


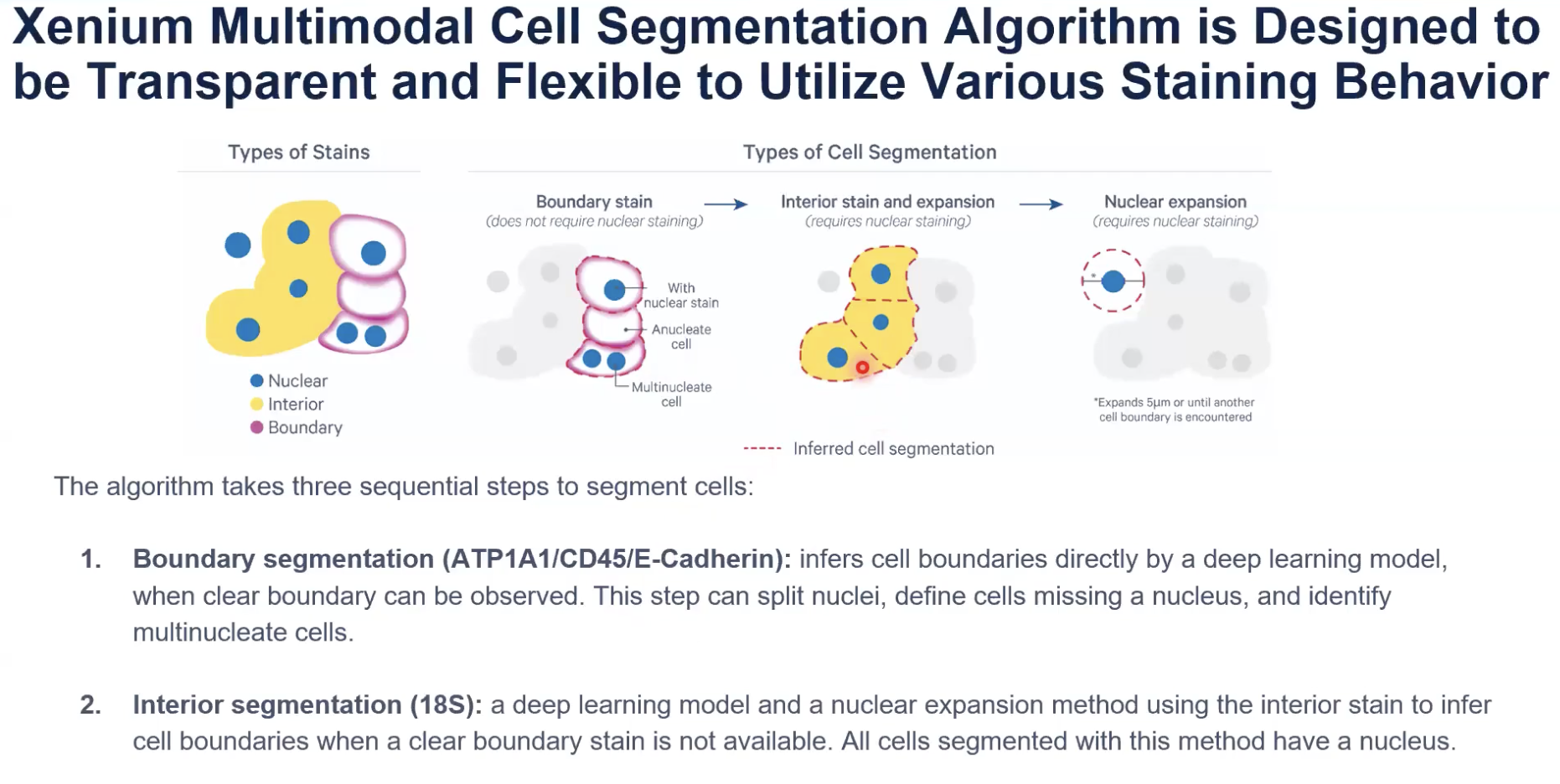
- 正如各位老师知道的那样,准确的细胞分割对于准确的将转录组分配到细胞中至关重要。在今年上半年的时候,10x Xenium多模态细胞分割的产品。在这个产品中,10x使用了7种相互补充的细胞marker,10x将7种细胞marker分配到4个不同的channel中,如下图所示
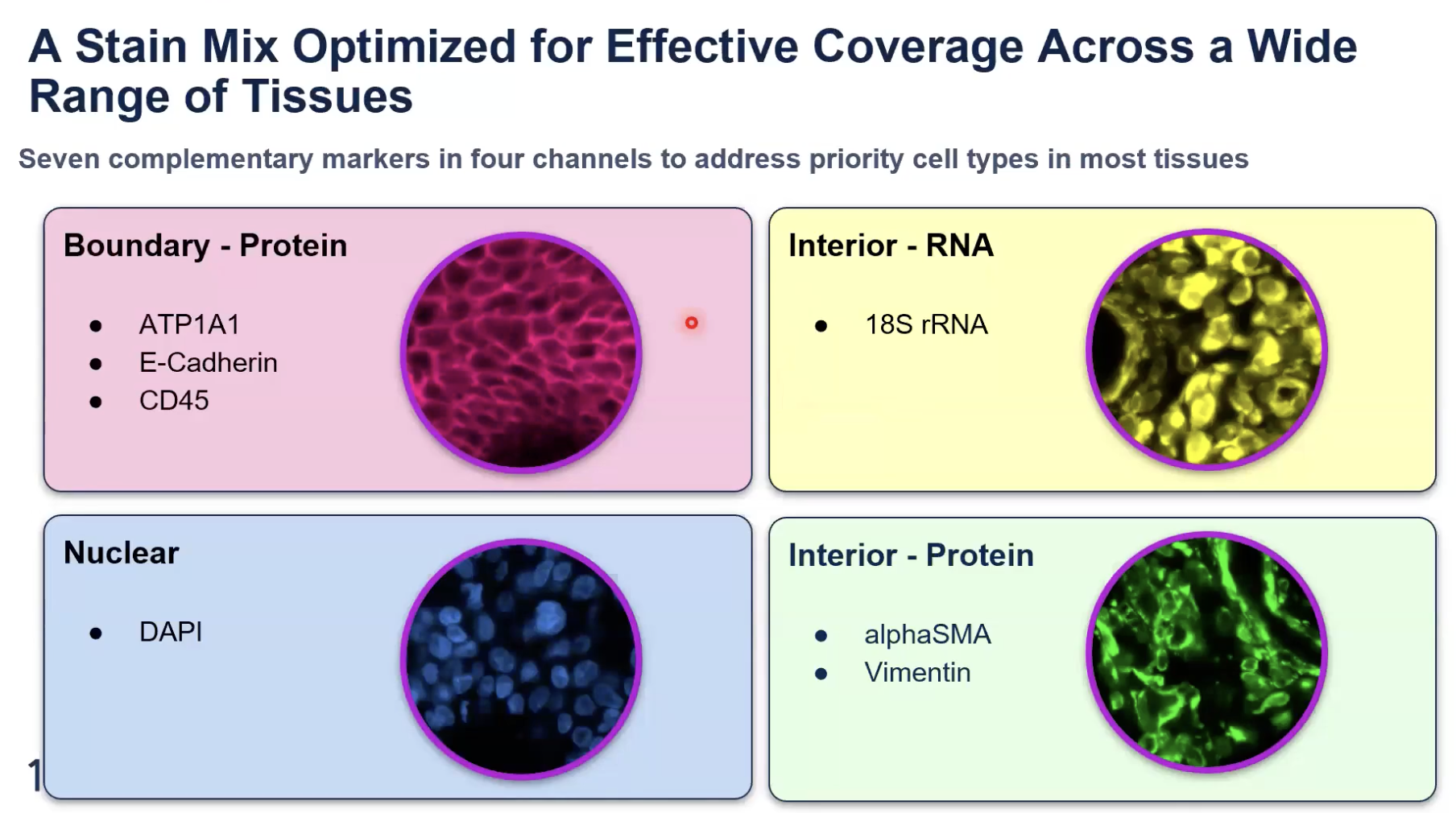
- 在这些细胞marker中,10x选去了标记细胞边界和细胞内部的marker,这些marker的区别将是10x今天讨论的重点话题。
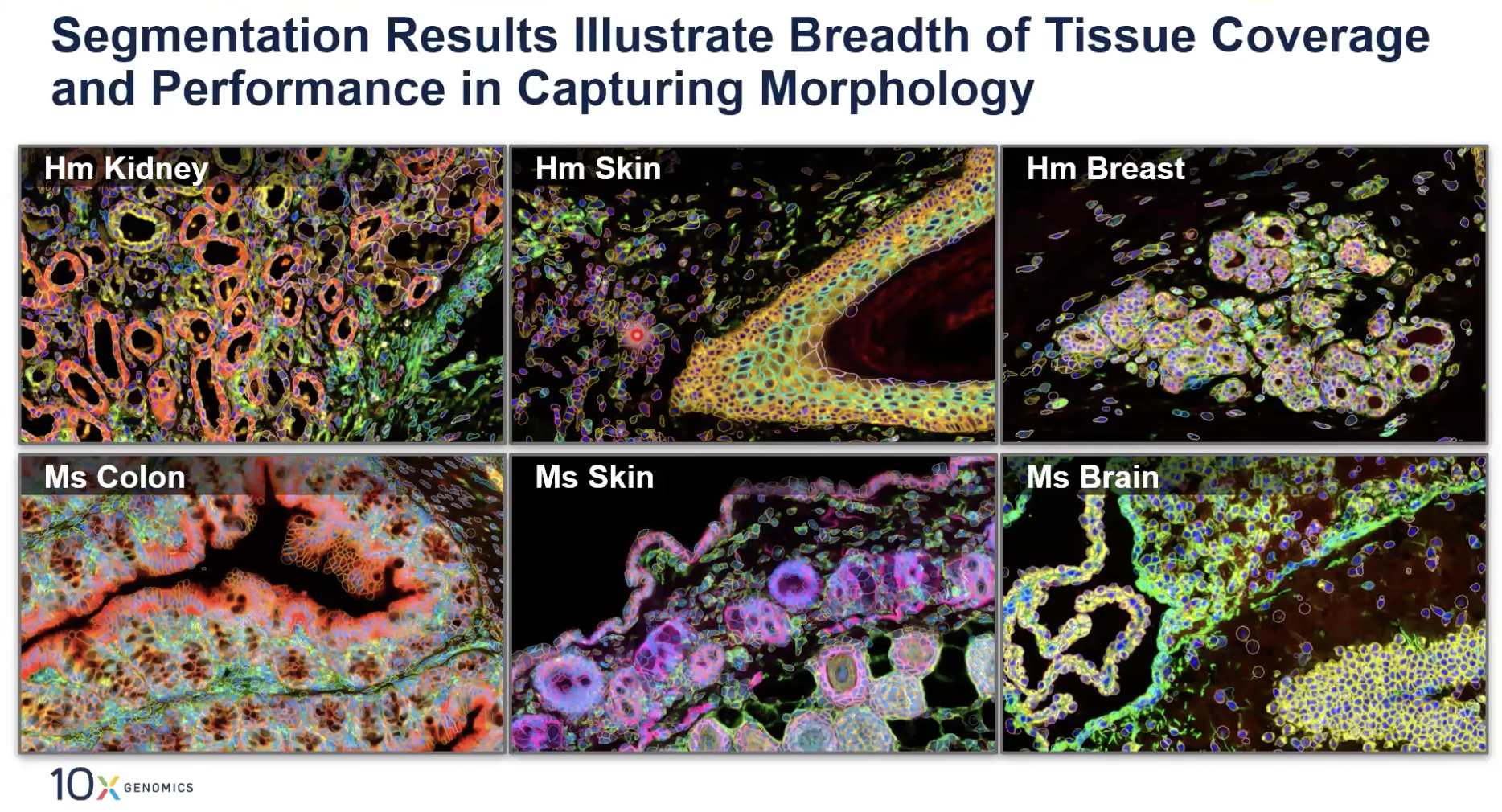
- 上图是几个几个比较简单的例子,展示了Xenium多模态细胞分割产品对多种细胞组织和多种细胞类型都有良好的支持。上图这些像荧光显微镜一样的彩色图片,就是10x在4个channel中使用的多种的细胞marker。图中的边界是10x算法所产生出的细胞分割的边界。下面的内容会详细介绍10x的算法是如何得出这些细胞边界的。
传统算法与局限性
- 首先介绍传统的算法,如下图所示
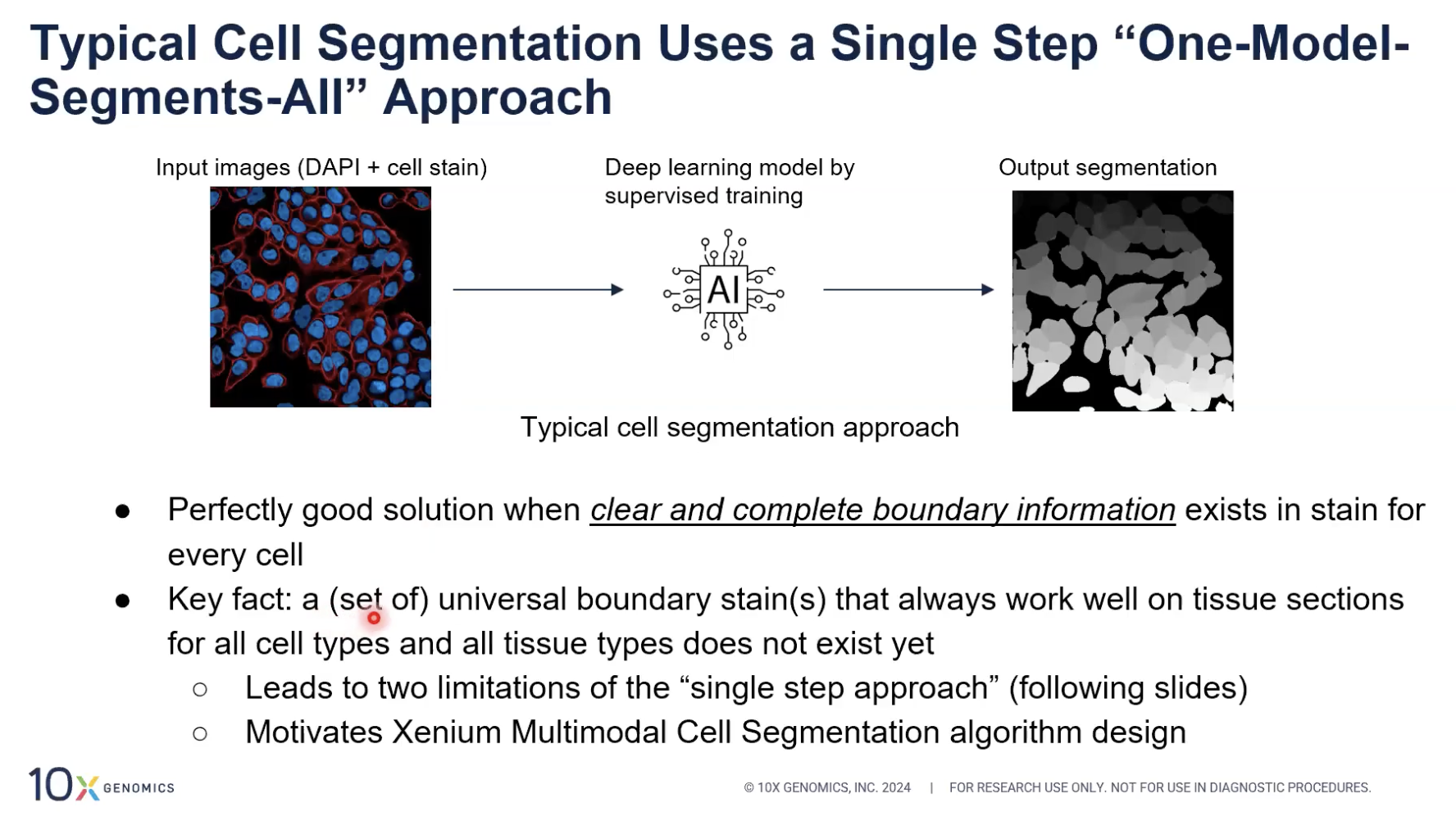
- 在近些年来常见的细胞分割方法中,最常见的方法就是所谓“一步到位的模型+分割所有细胞”的方法。这种方法主要运用全监督学习训练出的深度学习模型。一张细胞的图片会被输入这个模型。一般来说,输入的图片会包含两个channel,分别是DAPI,也就是细胞核channel,另一个channel是细胞marker的图片,之后模型会直接输出这张图片中所有细胞的细胞边界。
- 当这张图片中所有细胞的清晰边界都可以被看到的时候,这个方法是没有任何问题的。换句话说,这种方法的设计要求就包含了在这张图片中,所有细胞的清晰的边界都有出现。
- 但是,在现实中,能够完美地标记出所有样品组织中的所有细胞类型的marker是不存在的,这就导致了这种一步到位的这种模型去分割全部细胞的方法,有两个非常重要的局限性。
局限性1:传统算法对于没有清晰边界的细胞表现差
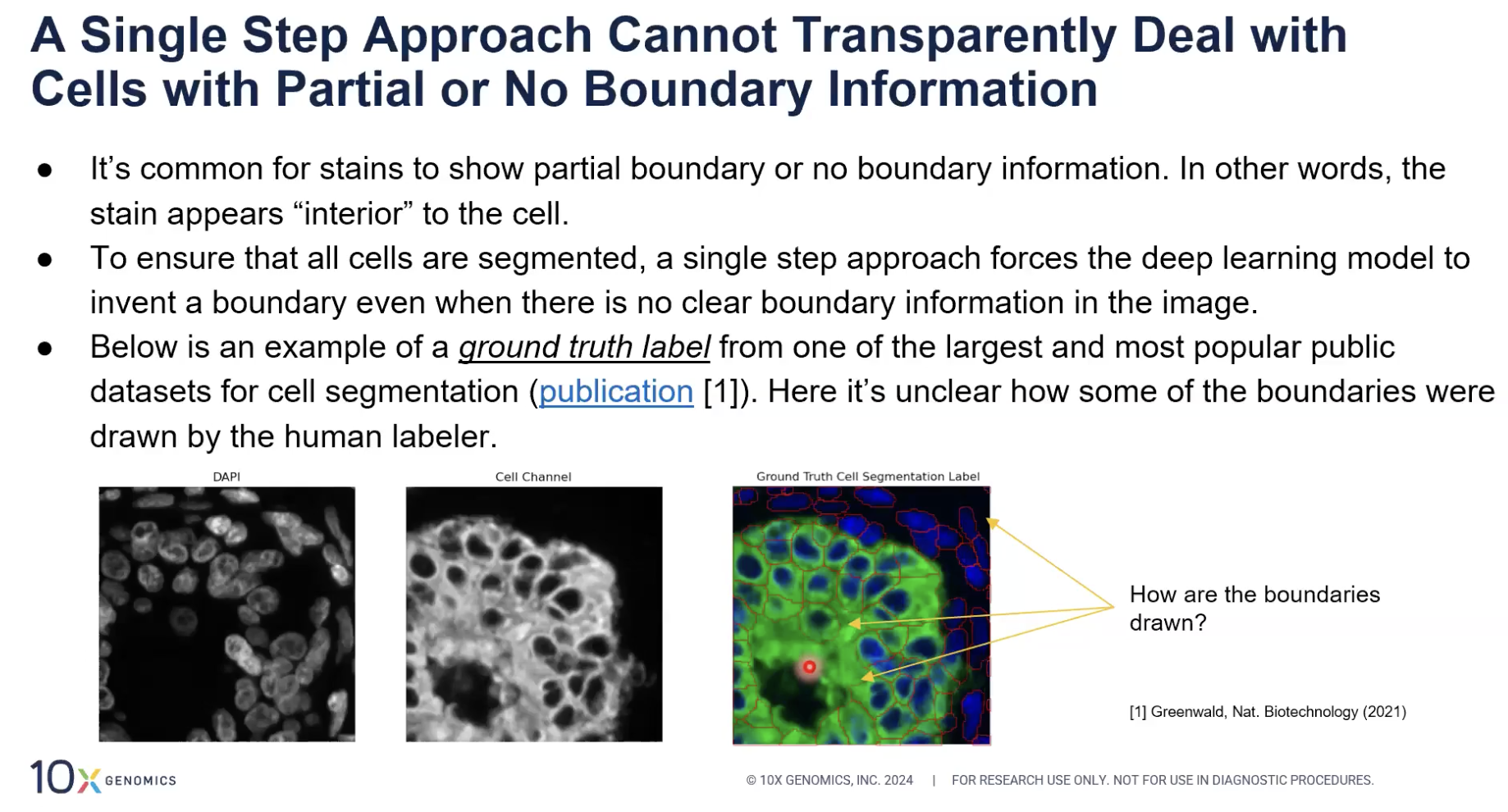
- “一步到位”算法的第一个局限性,在于当细胞marker无法清晰展示出细胞所有的边界的时候,算法不能够非常透明的处理这种情况。
- 在现实生活中,如果marker不能清晰标记细胞的完整边界,那么,这些marker往往会标记出细胞的内部,也就是marker存在于细胞的内部,所谓的”marker is (located) interior to the cell”,或者我们简化称为interior stain。
- 上述情况发生时,由于模型被要求一步就必须要分割出所有的细胞,哪怕这张图片中存在的信息并不足以完整标记出细胞的边界,模型仍然需要想办法去“凭空发明”出来细胞的边界。
- 要解释这张图片,我们可以参考上图中偏下部分的三张图片。左图是用DAPI染料去染出细胞核的结果,中间是一组染料尝试去染出细胞边界的结果,我们可以看到中间图片的数据是比较模糊的,因为我们虽然能分清细胞内和细胞外的区域,但是不能分清细胞之间的边界。
- 右图是左图和中间的图片融合的结果,红色的信息是人工标记出的细胞边界,也就是所谓的”ground truth”,但是这张图中的某些细胞边界的确定是找不到对应的参考信息的(各位老师能看出这张图中所有的细胞边界吗),也就是说即使是人工标记细胞的边界,也是在猜。
- 更糟糕的是,这张照片并不是人工智能生成的细胞边界数据,而是用来训练人工智能的“教材”,这就让经典模型输出的结果变得更加不可信的(因为在训练数据集中就人为引入了猜测的内容)
- 在过去的一段时间,ChatGPT是科研人员间非常流行的话题,对于包括ChatGPT在内的生成式模型generative model,一个很大的问题是hallucination,具体来说模型在进行运算的时候,有可能会“非常自信”地输出包含错误在内的结果,就好像模型出现了幻觉一样。上图展示的结果,甚至不是模型在hallucinate而是人工标注者在hallucinate。
- 尽管我们可以理解,如果人工标注者们因为无法看到清晰的细胞边界,就对于这一类的细胞完全不标注,那么训练出来的模型就完全无法对这些细胞进行分割。
- 可以想象,当用户使用了包含hallucination的数据训练出来的模型,用户拿到了几十万甚至上百万的细胞分割的结果之后,是无法知道在所有的细胞分割结果中,有多少细胞分割结果是由hallucination的方法来产生的,说到底,这种边界的产生就非常不透明。
- 上述的例子向各位老师清晰地展示了,这种基于深度学习的“一步到位”的算法所共有的局限性,这种局限性的根源来自细胞marker的局限性,现实中根本就并不存在一个或一组marker,使得能够在各种情况下,对所有组织的所有细胞类型,都能够清晰标注出细胞边界。只要现实中的局限性依然存在,“一步到位”的细胞分割算法的这个局限性就是不可能消失的。
局限性2:传统算法不能增加输入信息的数量(channel)
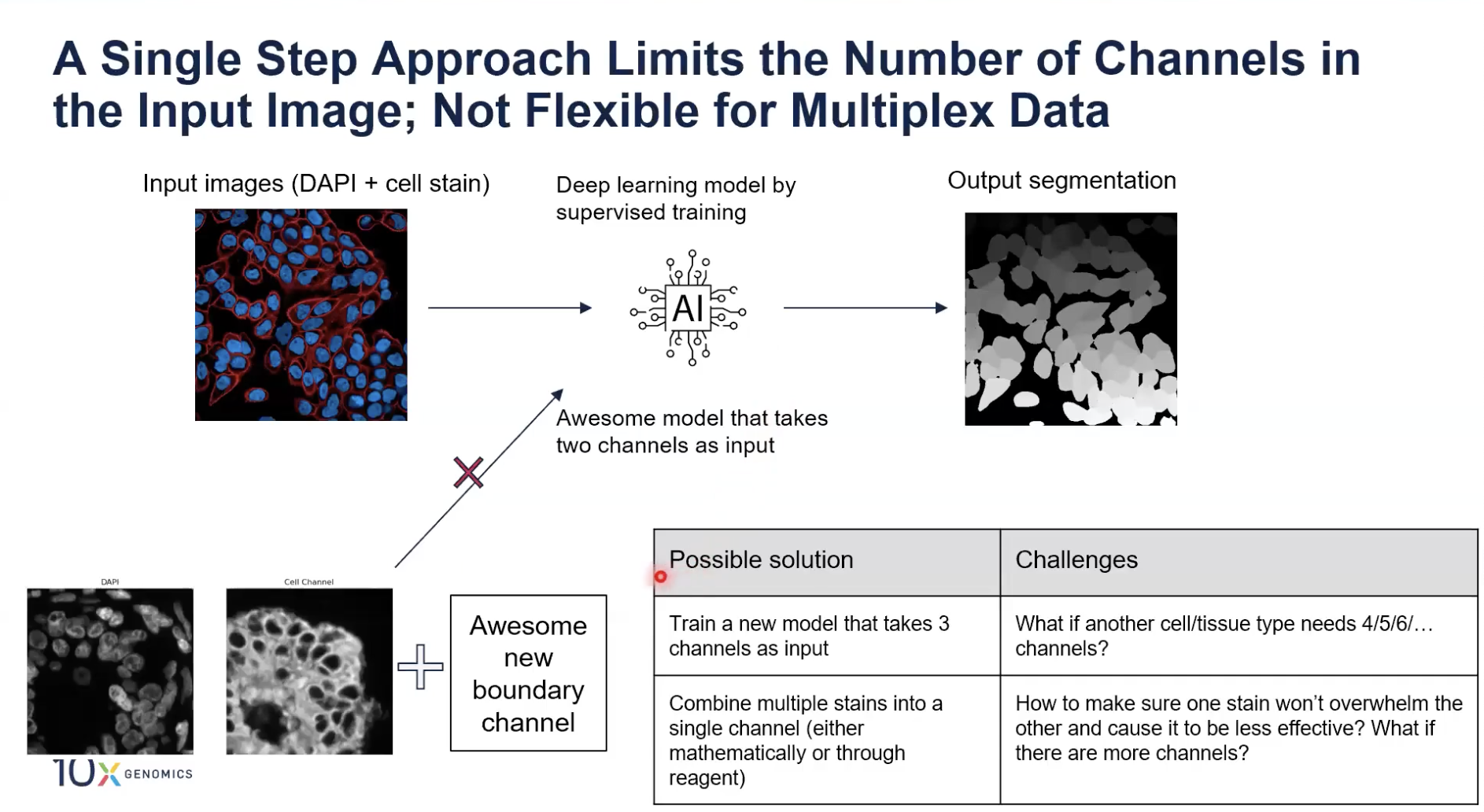
- 第二个局限性在于,“一步到位”的算法限制了输入图片的channel数量,也就是说在处理multiplex(或者说复数个channel)的数据时不够灵活。各位老师可以设想一下,假设我们已经训练了一个非常好的模型来进行细胞分割,这个模型需要输入两个channel,分别是DAPI和细胞marker的channel。
- 这时,各位老师意识到正在使用的细胞marker对于一些细胞不能够很清晰的标记出所有的边界,老师们做了更多的实验,发现了另一些细胞marker可以弥补之前的缺陷,也就是通过增加一个channel的数据就能实现对更多细胞边界的标记了,但是这时我们是不能直接把三个channel得信息直接输入到我们之前训练好的模型中的,这是因为模型在训练的时候已经确定只能接受输入两个channel的图片。
- 如果我们想解决channel数量的问题,一个可能的解决方法是再训练一个接受3个chanel作为输入的模型,各位老师可能了解,如果想训练出一个全监督学习的模型,其中花费的很大一部分时间和努力都要落在对新的三个channel的数据进行标注上。
- 如果对于另一个不同种类/不同细胞类型的样品,老师们需要更多channel的细胞marker(组合),上述方法的灵活性就非常差了,因为不能简单的拓展规模,英文是scalable。
- 另一种解决方法是使用某种“融合魔法”,把两个channel的数据融合在一个channel中,无论是使用基于算法的方法,还是基于实验的方法,将更多channel的数据又重新变回两个channel。
- 这种解决思路的问题是,在我们把多个细胞marker融合在一起时,要保证它们彼此之间互不影响,也就是一种marker不会让另一种marker对细胞的标记的有效性降低,是非常有挑战性的。尤其是当各位老师引入的细胞marker数量不断增加时,marker间相互“打架”导致总体的有效性降低的情况是非常常见的。
- 一句话总结,“一步到位”的方法不能灵活地解决多个细胞marker数据的问题。
Xenium算法简介

- 正是这两种局限性,促使了10x研发多模态细胞分割的算法。10x的目标是要开发出一种更加透明和更加灵活的算法。
- 对于透明性的解释:当细胞marker不能很清晰地标记出细胞边界的时候,10x开发的算法不能去凭空“发明”细胞边界,而是用更简单和更可解释的方法试图推断细胞的边界。同时,10x要告诉用户,在所有的细胞分割的结果中,有多少细胞是通过推断的方法分割出来的。
- 此外,10x希望开发出的算法系统能够更灵活和方便得使用多种不同的细胞marker的数据。
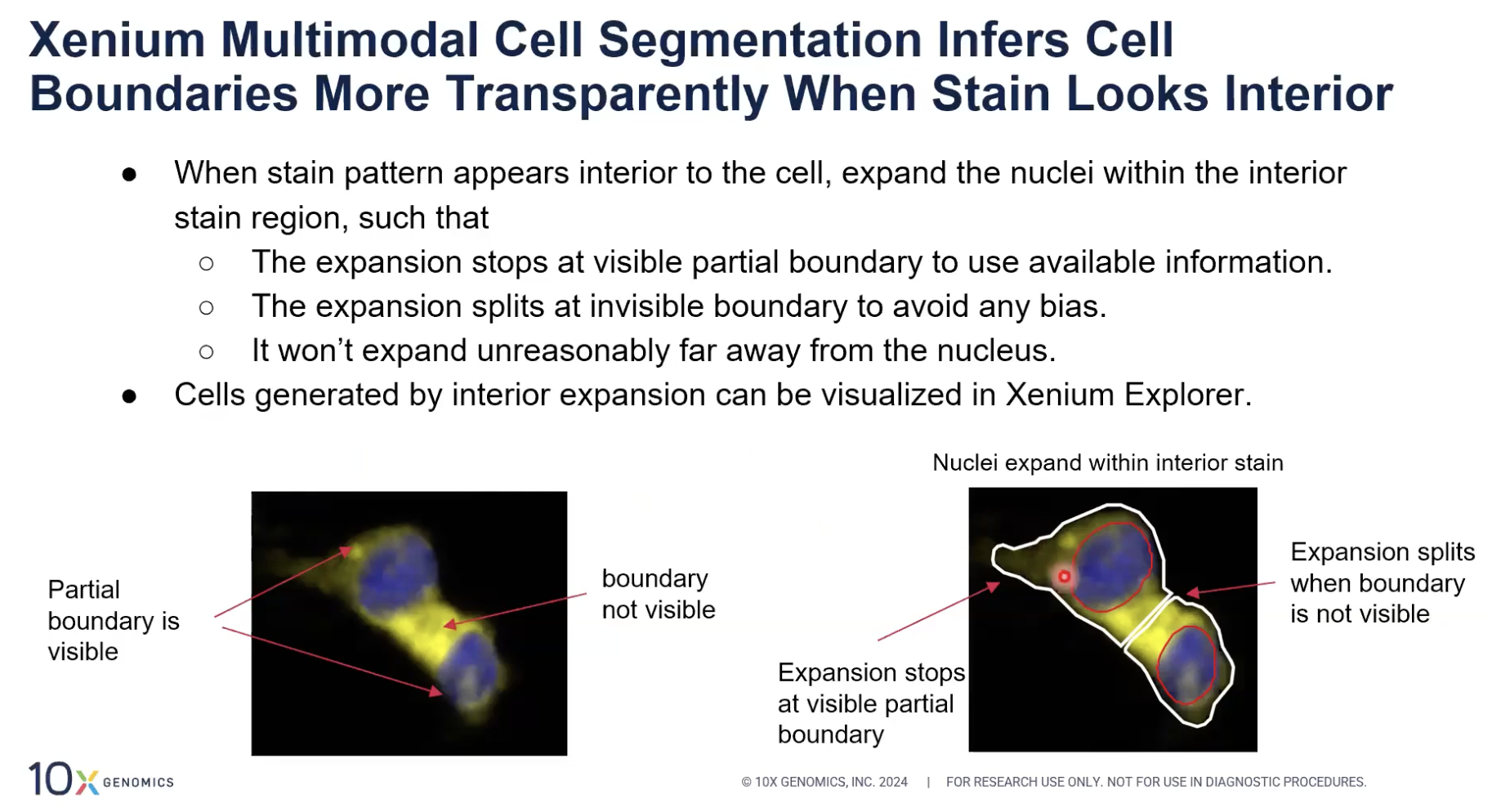
- 上图是关于在Xenium多模态细胞分割中,当10x开发的算法遇到了interior stain的情况是如何处理的。
- 上图中展示的黄色的信号是细胞marker的信号,那蓝色是DAPI染料染的细胞核。可以看到左图中的细胞marker可以标记出一些边界的,比如外围的边界与细胞内和细胞外的边界,但是无法标记出这两个细胞之间的边界。
- 遇到这种情况的时候,Xenium多模态细胞分割会将细胞核在interior stain的内部进行扩张。这种扩张在遇到清晰的interior stain边界的时候就会停止;此外,扩张只会应用到marker能够看到的细胞边界,而对于清晰边界不可兼得时候,扩张算法会平分中间的interior stain的区域。同时10x也会要求,扩张的距离不能非常远,远到不合理的程度。最后,所有用扩张算法产生出的细胞分割的结果在Xenium Explorer中都是可见的。
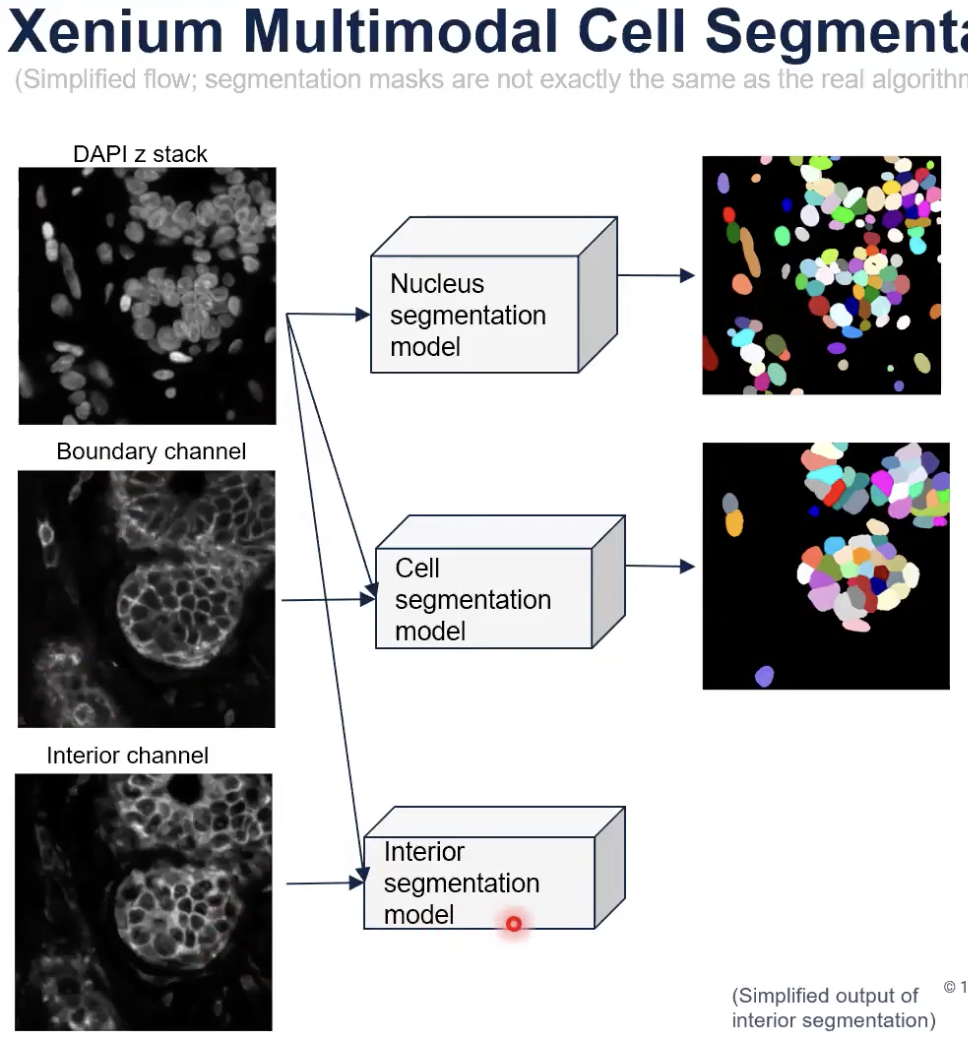
- 上面介绍的,更透明的处理interior stain的方法,是10x整个细胞分割算法系统里面的一步。下面的示意图解释了10x开发的算法系统中大致有哪些步骤。
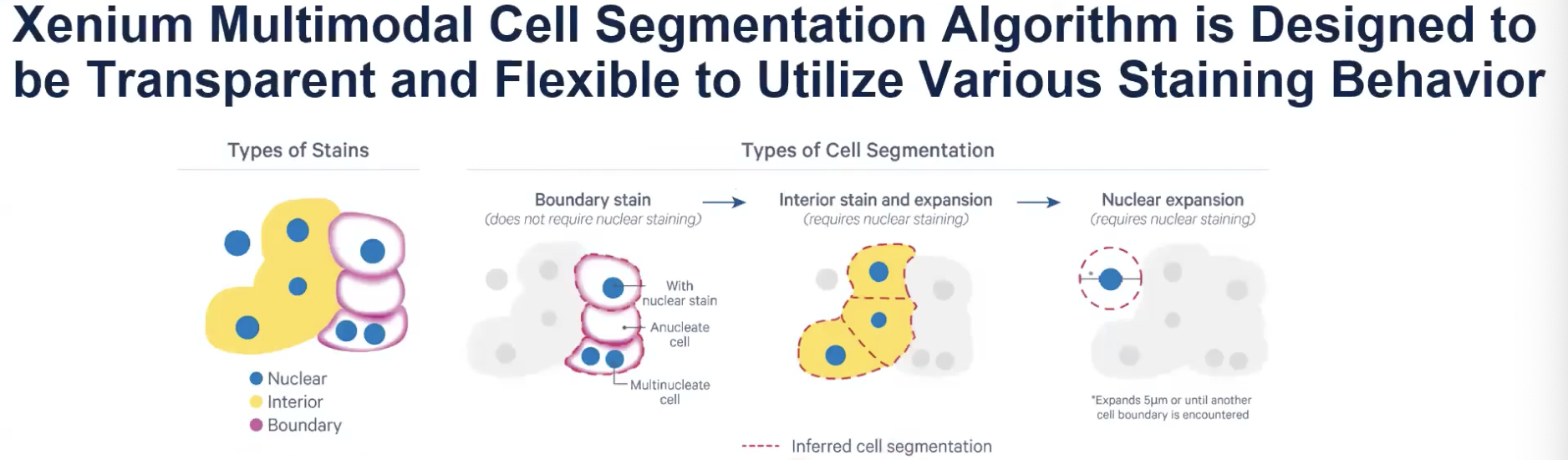
- 示意图中展示了三种不同的细胞marker可能出现的情况。
- 粉色是细胞膜染色,这种细胞marker可以清晰标记出整个细胞完整的边界。黄色的细胞marker是interior stain,这种marker可以标记出一些边界,但当细胞的距离非常近,甚至是紧挨在一起的时候,这种marker就无法标记出一个细胞与相邻细胞的边界。还有一种情况,对某个细胞可能他没有被任何的细胞marker所标记。
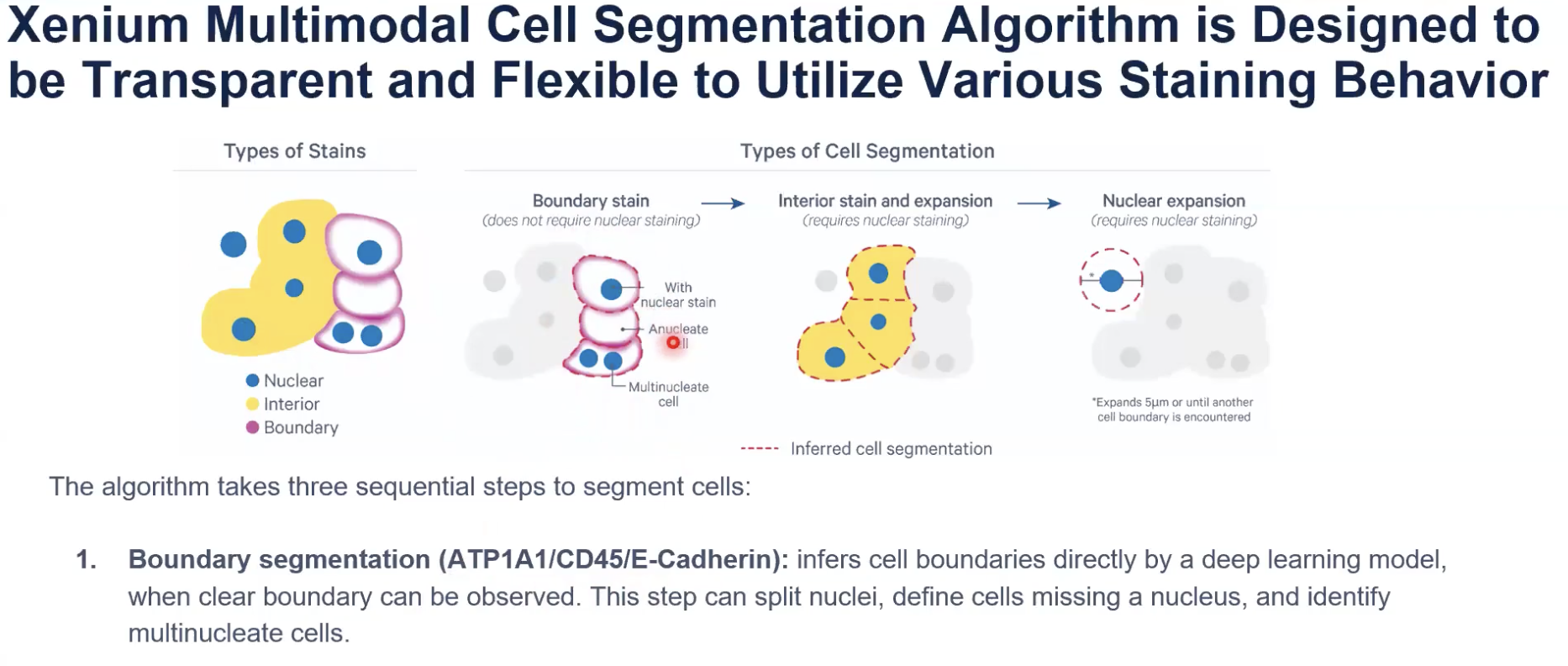
- 10x开发的算法会首先关注到边界marker(或者说细胞膜marker)指示出的细胞,边界marker是ATP1A1,CD45和E-cadherin。由于这些细胞的边界是清晰可见的,算法会直接输出细胞分割的结果。此外,由于这些细胞的边界是清晰可见的,算法也会注意到没有细胞核的细胞和有多个细胞核的细胞。
- 接下来,对于那些没有清晰的细胞边界,也就是处在interior state之中的细胞,算法会对细胞核进行在interior state区域中的扩张。interior state是由核糖体18S亚基的染色去确定的。
- 算法的扩张会在interior state的边界处停止,也会在已经分割好的细胞的边界处停止。
- 目前发布的算法版本中,interior state的扩张只支持使用18S的信号,在未来的软件与算法更新中,会逐渐加入对Vimentin和alphaSMA的支持。(目前已经支持,只是本期教学视频录制的时候尚未支持)
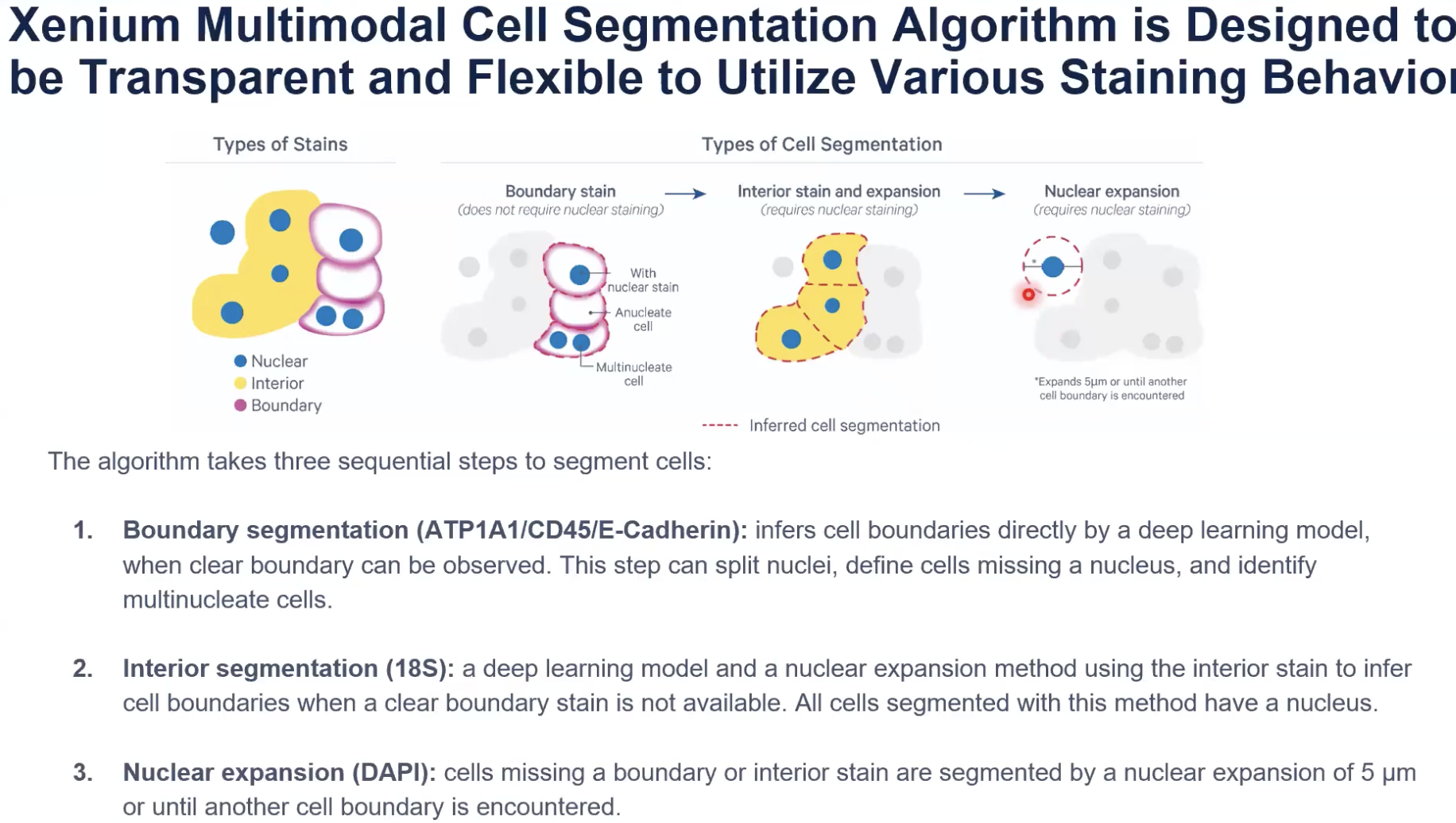
- 最后,对于那些没有任何细胞marker所标记的细胞核,10x会进行最多5μm的均匀扩张。当扩张触碰到某个已经被分割好的细胞边界时,这个扩张也会停止。
一个实例展示Xenium的算法工作流程
- 上图是一个真实的例子,我们会Step-by-step地展示10x的算法系统中更多的细节。
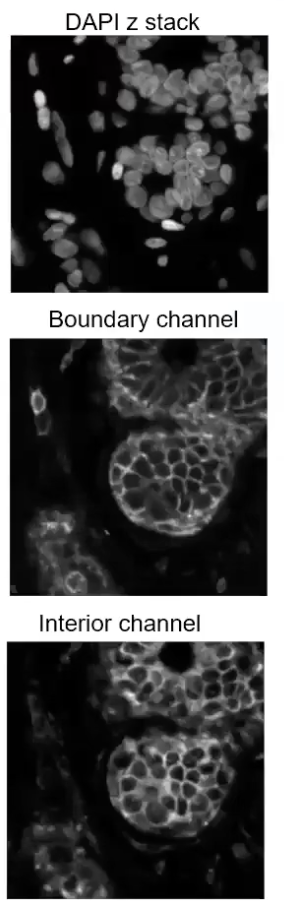
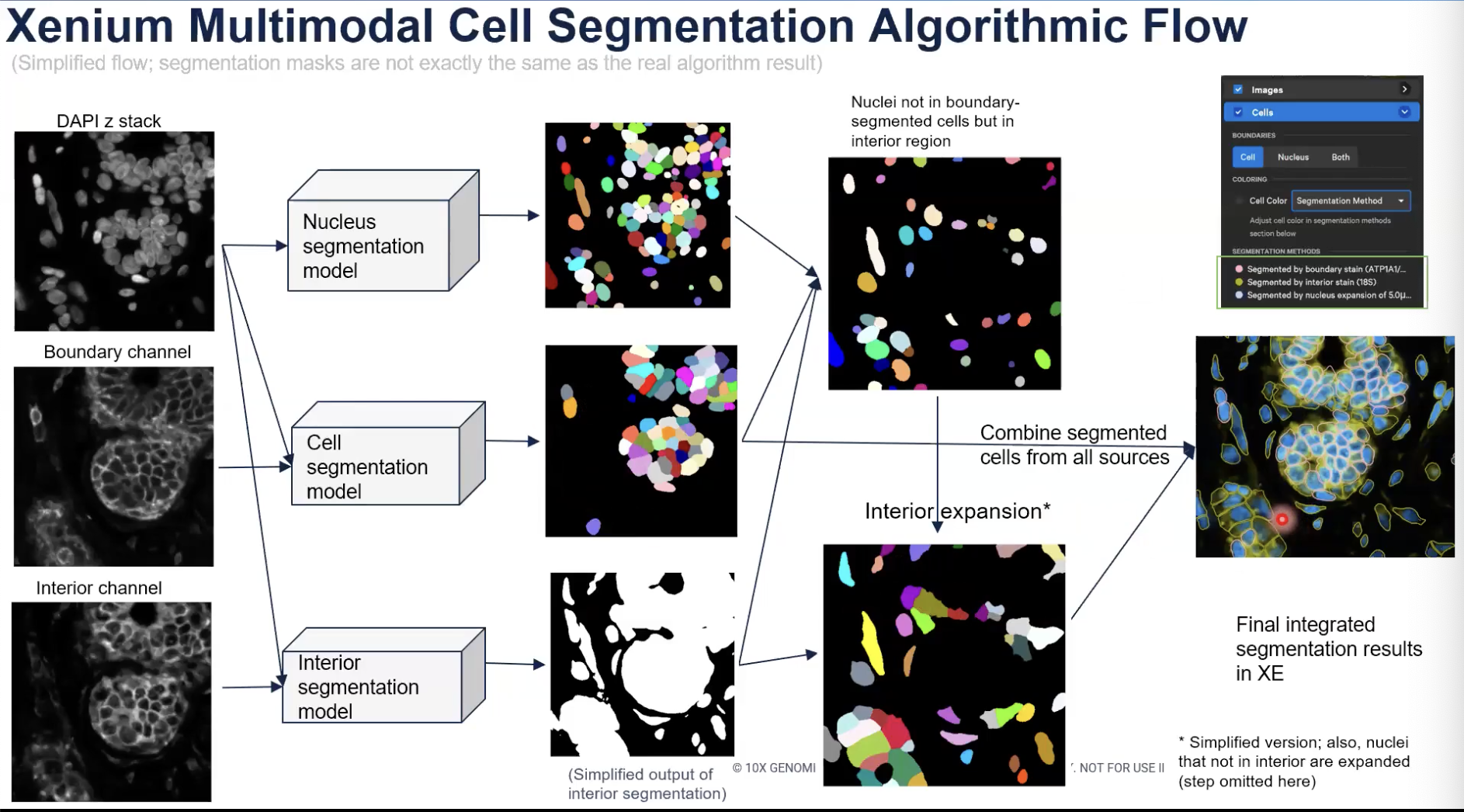
- 首先,如上图所示,10x算法的整体的输入,包含了三种类型的图片。分别是DAPI染色,也就是细胞核的图片;接着是Boundary Channel,也就是ATP1A1、E-cadherin和CD45染色的结果,最后是interior channel的图片,也就是目前核糖体18SRNA和未来加入的Vimentin和alphaSMA染色的结果。(目前已经支持对Vimentin和alphaSMA染色的分析,只是本期教学视频录制的时候尚未支持)
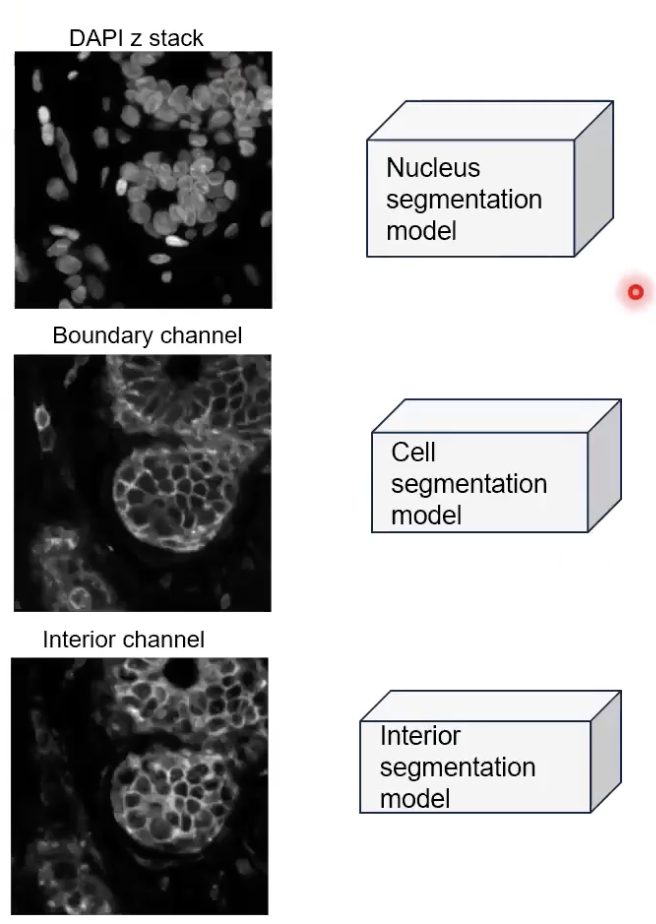
- 算法中包含了三个深度学习的模型。分别是对细胞核进行分割的模型(这个算法与10x上一代的细胞核分割的算法基本是一致的),对细胞进行分割的模型和对interior state所在的区域进行分割的模型(以下称为interior segmentation模型)。
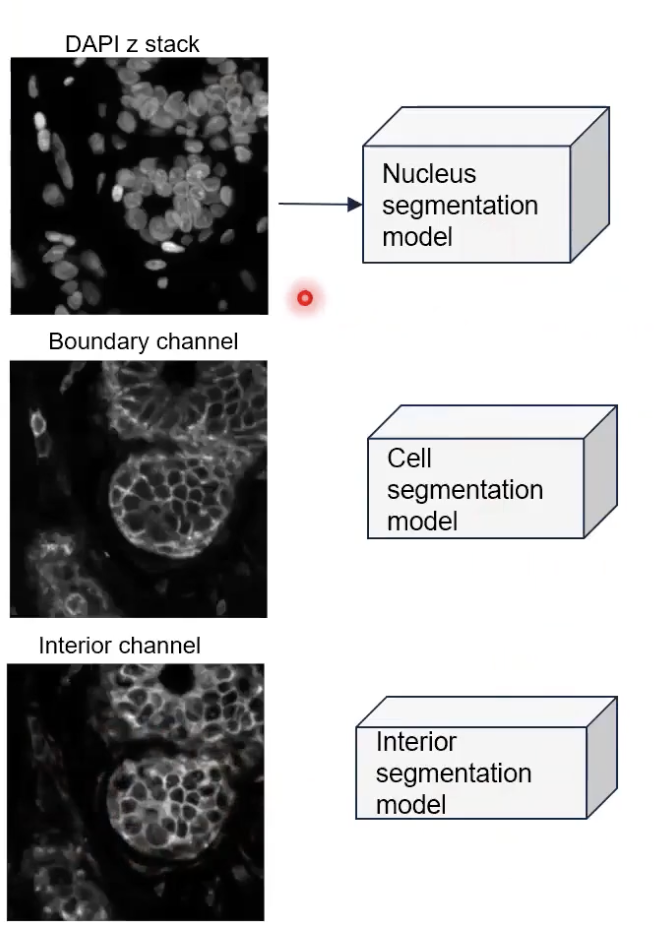
- 算法首先把细胞核的图片输入到细胞核分割模型,之后细胞核分割模型会产生出所有细胞核的分割结果。
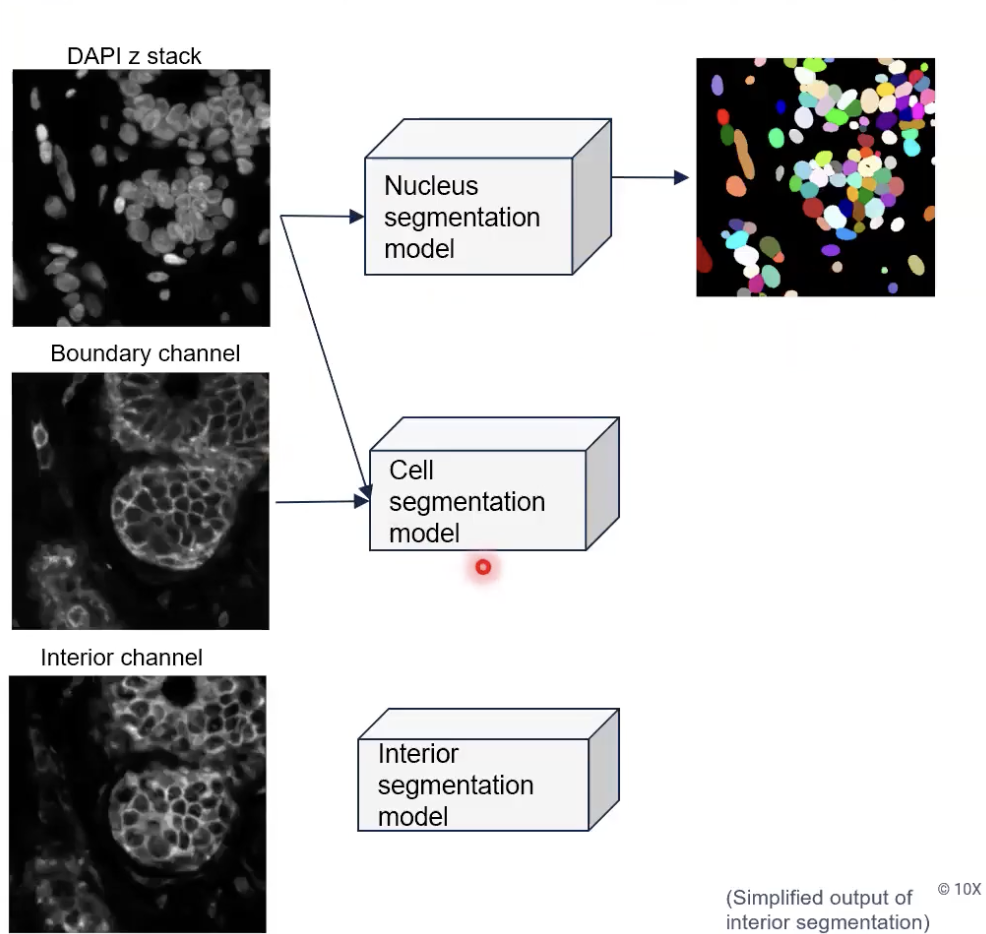
- 接着,算法会把细胞核图片和Boundary Channel图片,输入给细胞分割模型。这时,对于能够从Boundary Channel中看到清晰边界的细胞,将会被细胞分割模型直接分割出来,如下图所示。
- 也就是说,对于能从细胞marker中看到比较清晰的边界的细胞,细胞分割模型就会直接输出这些细胞分割的结果。但是,对于细胞边界染色不能看到细胞边界的,细胞分割模型就会忽略这个区域的细胞。
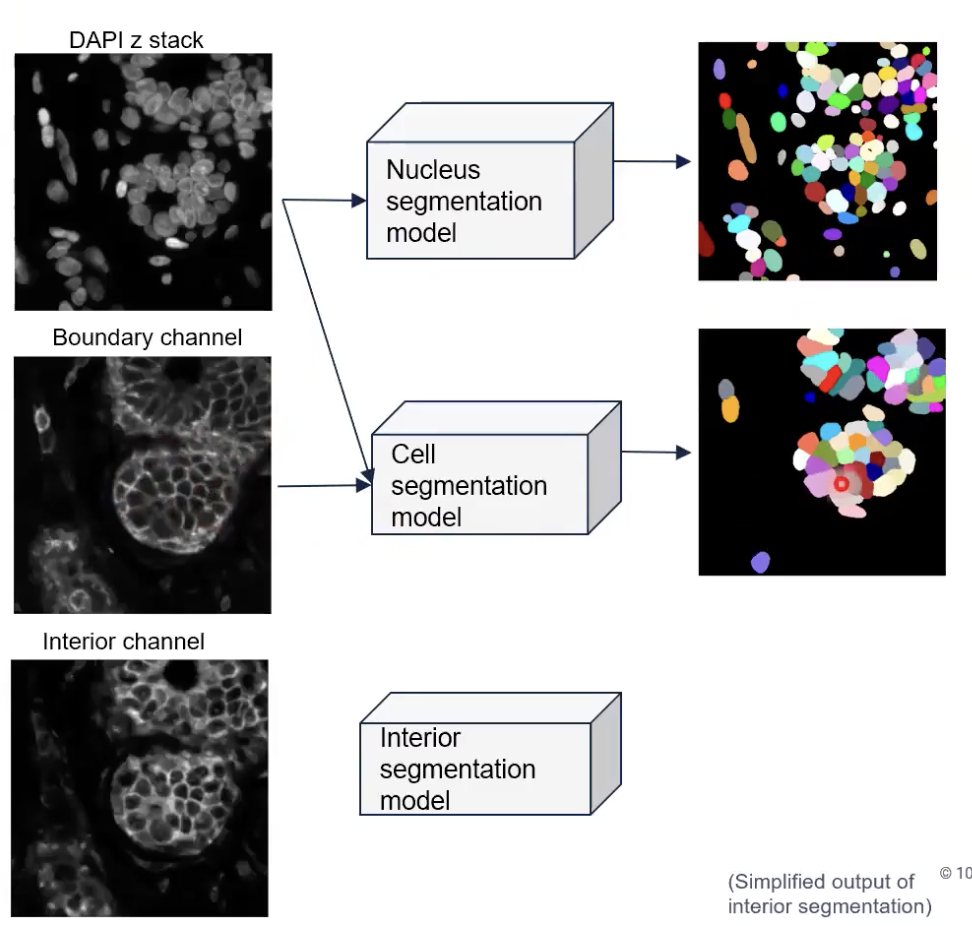
- 接着,如上图所示,算法会把细胞核的图片和interior channel得图片一起输入interior segmentation的模型中。

- interior segmentation模型会输出interior state所处在的区域。这个模型本身的输出其实相对复杂的,这里为了简化讨论,老师使用了binary image来简单展示这个模型的输出。这张binary image涵盖的信息在于,白色的位置就是算法中观察到了interior state所在的位置,而黑色的位置是没有interior state的位置。
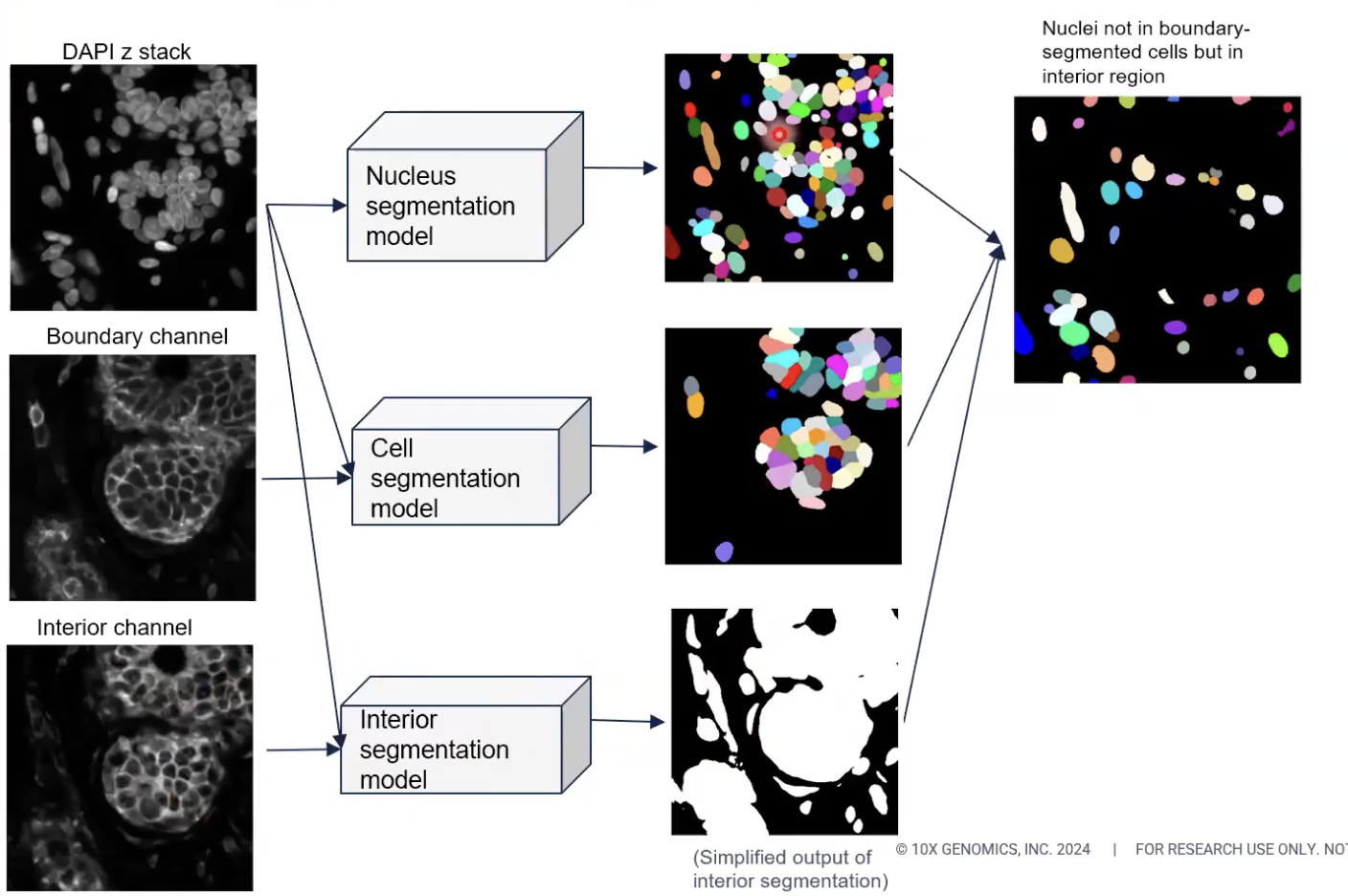
- 接着,算法会比较已经分割好的所有的细胞核图像,和利用清晰的细胞边界染色得到的细胞图像。算法将会发现,对于某些细胞核,已经能够找到与之相对应的分割好的细胞边界,那么对于这些配对了的细胞和细胞核来说,细胞分割任务到这里就已经结束了。
- 但是,对于那些算法找不到对应的细胞位置的细胞核,算法又发现这些细胞核处在interior state当中的,算法会选出这些细胞核。换一种方法理解,算法会选出那些没有对应的细胞分割结果,但是处在interior state之中的细胞核,然后运行扩张算法,如上图所示。
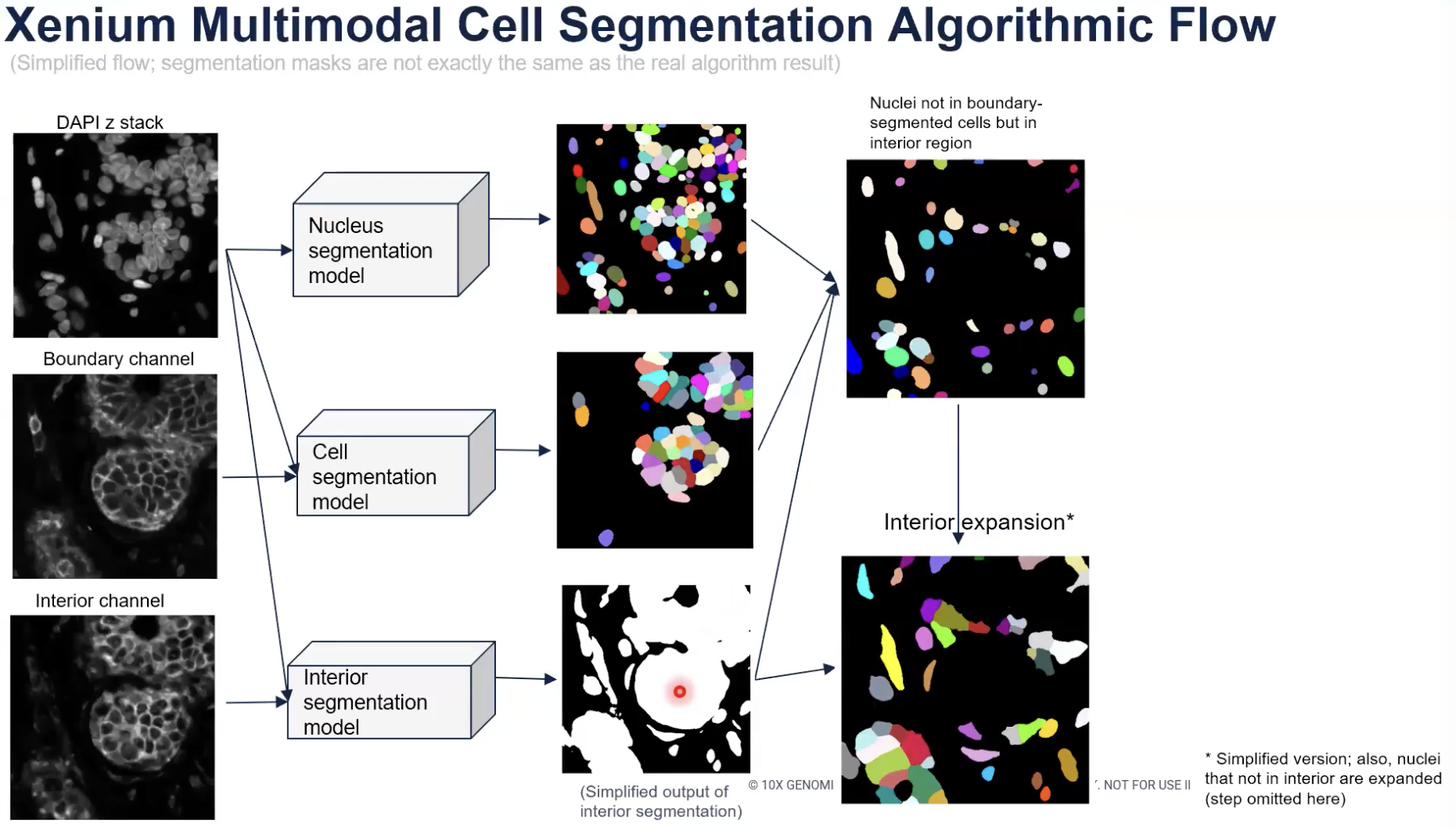
- 对于上面介绍的,处在interior state中的细胞核进行扩张的算法,其实是有一定水平的简化处理的,因为算法细节本身也有一定的具有。
- 最后,对于那些既没有准确的细胞边界可以指派,又不处在interior state中的细胞核,算法会对细胞核会进行均匀的扩张,这种扩张最多为5μm,且如果在扩张中碰到了之前已经确定的细胞边界(无论是清晰的细胞边界还是interior state扩张的结果),都会提前结束,这个步骤在展示图中没有显示出来。
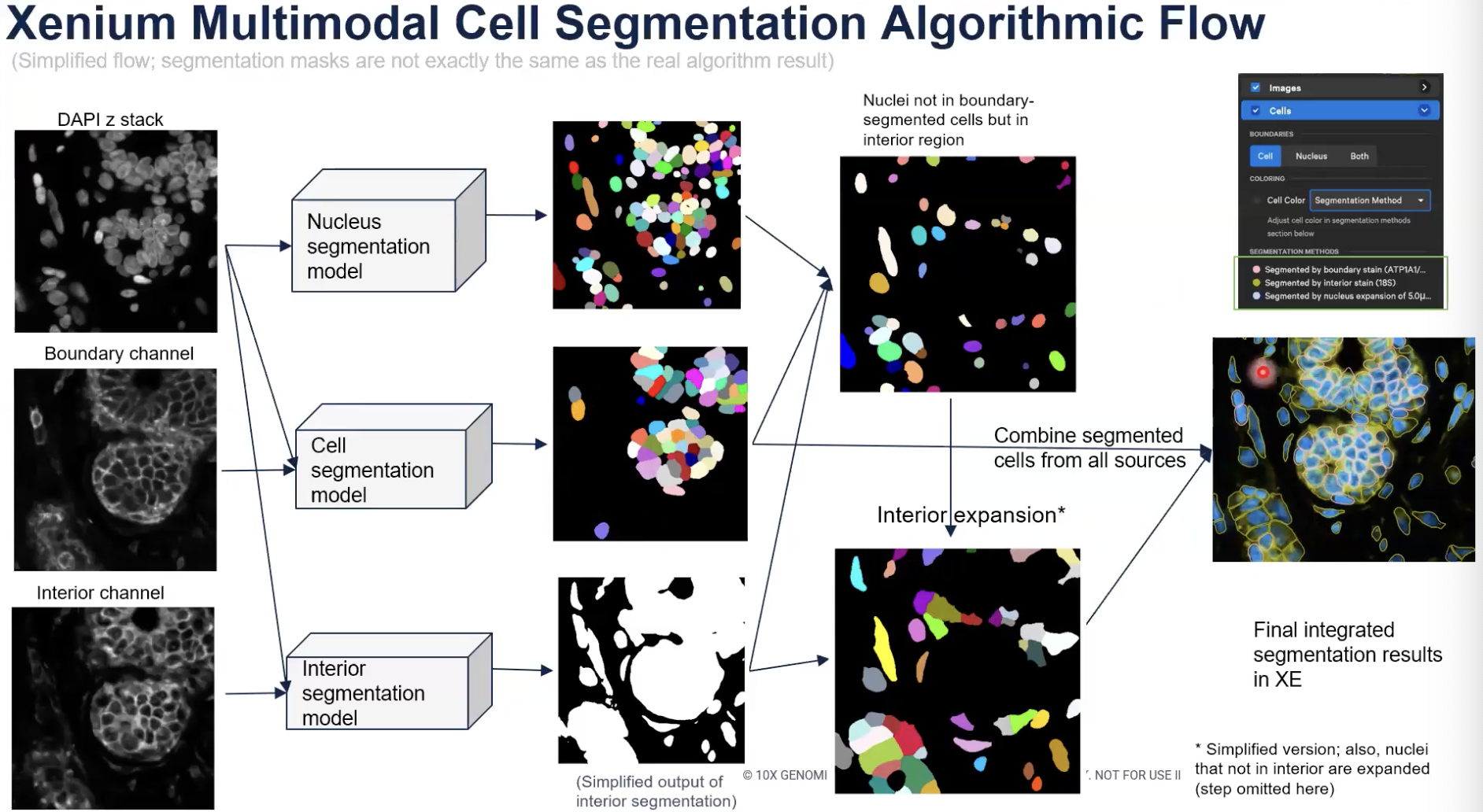
- 最后,算法会将用清晰的边界分割出的细胞和用interior state扩张的方法分割的细胞组合在一起,加上均匀扩张细胞核的算法得到的结果,就成为了最终输出所有的细胞分割的结果。
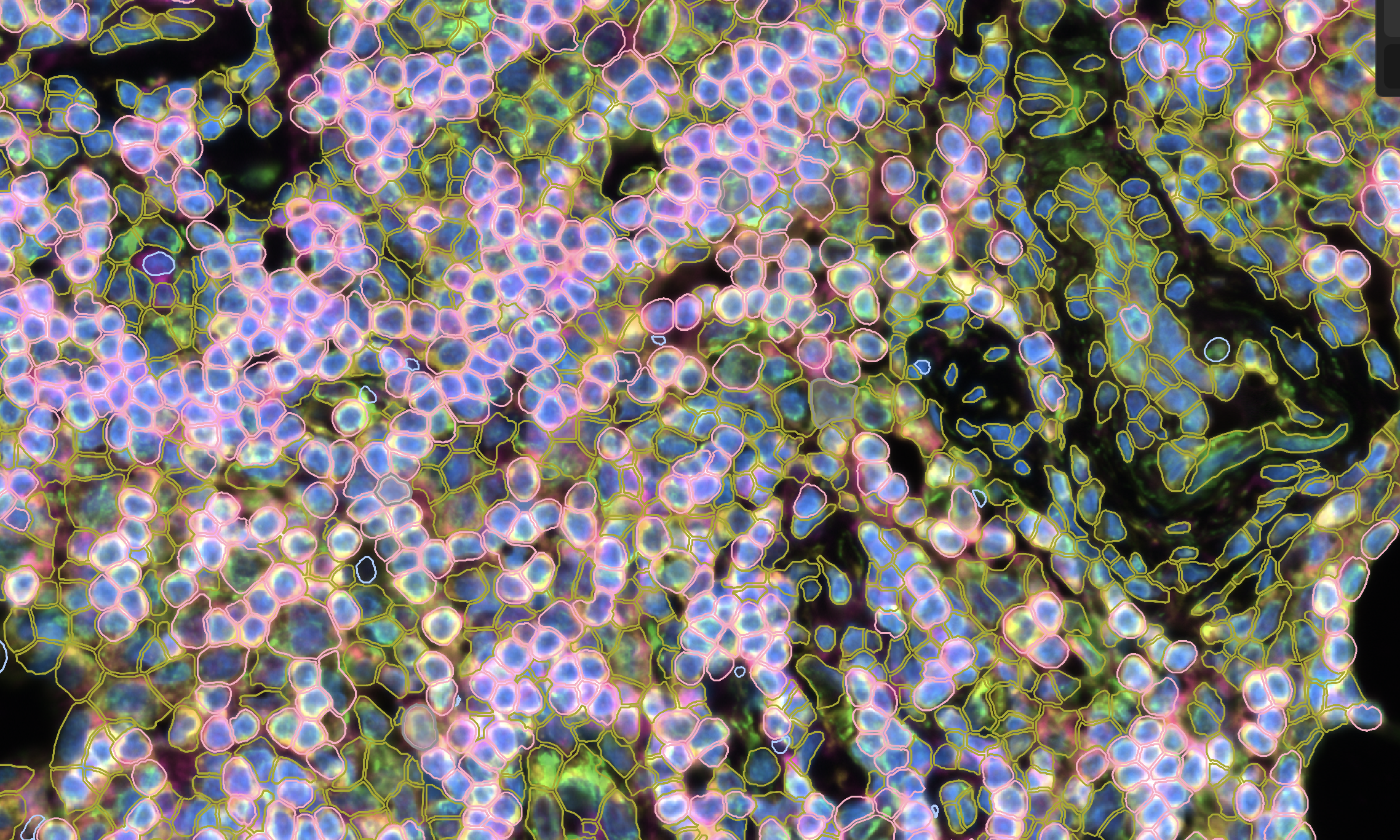
- 如上图所示,在Xenium Export当中,如果老师们选择用Segmentation Method对细胞进行上色,老师就会发现,所有用细胞边界来分割的细胞,都会呈现出粉红色的边界,如果是用interior state扩张确定的细胞,就会展示出黄色的边界。如果是用核直接扩张算法确定的细胞,就会展示出蓝色的边界;所以各位老师可以非常清晰地看到每个细胞和使用的分割算法,相比于之前的“一次性算法”产生的结果准确性和透明性都高了很多。
如何评价Xenium算法输出结果的质量

- 接着,让我们来讨论一下如何衡量Xenium多模态细胞分割结果的好坏。这是一个比较难以回答的问题,困难的来源在于没有人工标记的”ground truth”来与Xenium算法产生的结果进行比较。因此,作为替代,10x推荐下面的几种方法来对细胞分割的结果进行评估。
方法1:观察细胞核扩张方法获得的细胞边界的比例
- 首先,各位老师可以在web summary中观察使用细胞核直接扩张的算法猜测出的细胞的比例,10x的预期这个比例应该是比较小的,这是因为,10x的预期绝大部分的细胞都至少会被一种细胞marker所覆盖。那些没有被任何细胞marker所覆盖的,均匀扩张的细胞所占的比例是比较小的。
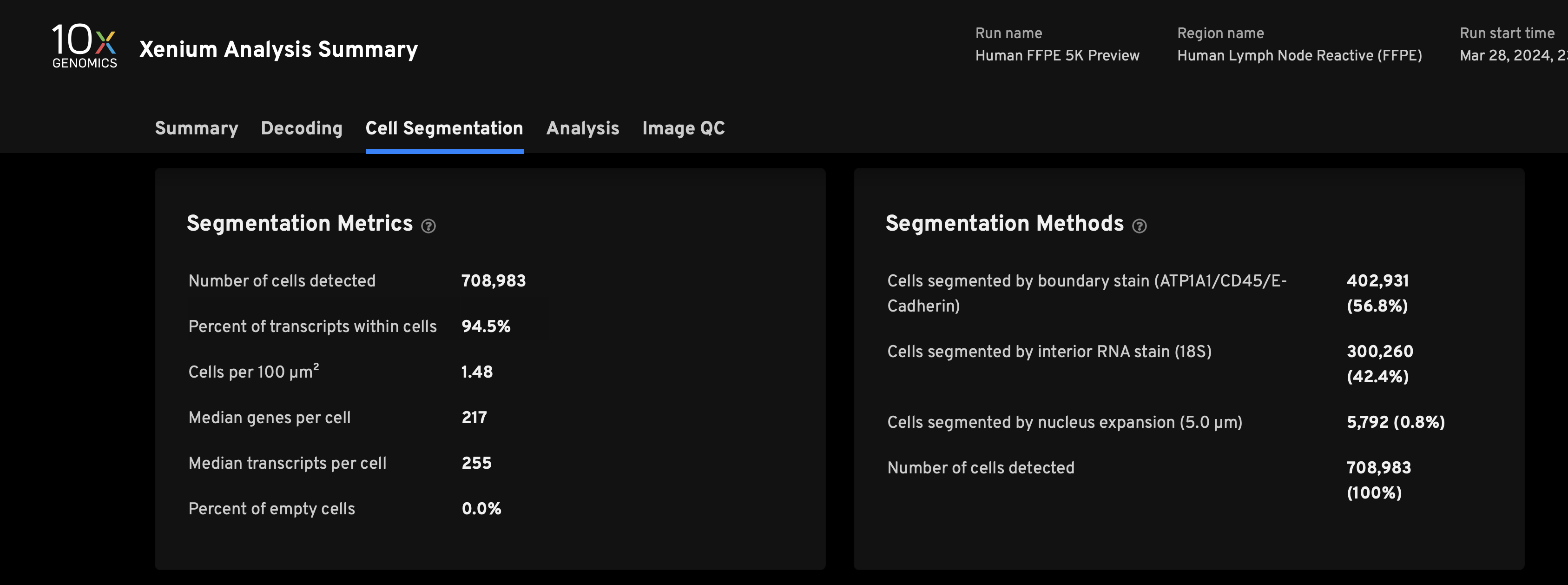
- 如上图所示,各位老师可以在web summary-cell segmentation中找到cell segmentation methods,然后关注”cell segmented by nucleus expansion (5.0 μm)”这一行展示出的比例,在10x的实验中的一般这个数据会小于10%。
方法2:基于形态学进行判断
- 第二种判断细胞分割准确度的方法,是在Xenium Explorer当中,请病理学家用肉眼来观察算法产生出来的边界和图片本身展示出的边界的吻合程度是否足够好。
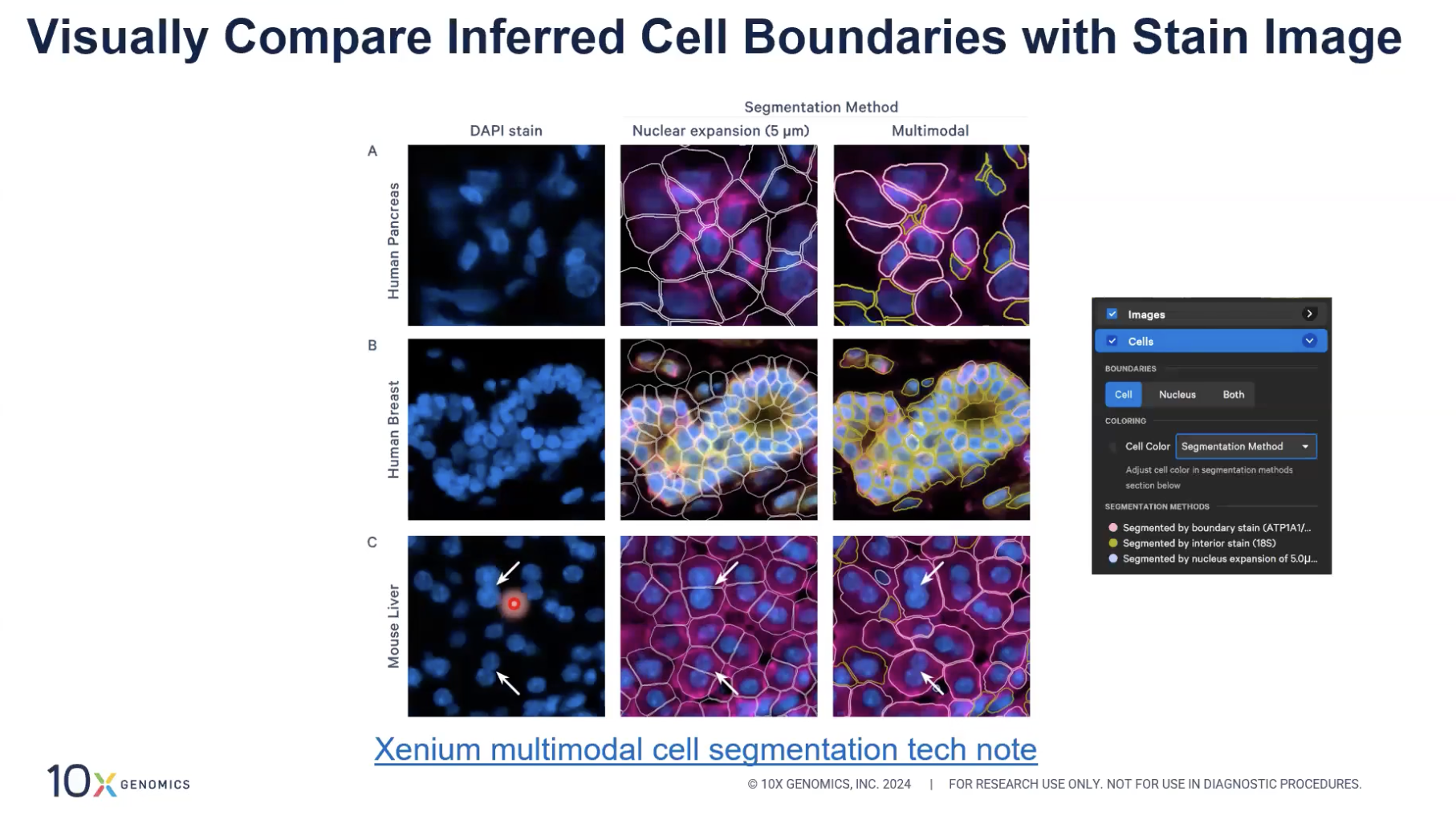
- 上图是一个简单的例子,当中的左边一栏是样本细胞核染色的图片,中间一栏是10x基于细胞核扩张算法(就是把每一个捕捉到的细胞核都直接向外扩张最多5μm)得到的结果,以白色边界的方式去展示,右边的三张图是用最新的多模态算法得到的细胞核分割结果。
- 各位老师可以看到,中间的细胞边界算法得到的结果与粉色染料(ATP1A1,CD45和E-cadherin)指示出的边界其实是不吻合的,也就是说这种细胞分割的方法得出的结果是不够准确的。相对的,右边这一栏,是用10x的多模态细胞分割算法分割出来的细胞,这种算法得出的细胞边界与细胞marker的边界有更好的吻合。
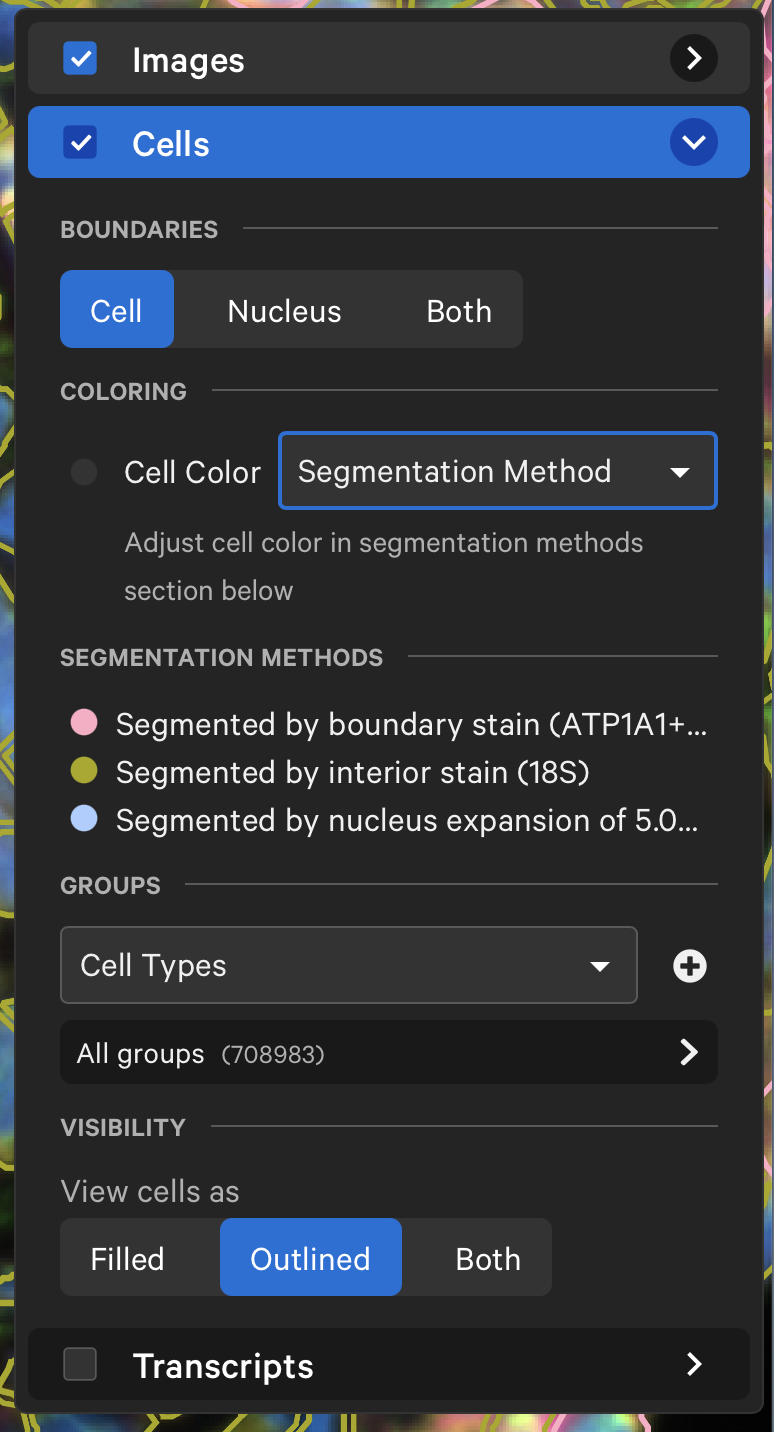
- 在Xenium Explorer中,我们可以通过用细胞分割方法对细胞进行染色
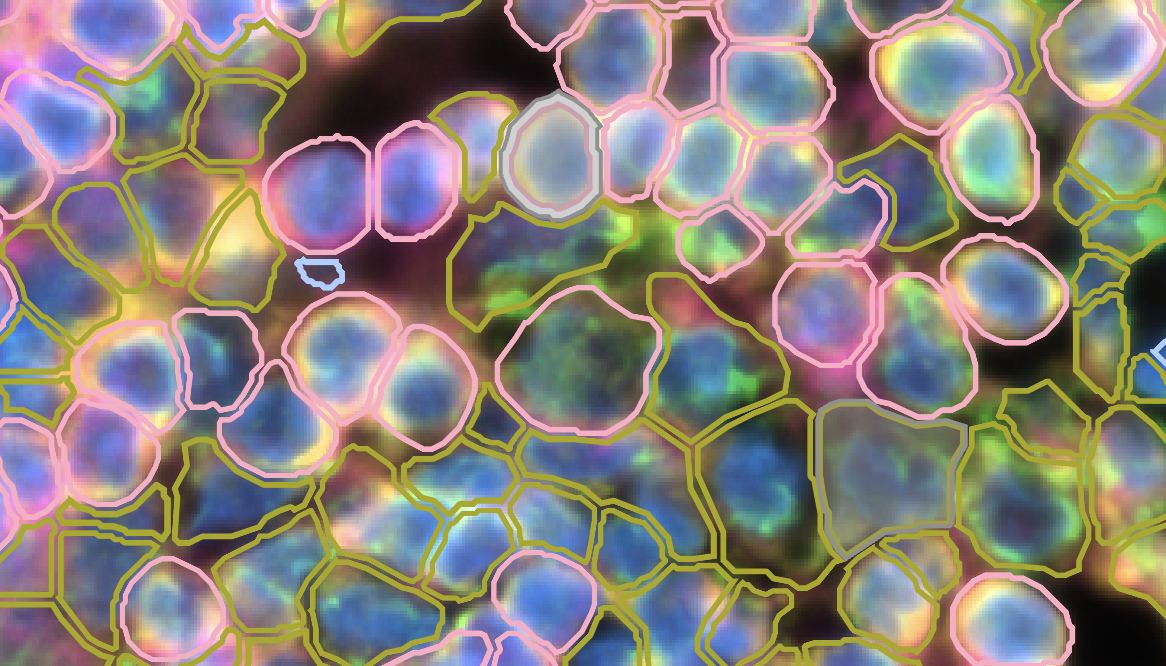
- 如上图所示,对于仅使用细胞边界染色就能确定边界的细胞,Xenium Explorer会用粉红色的细胞边界加以展示,对于使用了细胞内容物marker(也就是18SRNA,Vimentin和alphaSMA)和扩张算法得到的细胞边界,Xenium Explorer会使用黄色(或者说绿色)的细胞边界加以展示,最后,对于仅使用细胞核扩张算法得到的细胞边界,Xenium Explorer会用蓝色的边界加以展示。
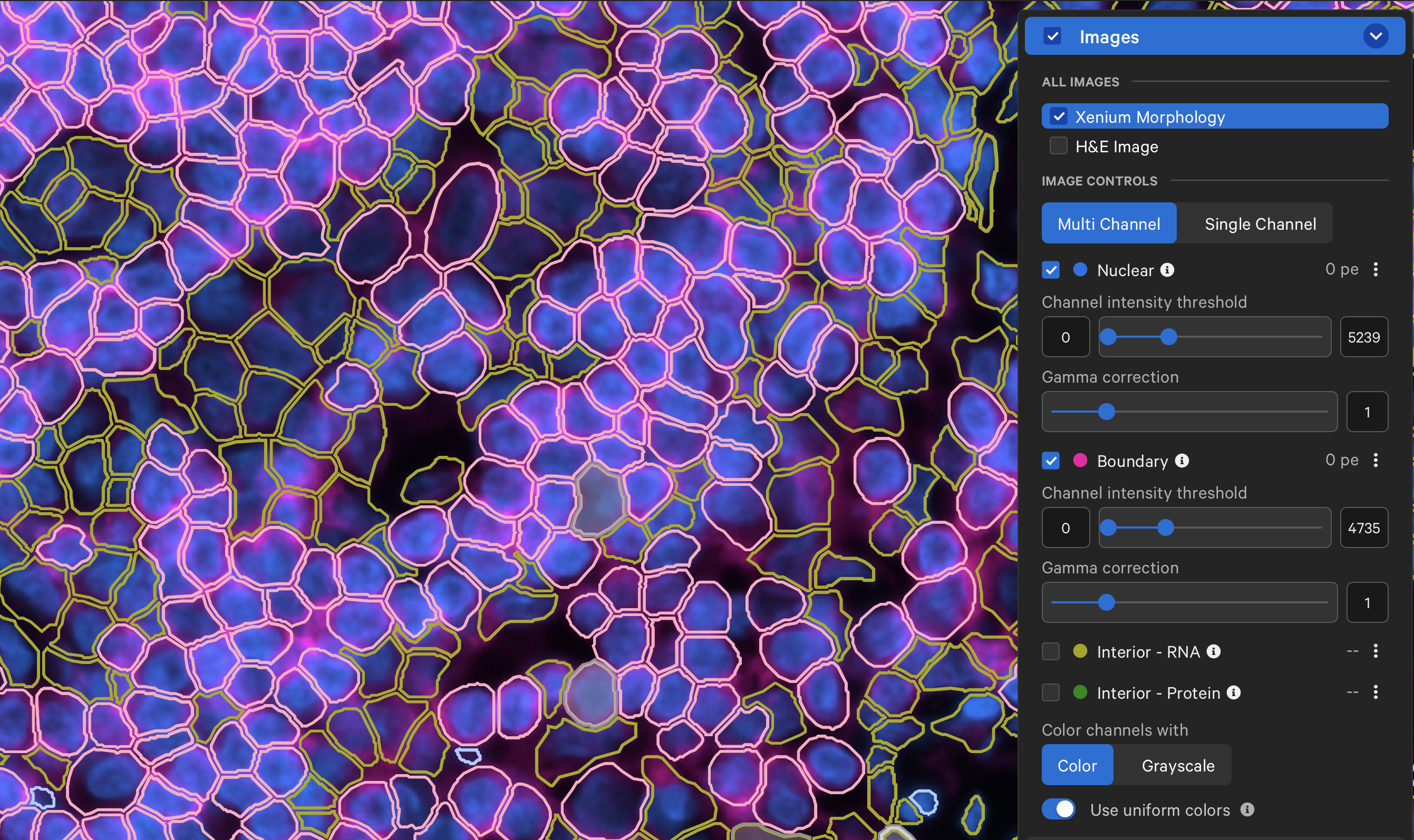
- 如果各位老师想评价基于细胞膜边界算法勾勒出的细胞边界,可以在Images-Xenium Morphology中只选择DAPI和Boundary Channel,这样就可以根据形态学对算法产生的结果进行评估了。
方法3:基于生物学知识判断> 来源:
- 最后一种衡量细胞分割算法质量的方法,是使用一些已知的生物学的知识来判断算法得出的结果是否是符合各位老师的预期。
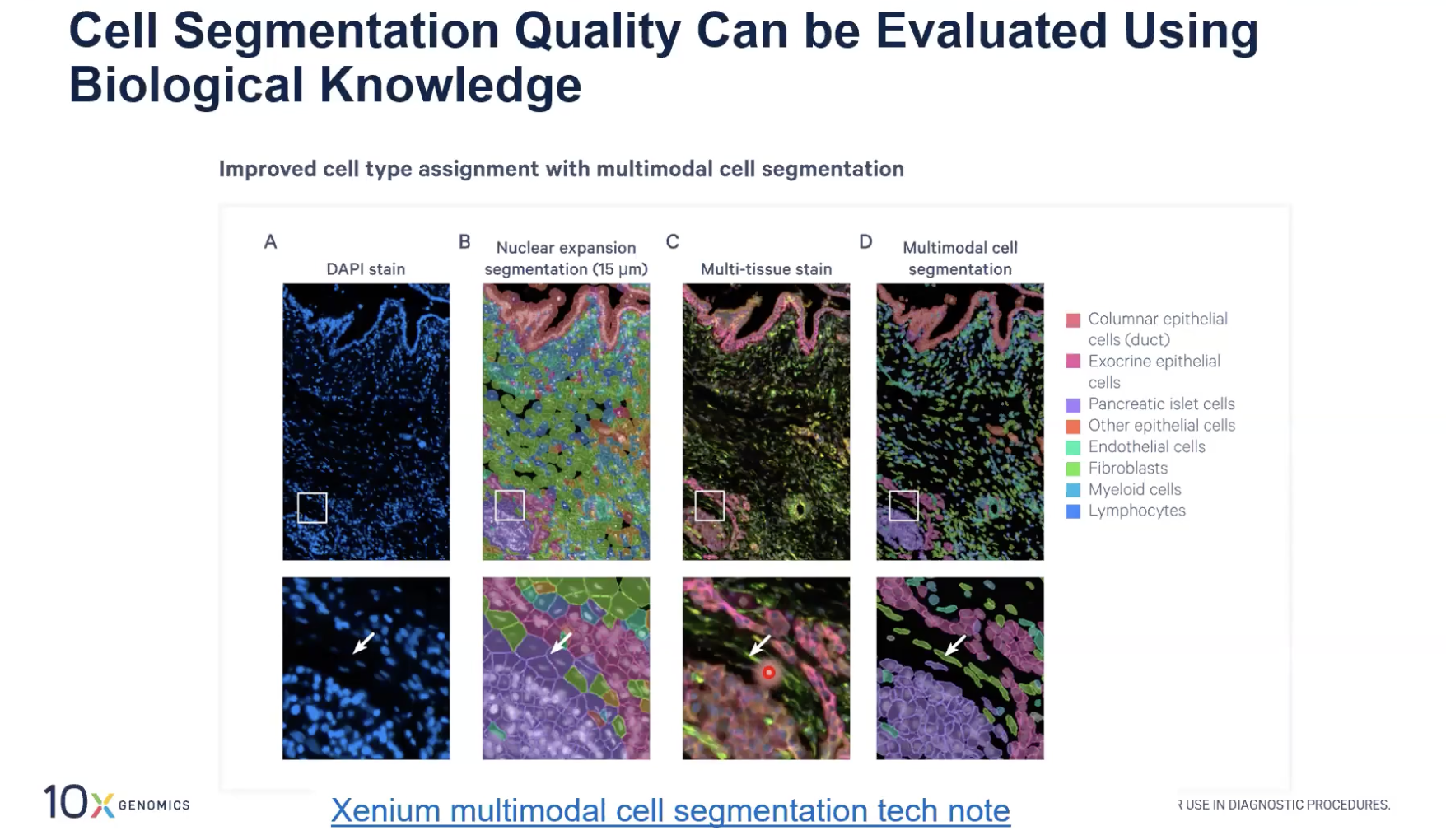
- 在上图中,如果只使用细胞核扩张的算法,各位老师可以看到图中指示的细胞被归类为了pancreatic islet cell,也就是胰岛细胞,但是在使用了新一代的多模态细胞分割算法后,这个细胞被归类到了fibroblast中,而fibroblast与这个细胞的形态学类型更加相符。
- 类似的,各位老师也可以用您的知识来判断这个细胞分割算法结果的好与坏。
算法的局限性
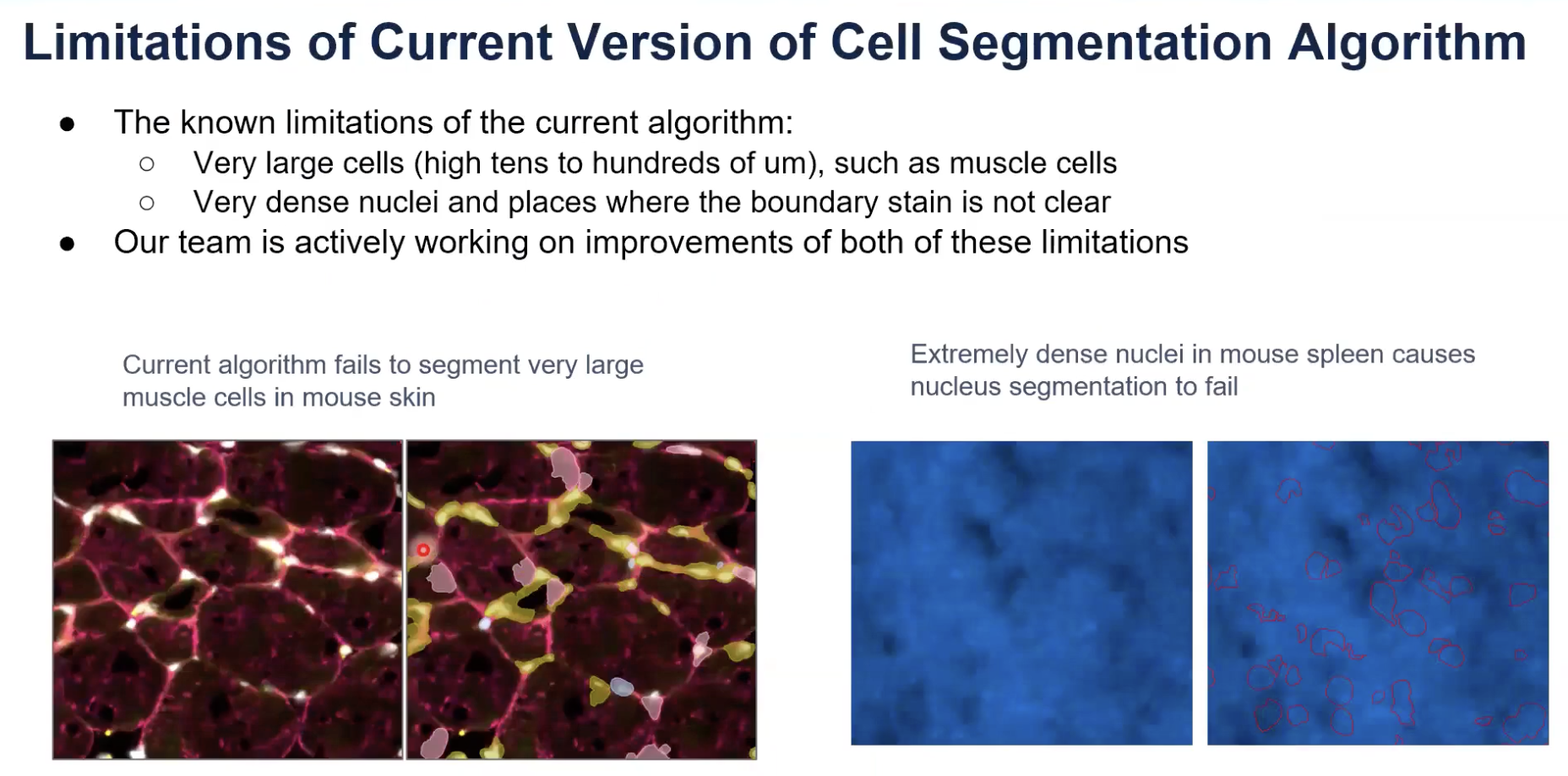
- 10x的算法目前有两个局限性
- 首先,现在的算法还不能分割细胞体积非常大的,直径接近于上百个微米的细胞。一个常见的例子是肌肉细胞,上图左展示的就是肌肉细胞尝试运行细胞分割算法的结果,可以看到分割出的结果基本是比较破碎的细胞,此外,有很多细胞都用到的都是用直接扩张细胞核的方法来进行分割的。
- 其次,当细胞聚集的非常紧密,导致DAPI染料和算法都无法清晰地判断出细胞核的边界时,细胞核的分割将会遇到非常大的困难,如果同样的区域还没有非常清晰的细胞的边界的标记,那么对应区域的细胞分割就就会不是很理想。
- 10x的团队正在非常积极地解决这两个问题,也会在之后的软件升级中将这个算法升级包裹进去。
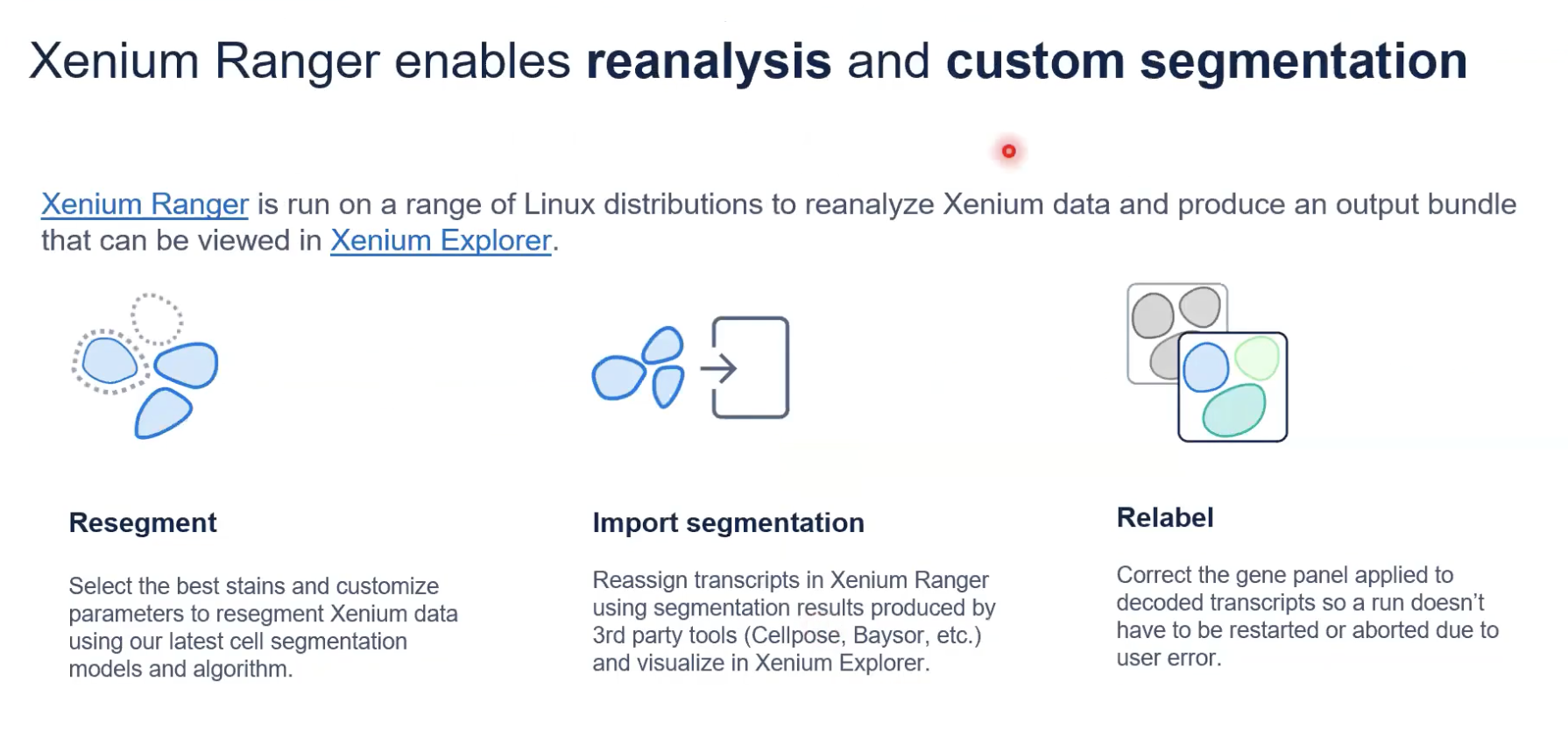
- 当10x有新的算法软件的升级,有需要的老师就可以使用10x所开发的Xenium Ranger重新对您之前的数据进行细胞分割和分析,重新分析的结果也可以在Xenium Explorer中看到。

- 此外,Xenium Ranger也支持对第三方的细胞分割的结果进行输入来帮助您分析。
- 时至今日,细胞分割仍然是非常具有挑战性的任务,也是非常热的科研领域。10x并不认为有一个“金标准”方法可以解决掉所有的细胞分割的问题。上图列举了一些第三方开发的软件和方法供大家参考,这些方法一般可以分为两大类,一类是基于图片来进行细胞分割的,还有基于转录组来进行细胞分割。