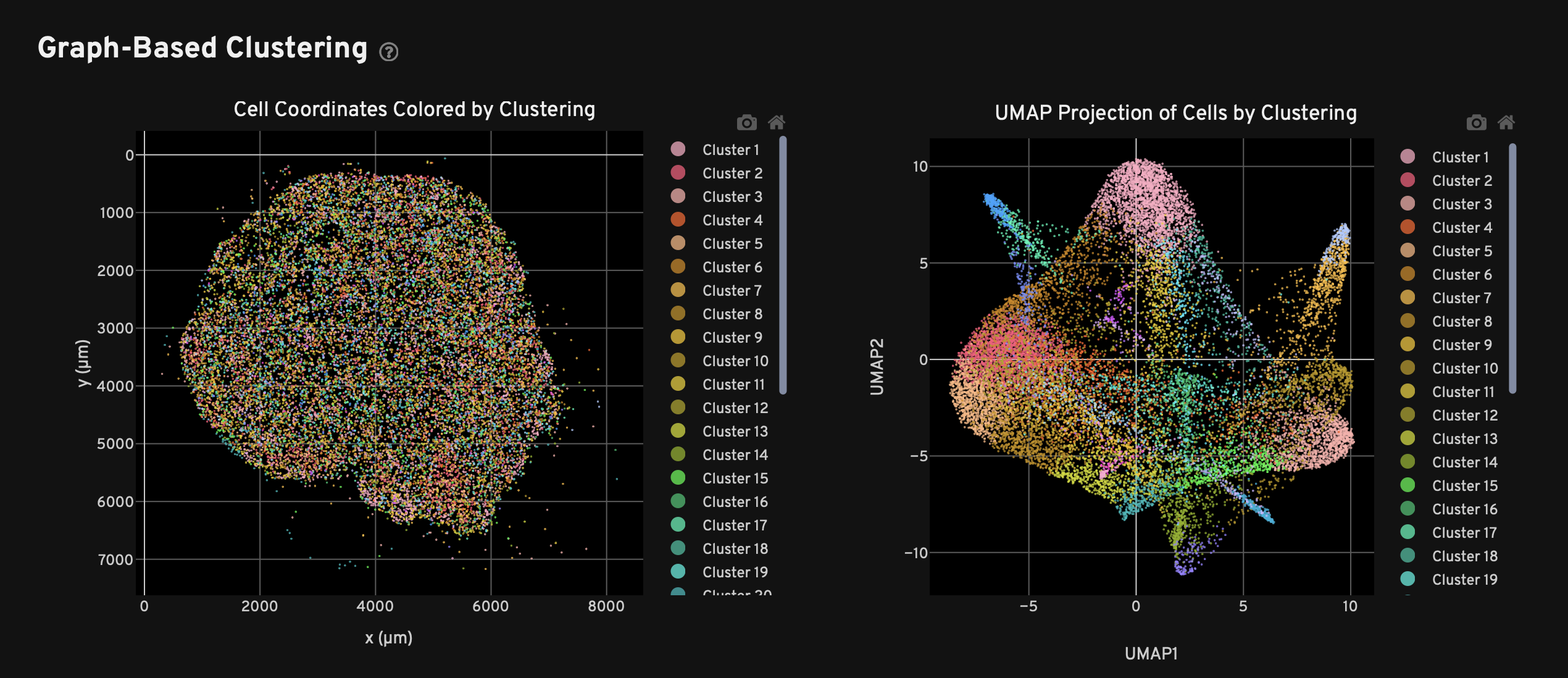
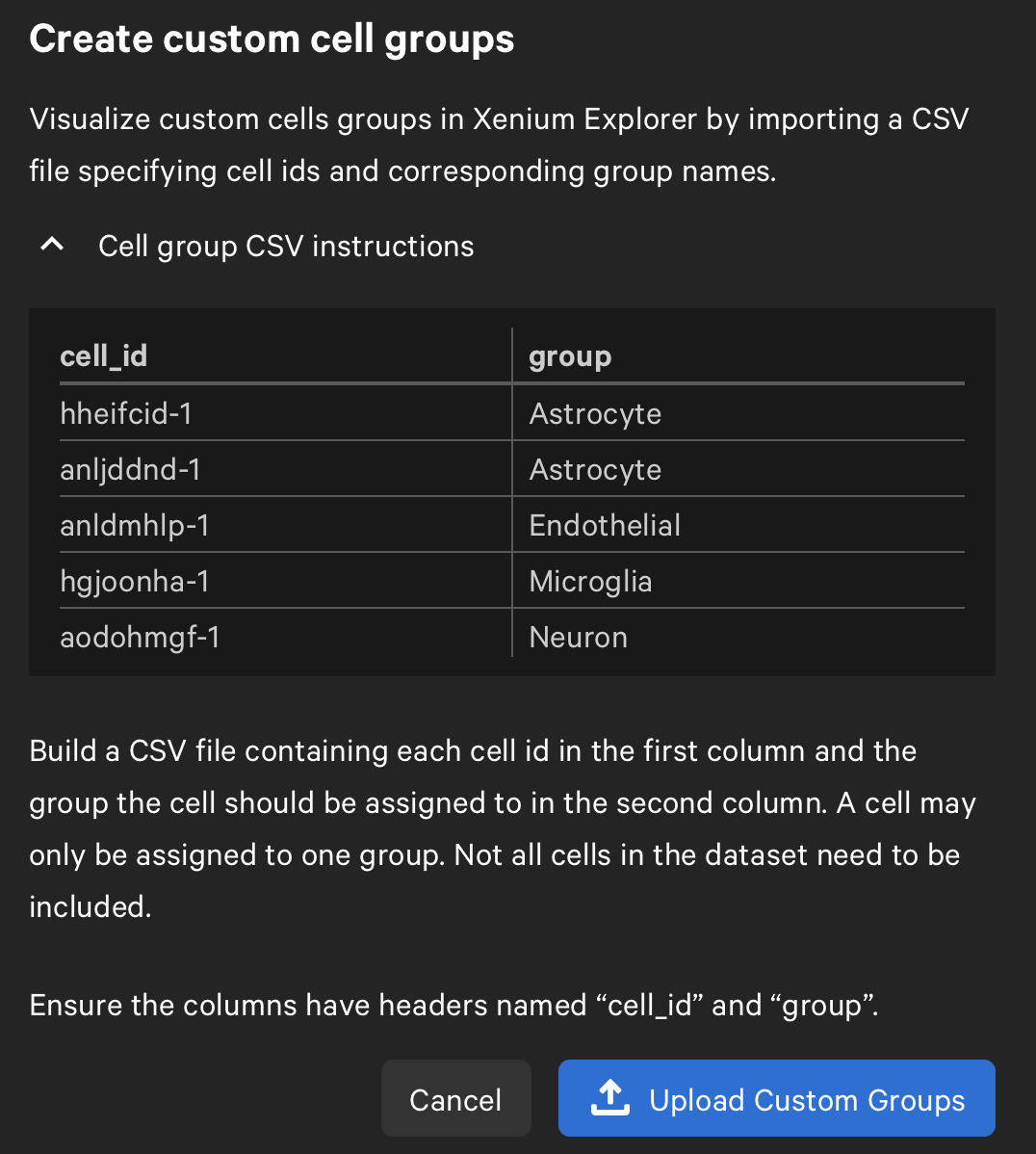
- 我们也可以查看细胞核的边界,并对这些细胞进行Graph-Based Clustering和K-Means Clustering,其中K值同样从2-10,注意这样的clustering出来的结果是没有cell type的,我们可以通过第三方的工具注释了细胞后,产生对应的csv文件(要求见下图1),然后在groups旁边上传对应的csv文件以实现注释,这里展示上传后的结果如图2
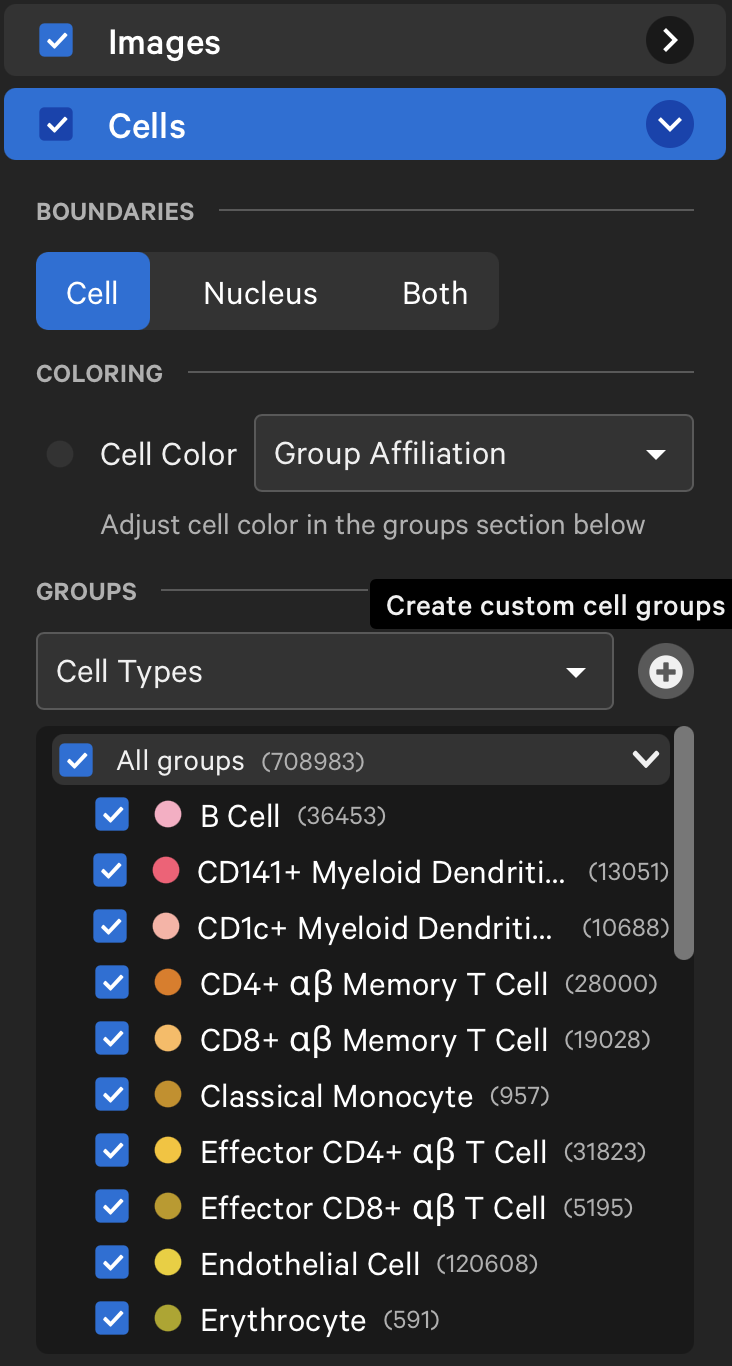
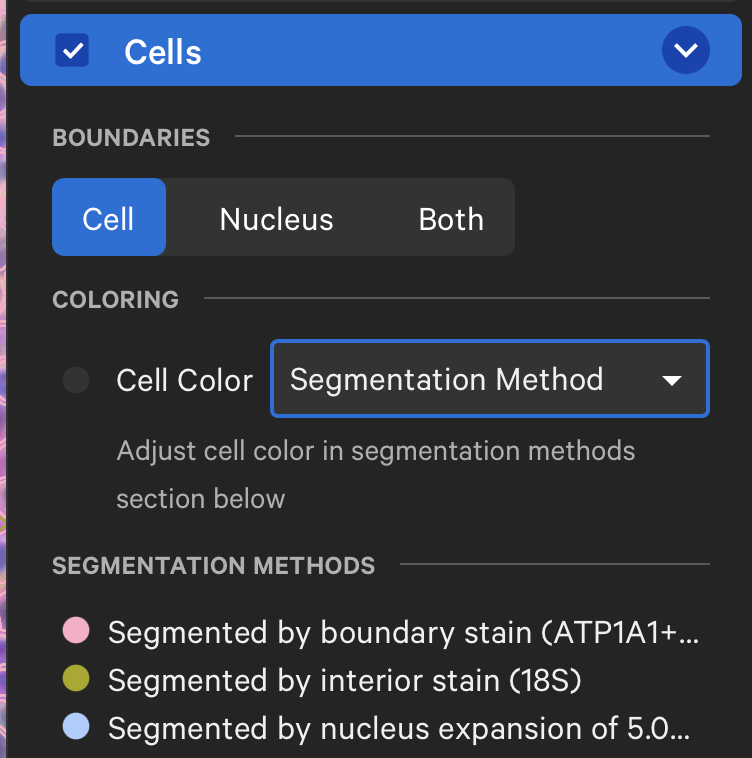
- 我们还可以在Cell部分去探索细胞被分割出的方式,我们希望基于DAPI的分割越少越好
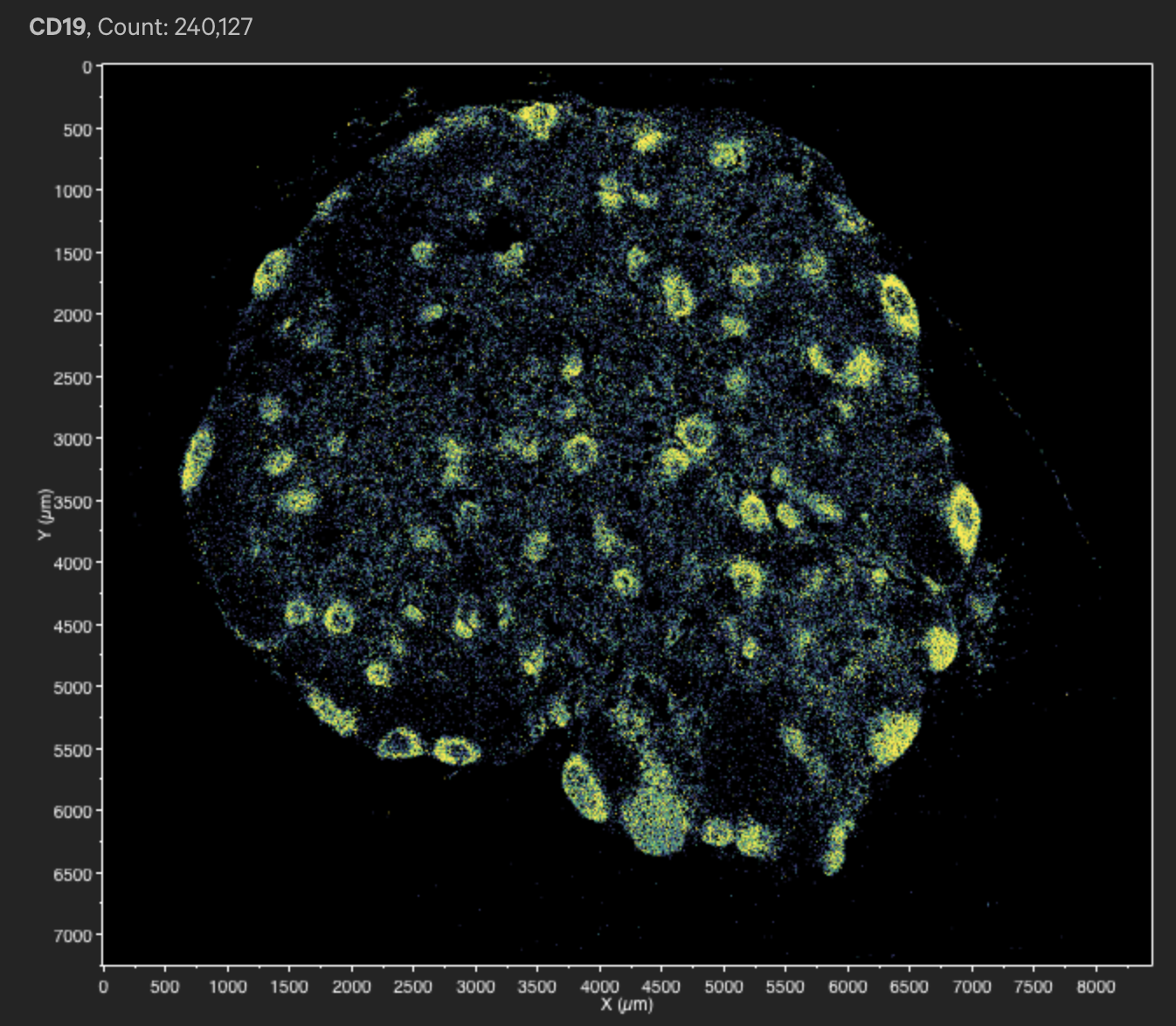
- 对于转录本,我们可以探索不同的转录本在不同的细胞中的表达情况,也可以探索某一类细胞的marker gene在空间上的分布(比如下图)
- 我们还可以上传自定义的csv文件,将不同的gene划分到细胞种类的group中,去用更加直观的方式预览基因的表达情况

- 可以使用正上方的套索工具来选择感兴趣的区域,选择后Xenium系统会自动输出区域的信息,包括我们勾选的转录本的数量,细胞数量和种类,丰度等