Xenium Panel设计概述
- Xenium原位技术可以使研究人员以亚细胞分辨率表征细胞和组织内的RNA,Xenium的技术可以准确地分辨出感兴趣的组织区域的细胞;与此同时,在亚细胞分辨率下,通过探针结合的原理,探测RNA分子的分布情况
- 目前,Xenium技术能够同时探测最多480个基因(定制panel)
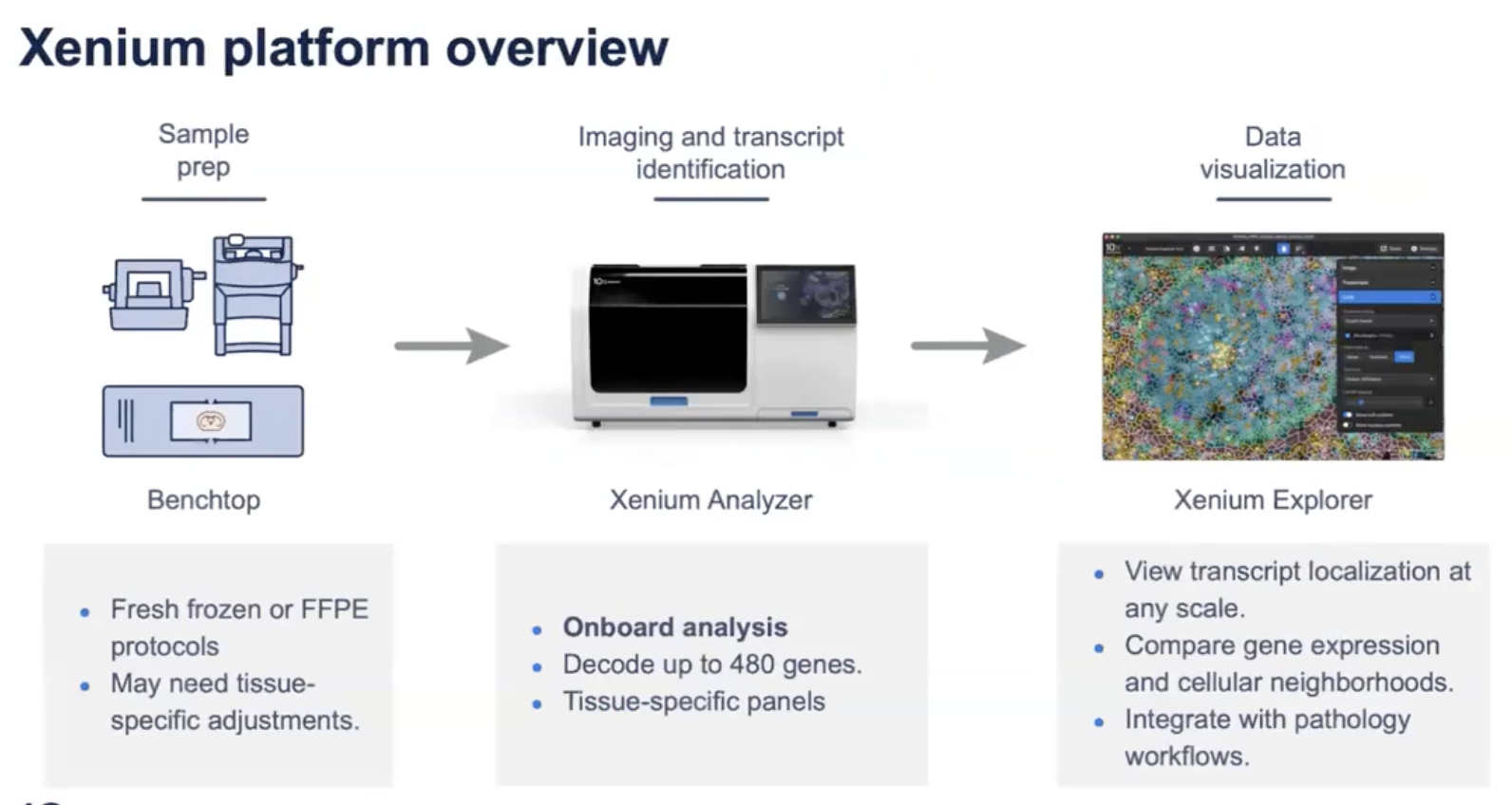
- Xenium技术在很高程度上已经实现了自动化,前期只需要非常简单的样本制备,后续的成像以及RNA transcript的探测,以及数据分析都可以在Xenium的仪器里面的自动进行;Xenium仪器运行结束后的产出文件可以用Xenium Explorer进行可视化,也可以导入到其他第三方软件进行下游数据分析,比如说Seurat和ST-Learn
- 目前来说,对于定制panel,同时最多可以探测480个基因;在Xenium实验开展前,研究人员可以根据不同的组织结构、不同的病理状态以及不同的研究问题,事先选择想要探测的基因,再由10x生产这些探测这些基因的探针而后便可以进行Xenium实验。
- 前期设计的这一过程便是今天要谈的Xenium Panel的设计;根据实验要求,研究需要在Xenium实验前进行Xenium Panel的选择和预先设计

- 目前来说Xenium Panel的选择有两类(其实是三类,还有一类5000个基因的Pan-Tissue Panel),第一类是关于Pre-design Panel,10x已经预先设计了6个人类的Pre-design Panel以及两个小鼠的Pre-design Panel。
- 6个人类的Pre-design Panel包括人类乳腺组织的Pre-design Panel、人类肺组织的、人类脑组织的、人类皮肤组织的、人类肠道组织的、人类多器官多组织和癌症的
- 两个小鼠的Pre-design Panel包括小鼠脑组织的Pre-design Panel以及小鼠多组织的Pre-design Panel
- 这8个Pre-design Panel已经被事先设计、验证并生产,所以研究人员可以直接应用这些Pre-design Panel,大家也可以去10x官网上查看这些Pre-design Panel里面有哪些基因、这些基因可以标记哪些细胞类型、每个基因有多少个探针组等基本信息
- 如果老师们查看Pre-design Panel,发现所感兴趣的基因不在Pre-design Panel基因列表里面,就可以选择在Pre-design Panel的基础上额外添加想要的基因;目前有两种额外添加基因的选项,分别是基于Pre-design Panel加1到50个基因;第二个选项是在Pre-design Panel的基础上加51到100个基因,也就是说对于Pre-design Panel最多可以加100个基因
- 总结:第一类的Xenium Panel的选项针对的是Pre-design Panel,老师们可以直接选用Pre-design Panel,也可以根据Pre-design Panel上额外多加至多100个基因
- 此外,还有第二类的Xenium Panel的选项,如果老师想要研究的人类或者是小鼠的组织不在Pre-design Panel选项,比如想要研究人类卵巢组织,或者是老师对Pre-design Panel里面的基因不感兴趣,想要从头设计Panel里面的所有基因,又或者是如果老师想要研究的物种是非人类、非小鼠,而是其他二倍体的生物;在这种情况下,老师们就需要独立全定制Xenium Panel
- 全定制的panel,10x提供四种选项:
- 1到50个基因
- 51到100个基因
- 101到300个基因
- 301到480个基因
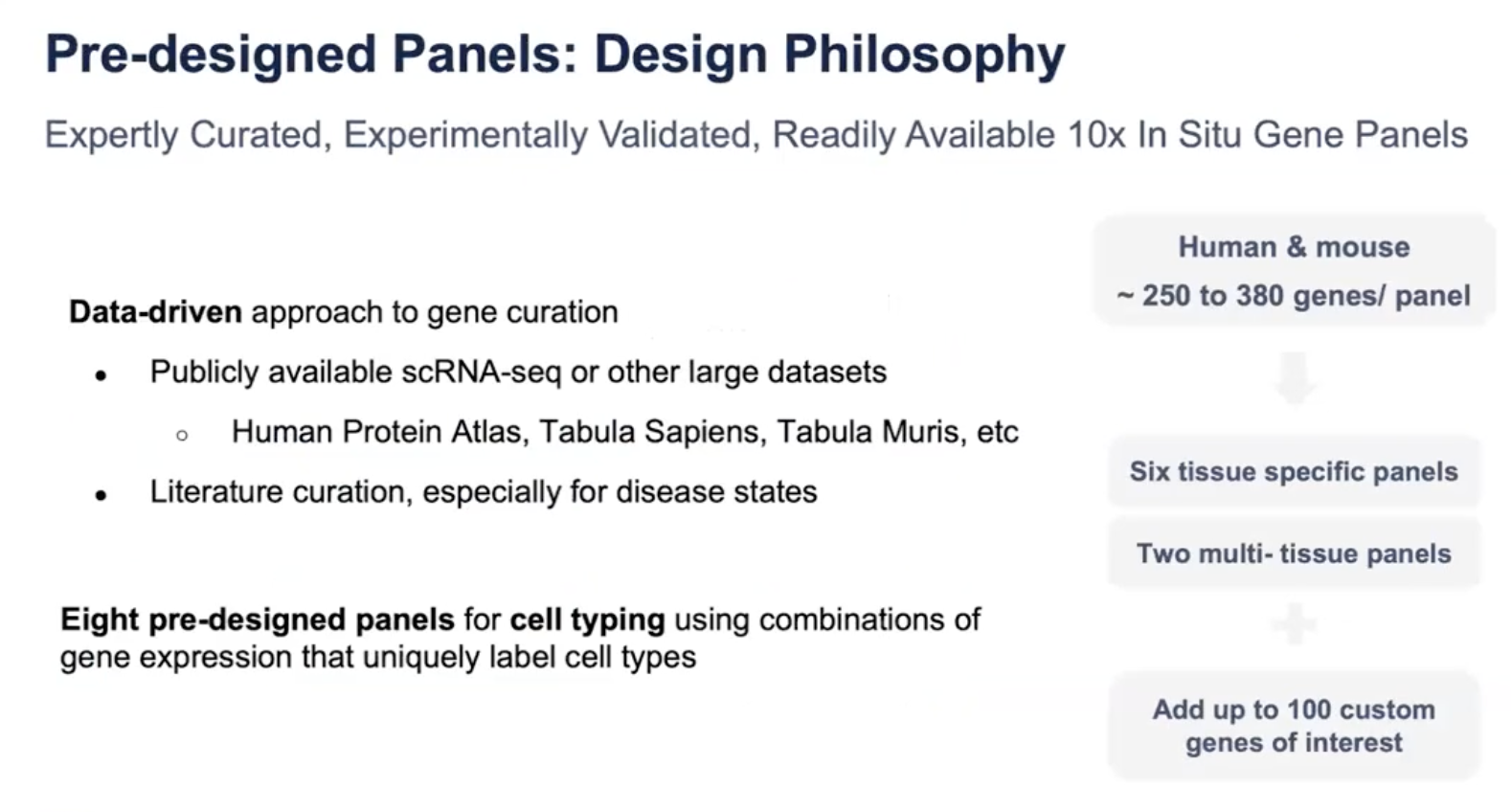
- Pre-design Panel的基因是基于很多公共数据和文献参考筛选出来的,并且这些Panel都已经被实验验证过了,也有相应的库存,可以直接预定选用
- 目前Pre-design Panel是基于人类和小鼠的,在人类上提供了5个组织特异性的Pre-design Panel和一个多组织的Pre-design Panel、小鼠上提供了一个脑组织Pre-design Panel和一个多组织的Pre-design Panel,研究人员可以直接使用这些Pre-design Panel,或者是基于这些Pre-design Panel额外加至多100个基因
- 目前基于人类和小鼠这两个物种的标准基因的Panel设计可以完全由用户自行在Xenium Panel Designer这个网站上完成,Designer网站已经提供了非常直观的设计界面,演示部分见下
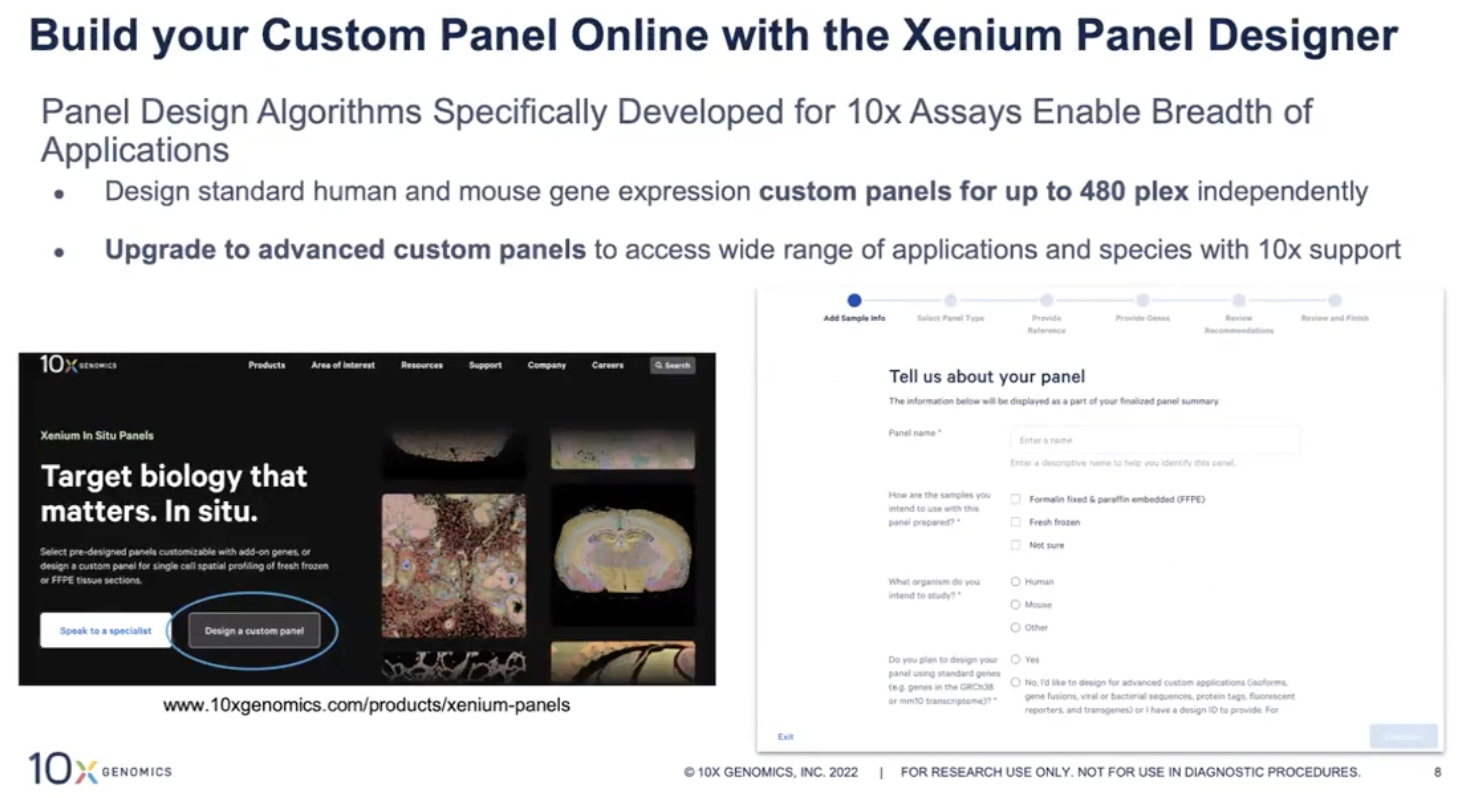
- 人类和小鼠两个物种的标准基因Panel设计包括可以有两种方案
- 如果老师是基于人类和小鼠已有的Pre-design Panel增加基因,老师就可以用直接用Designer网站进行自行设计
- 如果老师不用10x提供的人类或小鼠的Pre-design Panel的,而是想要全定制人类或小鼠的基因Panel,这种情况下老师也可以用Designer网站进行设计
- 目前来说,各位老师暂时不可以自行设计其他二倍体物种的基因Panel,而是需要通过Designer网站,向应用生信团队提交其他二倍体物种Panel的设计请求,应用生信团队会跟老师们一起进行设计
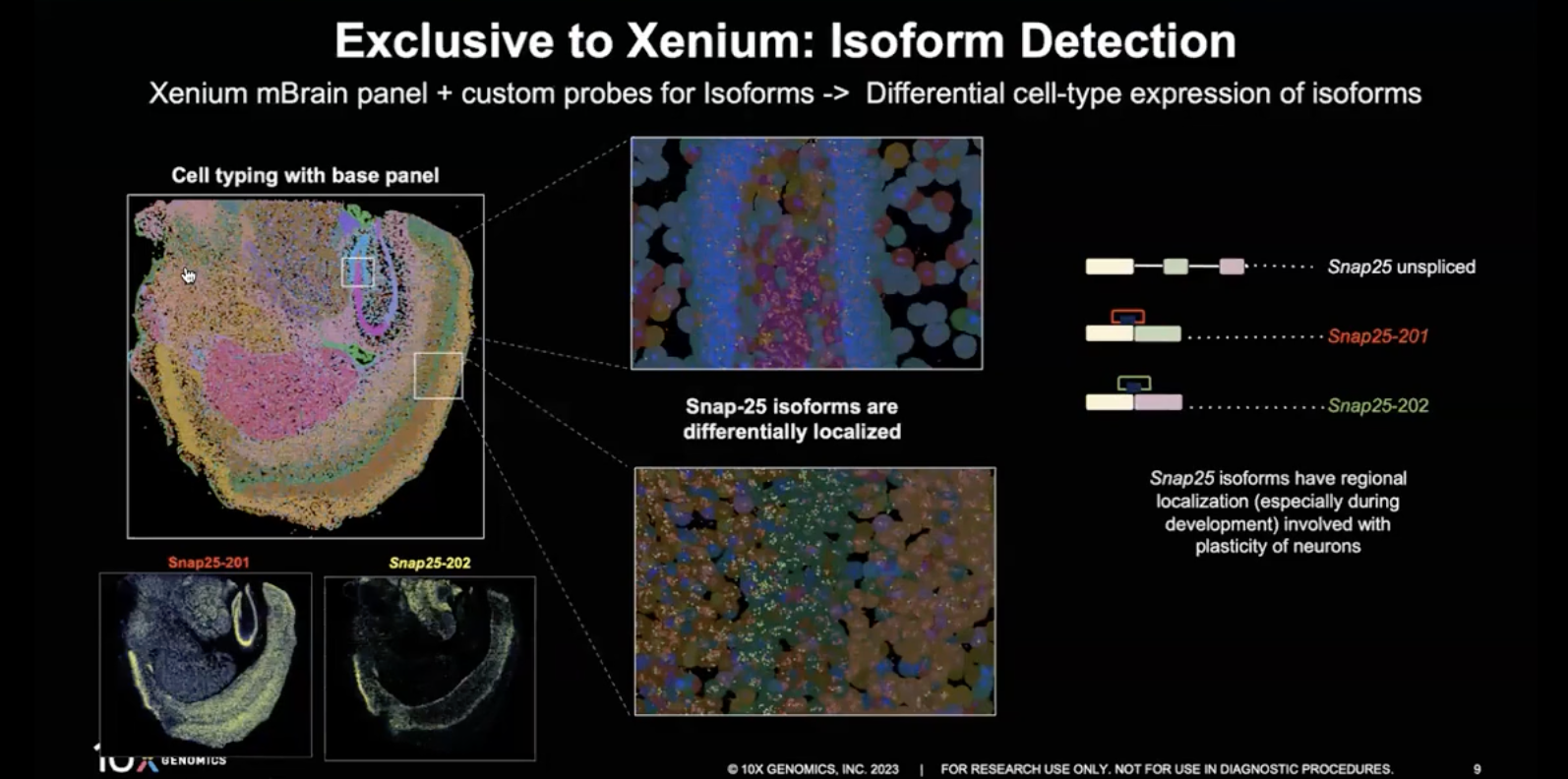
- 除了上面的提到的标准基因的Panel设计以外,Xenium也可以支持其他的高级应用,包括探测一个基因中不同的isoform;如果老师想要设计探测某一个基因不同的isoform,Xenium已经支持这些探针的设计
- 比如上图可见Xenium可以探测出基因SNP25不同的isoform在小鼠脑组织里面的表达情况
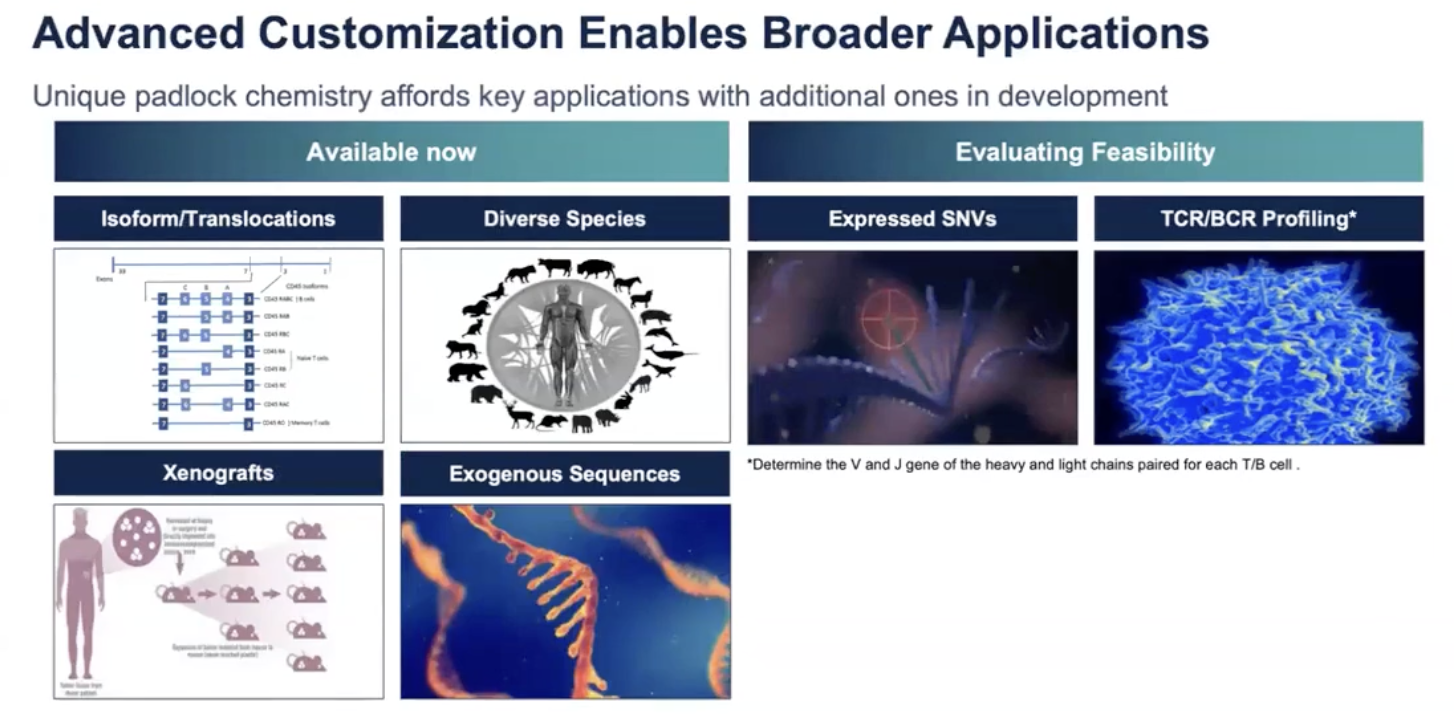
- 上图可见,在isoform之外,我们也可以针对Fusion Genes、Xenograft,比如荧光素酶报告基因、病毒、细菌等高级应用的Panel进行设计;此外,虽然Xenium目前不正式支持SNP、TCR和BCR的Panel设计,但如果老师对这两类应用比较感兴趣,也可以与10x团队联系,讨论老师的方案的可行性。

- 总结:如果老师感兴趣的人类小鼠的标准基因的Panel设计,无论是对Pre-design Panel增加基因,或是全定制人类或小鼠的标准基因设计,老师都可以直接在Xenium Panel Designer的网站上自行设计,在设计结束之后老师可以拿到一个Design ID,老师们可以通过这个Design ID与销售或者经销商进行联系,下单后Panel就会送去生产
- 如果老师们关心其他的物种包括Xenograft,老师们需要跟销售或者经销商进行联系,拿到一个Design ID并下单,然后在Design的网站上用对应的Design ID提交其他物种的Panel设计的请求,应用生信团队会跟老师联系,进行Panel设计
- 为了设计其他物种的探针,老师需要提供这些物种的参考基因组文件,并且只需要提供这些参考基因组文件就可以了。这也意味着老师所研究的物种需要有高质量的参考基因组信息;
- 此外,如果老师想要加入其他的高级应用,比如isoform、Fusion Gene、外来性基因如报告基因,以及细菌和病毒的序列等等,跟之前提到的其他物种的Panel设计的流程是一样的,老师需要跟销售或者经销商拿到一个design id,下单后,在designer网站上用获得的design id提交高级应用的设计请求。
- 此前提到的SNP、TCR BCR目前不提供正式的技术支持,如果老师对这两类感兴趣,老师可以与生信支持团队取得联系,讨论研究项目的可行性。

- 10x提供了不同的工具供各位老师对Xenium Panel进行选择和设计
- 首先是两个重要的文档,强烈推荐各位老师去阅读这两份文档,了解Panel整个Panel设计流程
- 此外,10x提供了Xenium Panel Selector Tool,在这个Tool里面老师可以提供感兴趣的所有基因,这个Tool会输出老师感兴趣的基因与不同的Pre-design Panel有多少交集,这样可以帮助老师选择合适的Pre-design Panel并确定要增加的基因数量
- 最重要的工具就是我刚才提到的Xenium Panel Designer,用户可以通过这个网站自行设计人类和小鼠的标准基因Panel,包括对Pre-design Panel里面增加基因。或者是全定制的人类或小鼠的标准基因的Panel

- 首先是老师们想要研究的基因列表文件,如果是基于Base Panel额外增加基因的,老师需要准备额外想要添加的基因;如果是人类或小鼠全定制的Panel,那老师需要准备全定制Panel里面的人类或小鼠的全部基因
- single cell数据:single cell数据有助于帮助10x评估所提供的基因在相应的组织状态下的表达量,首选的是10x的单细胞数据,可以是5’的,可以是3’的,也可以是flex的
- 如果老师们只有Visium数据,没有single cell数据,老师也可以先通过Space Ranger2.1版本分析老师的Visium数据,Space Ranger2.1版本可以提供reference free deconvolution帮助老师们更好的进行Spot细胞类型的注释
- 10x推荐单细胞数据最好是来自于相似的组织状态,比如老师要研究Xenium研究人类乳腺癌组织,那单细胞数据最好也是来自于人类乳腺癌组织的,如果老师已经产生了相关研究组织的单细胞数据,10x会强烈推荐老师直接使用老师产生的单细胞数据做评估,这类单细胞数据可以提供更准确的基因表达评估,有助于更准确的Xenium Panel设计的优化
- 如果老师没有相关的单细胞数据,Designer网站已经预备了一些单细胞数据参考数据,考虑到有限数据的局限性,老师也可以选择从一些公共平台上下载单细胞数据作为参考,当然所有提交Designer网站上的单细胞数据的文件格式一定要符合10x MEX或者是H5文件的格式,这两个文件的格式都是Cell Ranger产生的文件的标准格式,老师可以参考CellRanger的官网了解这两个格式的具体内容
- 此外,关于单细胞数据有两个非常重要的点:
- 老师提供的单细胞数据的细胞基因矩阵GeneCell Matrix需要是Raw UMI Counts,不需要也不能对数据有任何形式的Normalization,这是因为Designer的算法在设计过程中就有自己的Normalization
- 老师们请避免对细胞基因矩阵GeneCell Matrix做基因筛选,而是要提供完整的Gene Cell Count Matrix,比如老师要设计100个基因,但真的不能只提供这100个基因的GeneCell Matrix,而是要提供全部基因的GeneCell Matrix,Designer的算法需要每一个细胞里面所有基因探测的UMI总数,如果老师事先做过了基因的筛选,然后把一个筛选后的Matrix给10x,这会严重影响细胞总的UMI数量的计算,进而严重影响Panel设计的评估
- 除了单细胞的GeneCell Matrix之外,老师还需要额外提供单细胞数据的细胞注释结果文件
- 如果老师想要设计外源性基因序列,比如说外源性的报告基因,或者是其他的病毒序列、细菌序列,这些就是刚才提到的高级应用,那老师需要跟应用生信团队共同合作和完成,老师需要准备这些外源性序列给10x生信团队,然后生信团队可以帮忙去设计这些外源性序列的探针

- 为什么Panel设计需要单细胞数据Single Cell数据?
- Xenium是基于Imaging的,通过成像结果的亮点来区别不同的RNA分子;如果一个基因表达量非常非常高,那这个基因成像出来的结果就是整个细胞区域就高亮一片,在这种情况下就不能够非常准确的区分出每一个RNA分子。
- 基于目前的Xenium成像需要的cycle的数目,一个特定区域里面能够准确探测出的亮点数目不是无限量的,而是有上限值的。10x需要通过单细胞数据定量了解哪些基因是高表达的,这样在设计探针时,就可以把这些高表达基因的发光的Cycle尽可能远离开来,比如说基因一和基因二都是高表达的,那在设计时10x就会希望让基因一在1-5个Cycle中发光,而基因二在6-10个cycle中发光。那这两个基因的表达就不会相互干扰了。
- 此外,10x也要通过了解哪些基因是特别高表达的,进而(可选)去除这些基因或者是降低这些基因的探针组数
- 总结来说,10x需要单细胞数据去定量每个基因的表达情况,但是又由于同一个组织在不同状态下的基因表达情况会发生变化,所以在选取单细胞数据的时候要尽可能选取相似组织类型的单细胞数据。比如说如果老师打算用Xenium探究人类乳腺癌组织里面的基因表达情况,但是老师在设计的过程中却提交了健康的人类乳腺的单细胞数据那老师的设计的结果就可能不是非常准确。
- 如果老师有自己的单细胞数据,10x会全力推荐老师直接用自己的单细胞数据进行评估;如果老师没有自己单细胞数据老师可以去一些公共平台比如说CellXGene,GEO DataSets等等;老师也可以去Design的网站,网站上会提供一些单细胞数据,老师可以看看这些数据是否符合老师想要研究的组织形态。
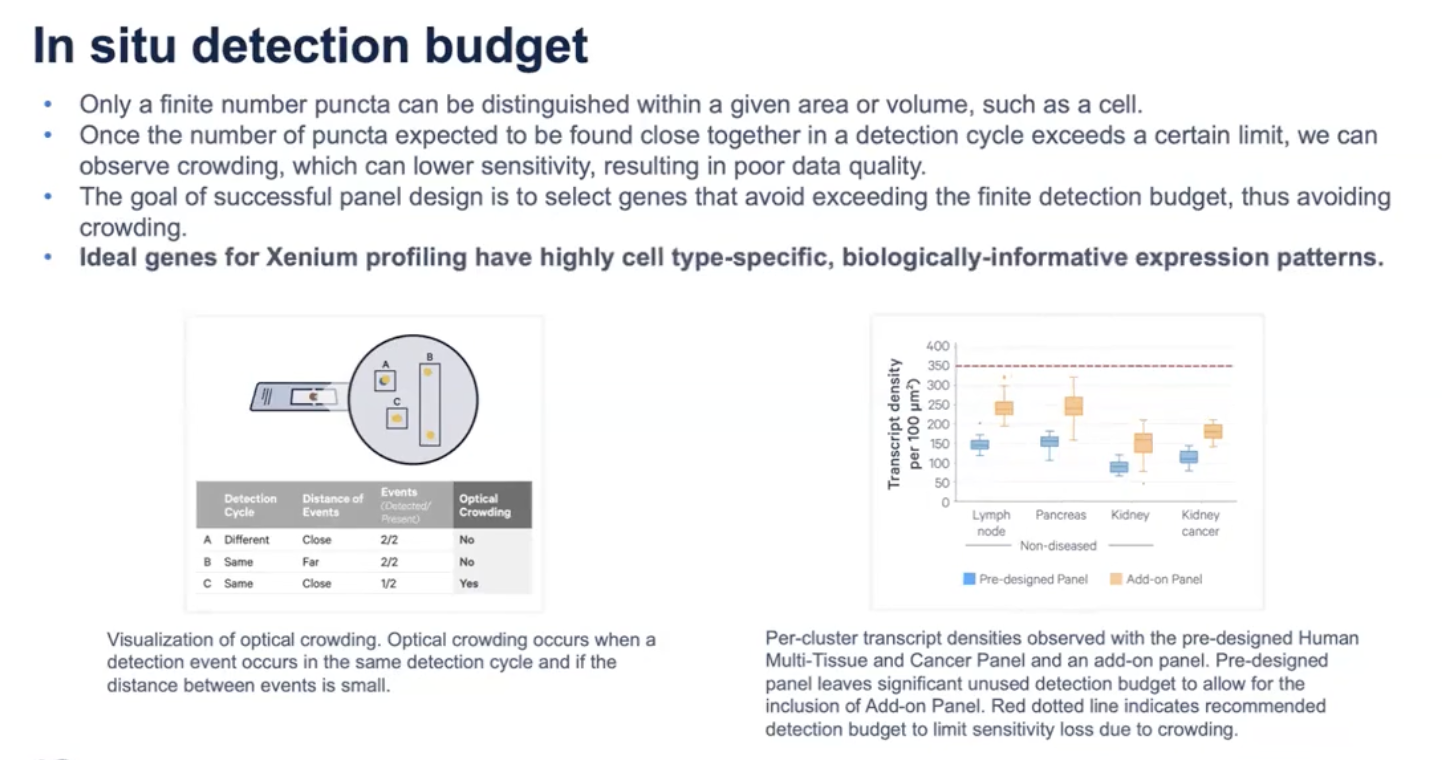
- 在单个细胞中,Xenium能够探测出来的亮点数是有上限值的;如果对于同一个基因的两个RNA,它们彼此挨得很近又同时发光,这就有可能发生所谓的“视觉拥挤”现象,会使基因的探测灵敏度下降,影响到数据质量;所以一个好的panel的基因列表是可以得到优化的,使得每一个cycle channel里面发光的RNA分子亮点数不会超过探测上限值。
- 在设计base panel时,10x考虑有考虑到检测的上限值,pre-design panel包含的基因都经过筛选,所以一般来说每100平方微米推荐的探测RNA数目上限值为350;大家可以看右图中的蓝框的就是pre-design panel,其实只占据了一部分的RNA探测值,预留了很大的一部分;这个预留空间可以为后续用户想要增加最多增加100个基因时,预留的空间可以为额外增加的基因服务;
- 总结来说,在panel设计过程中,首要任务就要寻找高表达的基因,而10x需要通过单细胞数据来确定基因在不同组织中的表达情况;10x的单细胞的数据已经被证明跟Xenium有非常好的线性正相关,也就是在10x的单细胞数据里面观察到的基因的表达量可以很好的去预测在Xenium中真实反映出来的基因的探测趋势。
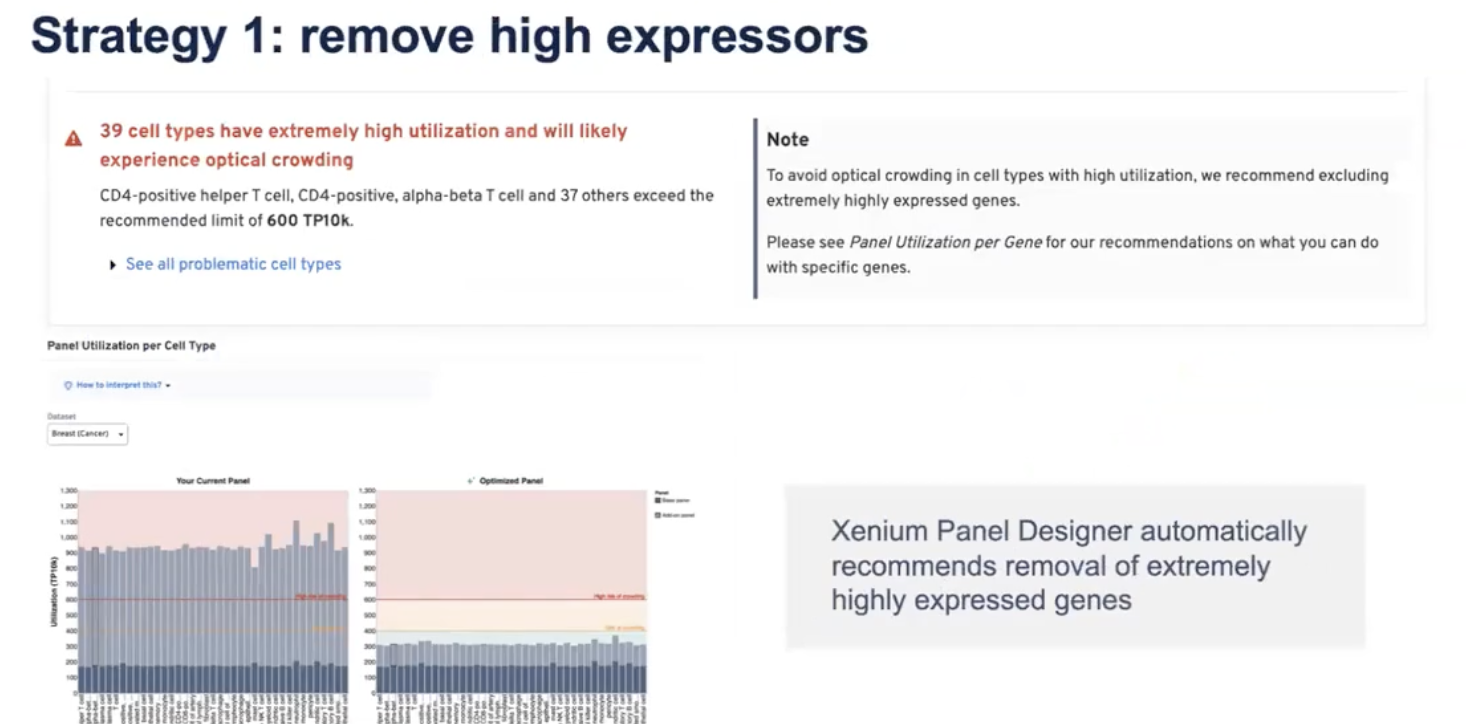
- 如果通过单细胞数据发现有些基因高表达,有两种办法
- 首先,如果基因的表达量非常高,那么就可以直接去除掉这些基因;老师可以通过两个指标,即整个panel的利用值和每一个基因的利用值
- 如果一个基因的表达量不是非常高,而只是略高,那老师可以选择去降低这个基因的探针组数;降低探针组数虽然会造成相关基因的探测灵敏度降低,但是可以避免视觉拥挤的发生,进而保证数据的质量。
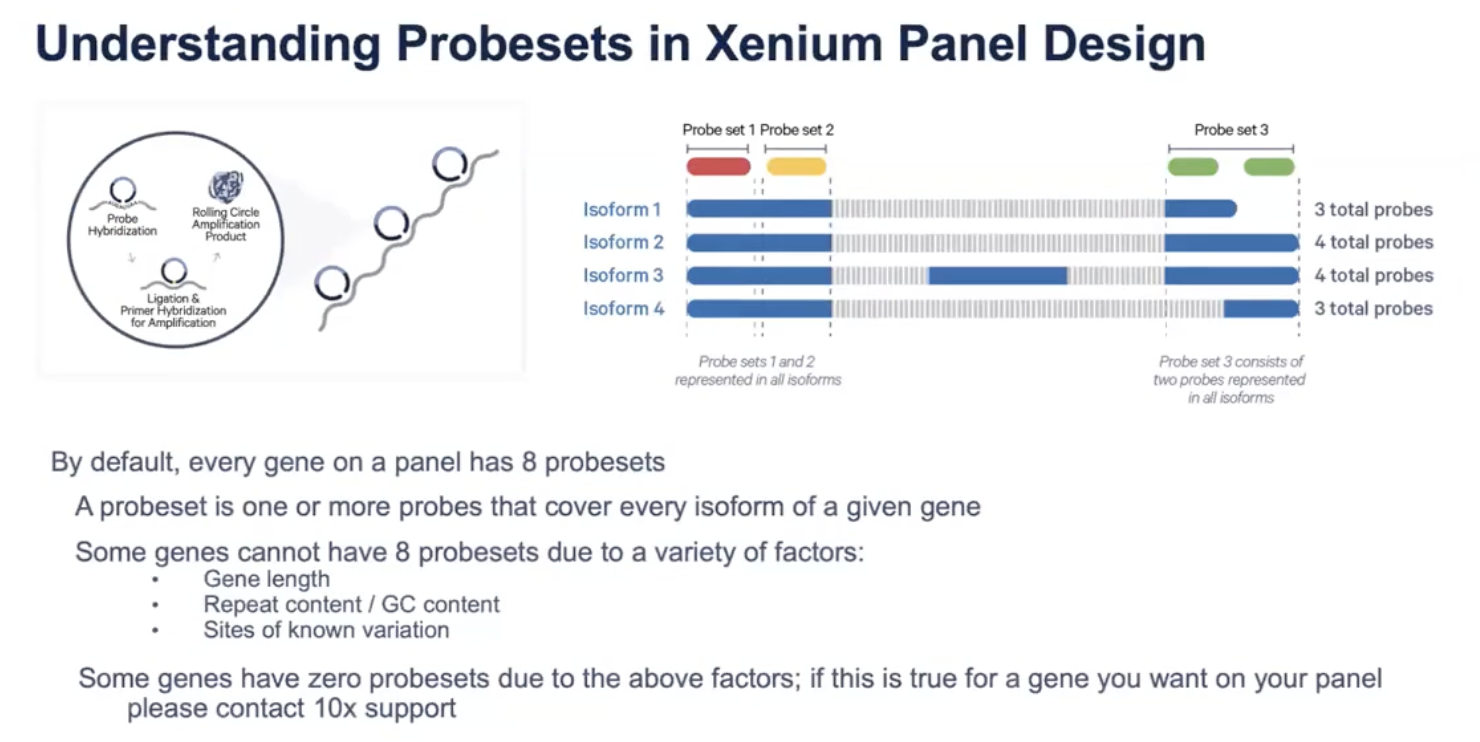
- Xenium中大部分的基因都涉及8个探针组,注意不是8个探针分子。一个探针组表示在这组探针可以覆盖一个特定基因里面的所有isoform,所以如果一个探针组里面一个探针不足以覆盖所有的isoform,那么更多的探针就会被设计出来直到所有的isoform被覆盖。所以一个探针组可以有一个探针,可以多于一个探针
- 有些基因由于长度的限制,或者基因内部碱基的限制,是不能够设计8个探针组的,也就是说并非所有的基因一定会有8个探针组,有些基因可能会少于8个探针组

- 探针组的数目跟基因探测的灵敏度大致成线性关系,降低探针组数也会线性降低基因探测的灵敏度,一般来说,10x推荐一个基因设计至少3个探针组;如果3个探针组依然对应着比较高的视觉利用度,那可能代表这个基因的表达量很高,这个基因如果对老师来说很重要,可以试着选一下两个探针组或者是一个探针组。

- 如果老师想要去设计人类或小鼠的标准基因Panel,老师可以在pre design panel里上面加基因,或者是全定制人类或小鼠的基因Panel;老师可以到Xenium panel design的网站上自行进行设计或者是对人类或小鼠的基因做全定制的Panel设计
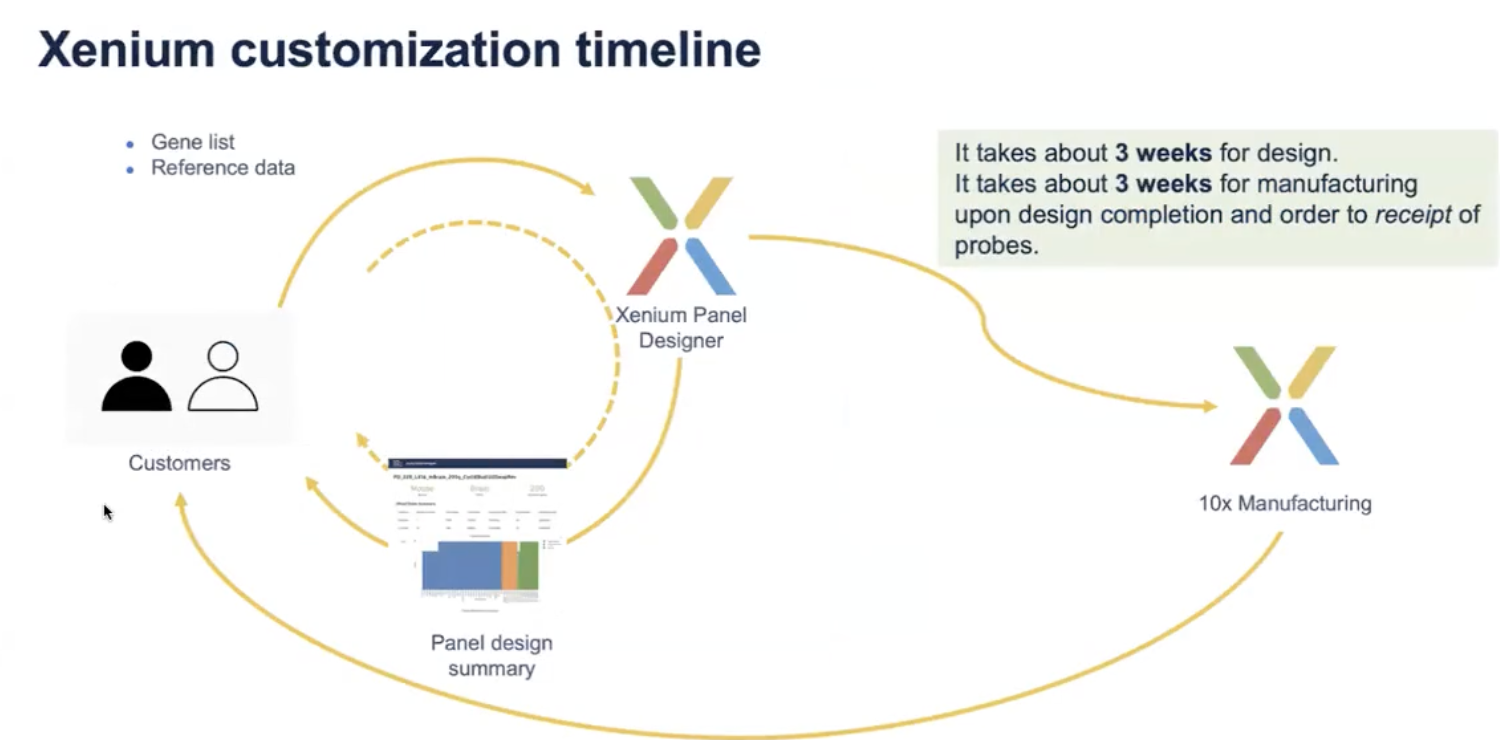
- 如果老师对其他的二倍体生物或者高级应用感兴趣,包括isoform,外源性报告基因以及病毒和细菌的序列测量,老师也可以通过刚才介绍的Xenium panel designer的网站来上传请求,不同的是这些panel会有应用生信团队全程参与设计,一般的设计周期为三周左右,如果所有要求的文件都能够及时提供,设计时间可以会短一点,设计后生产时间也差不多为三周左右。
Xenium Panel设计实操
- 进行Xenium Panel设计前,大家首先需要在cloud.10xgenomics.com注册,如果已经有注册好的邮箱以及密码,那可以直接进入
- 在点击”Go to Xenium Panel Designer”后,即可进入下面的页面
- 在演示过程中,我们可以看到这样发的表格:
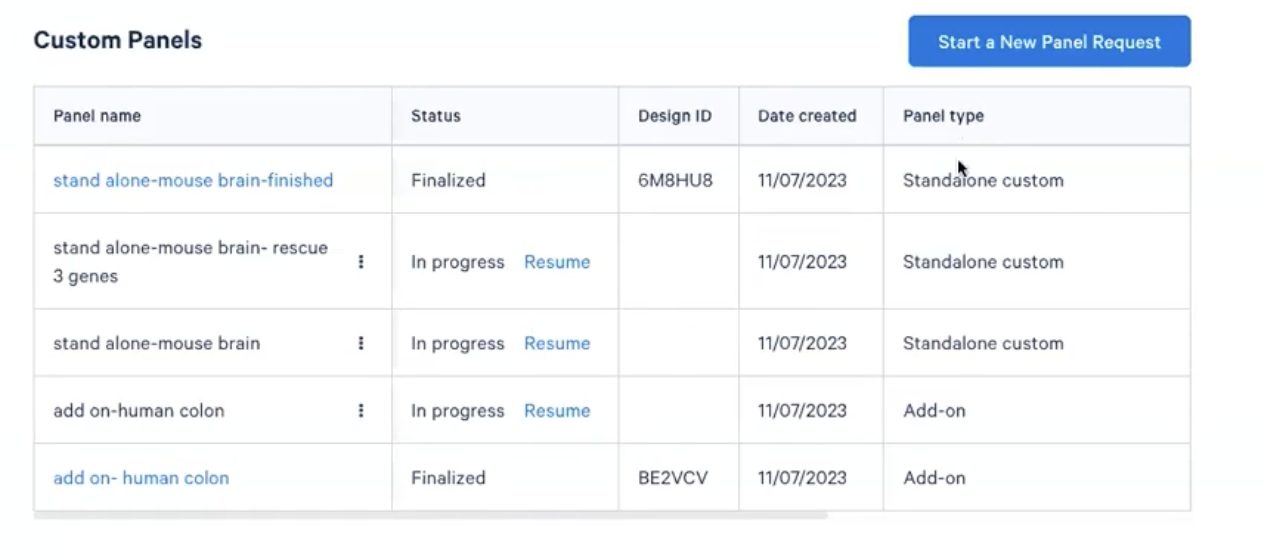
- 我们可以看到panel的名称,panel所处的状态(设计中in progress/已完成finalized)
- 如果panel已经设计完成,那我们可以看到对应的Design ID,我们可以根据这个ID去下单
- 此外,我们还可以看到定制开始的日期和panel的类型(全定制/增加基因)
- 在这个课程中,我们会展示两种类型的panel设计,一种是在10x预先设计的商品化的panel,也就是pre-design panel,老师们可以在这个基础上额外添加最多100个基因的panel设计,这种在panel type中称为add-on,另外一种是完全的从头定制,最多可以包含480个基因的这种panel设计,panel typr中被归类为standalone custom design,除了这两种panel设计之外的其他panel设计统称之为高级的panel设计,需要提前联系销售同事获取design id方可进行后续的操作。
- 首先进行add-on panel设计的操作演示,可以点击start a new panel request
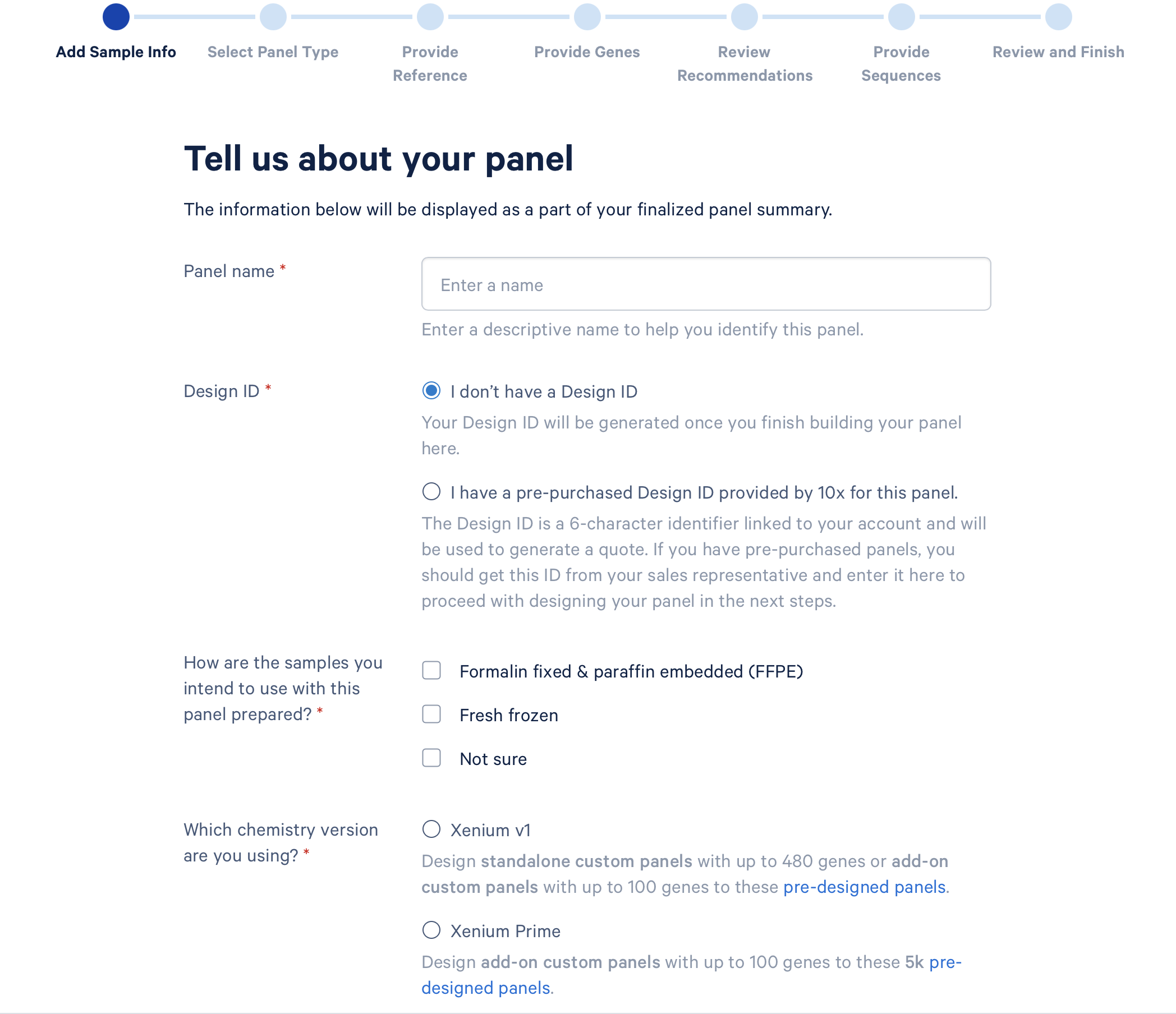
- 上图的界面展示的是panel设计包含的所有步骤,我们可以按照这个路径一步一步往下进行
- panel name:这里最好是描述性的名称,比如add on human colon-100genes
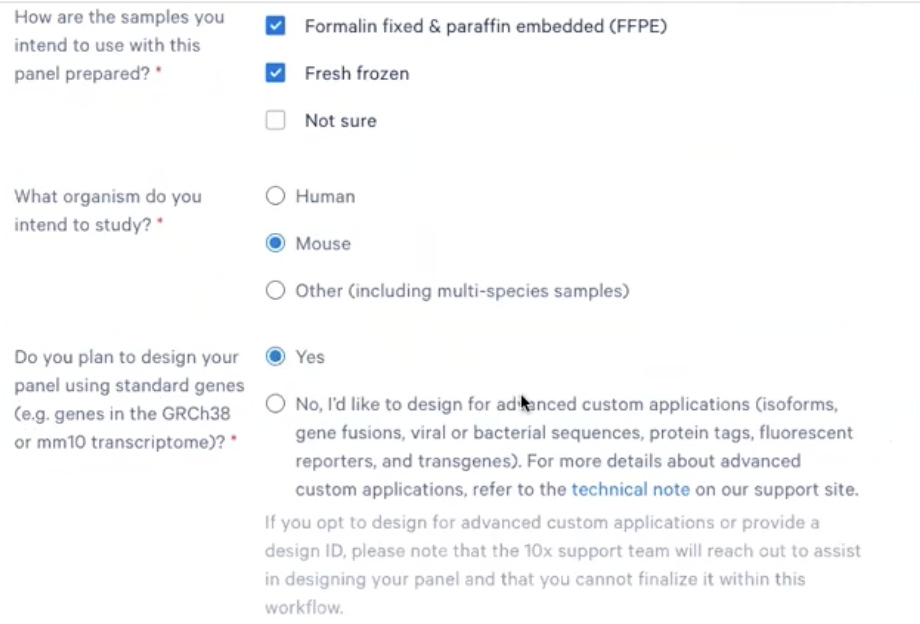
- 要用于哪种样本类型:可以同时或单独选择FF和FFPE,也可以选择Not Sure,但这里一定要选
- 物种:人(ID可选)/小鼠(ID可选)/其他物种(一定要有Design ID)
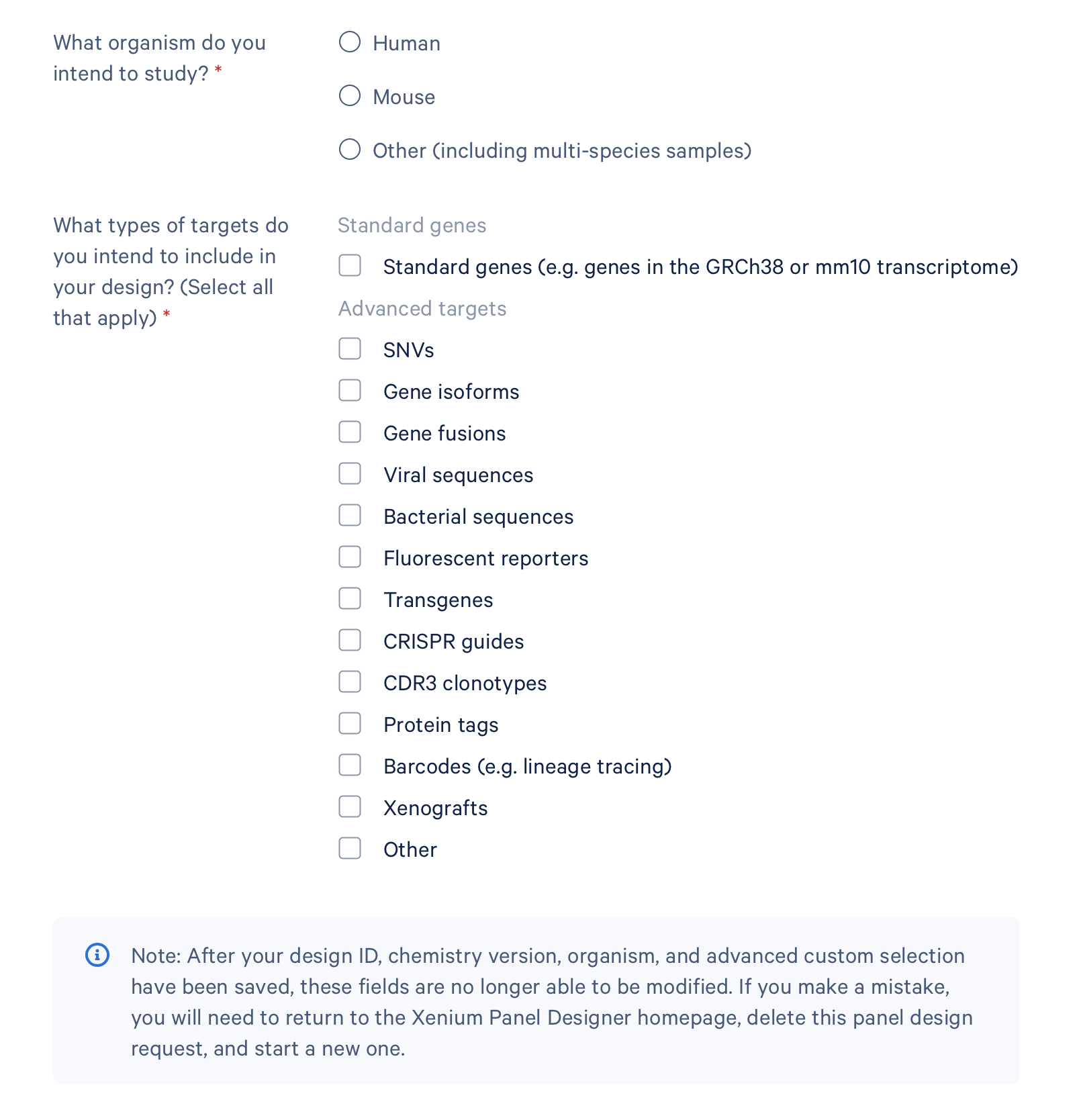
- 页面向下滚动,我们要开始选择定制的检测目标,普通的基因,还是各种高级定制的内容,比如针对于单核苷酸多态性,mRNA的剪接异构体,融合基因,病毒以及细菌的检测,蛋白标签序列的检测、荧光报告基因的检测,甚至于移植瘤的检测
- 红色的星号是必填内容,不能空。
- 接着,进入第二页,我们需要选择进行panel设计的类型
- 对于add on,我们需要选择基因数量,是1
50个基因还是51100个基因,这里需要各位老师根据自己的实际情况进行选择,点击continue后就要进入参考数据了。
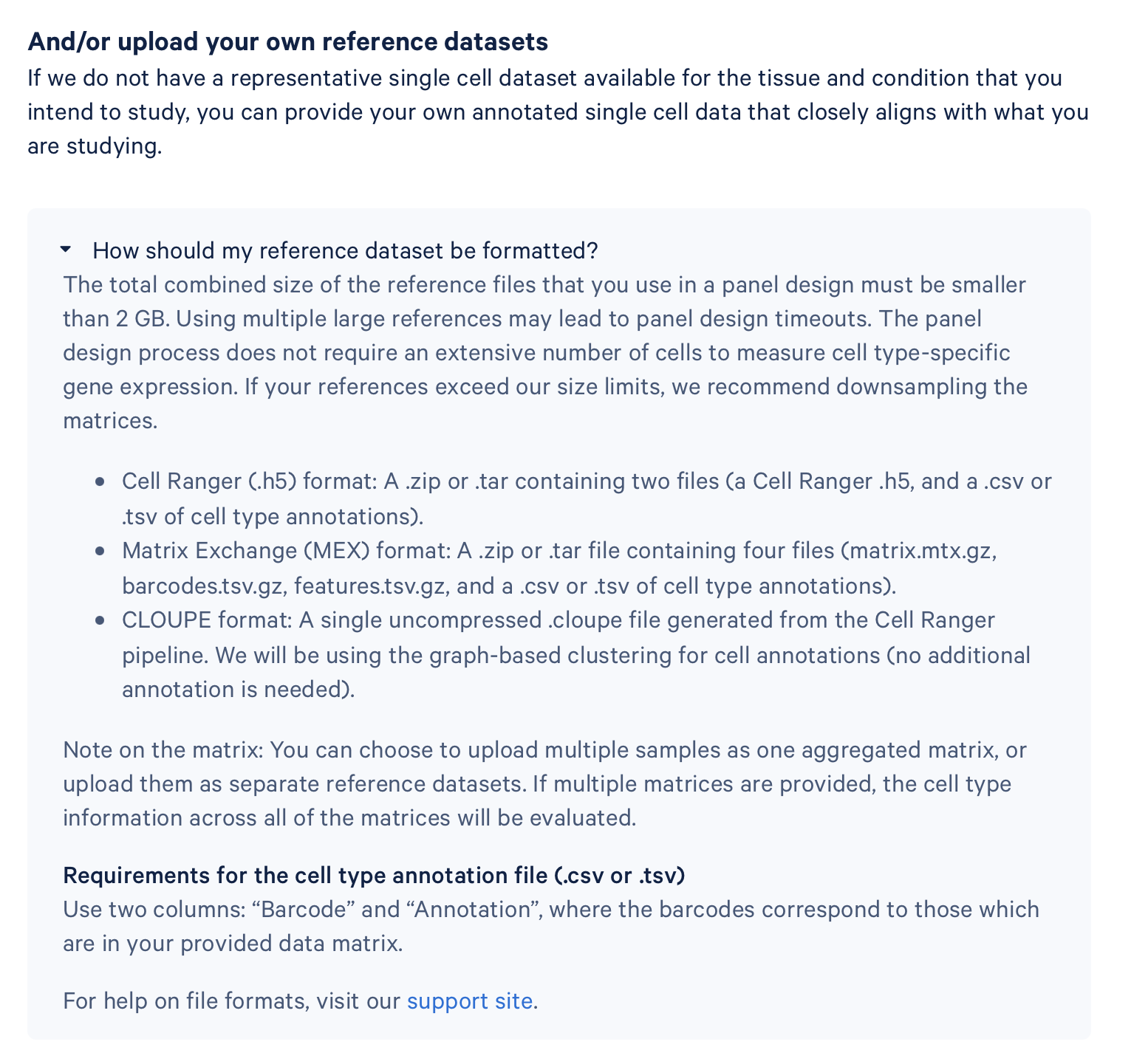
- 正如上一部份介绍的,10x预先提供了一些参考的数据,请老师们根据自己的需求进行选择,如果老师们要提交自己的数据,请老师们上传一个zip压缩包,内容包括由Cell Ranger自动生成的
- matrix.mtx.gz
- barcodes.tsv.gz
- features.tsv.gz
- 还有细胞注释的annotation文件,细胞注释文件需要有两栏,有各自的表头,分别是细胞的barcode和细胞类型的注释,比如下图这样就可以了

- 上传需要一点时间,最多可以上传5个zip文件,上传文件的合计空间大小不要超过500MB

- 接着,我们还要选择上传的组织的类型,以及样本来源的信息,比如是否处于疾病的状态

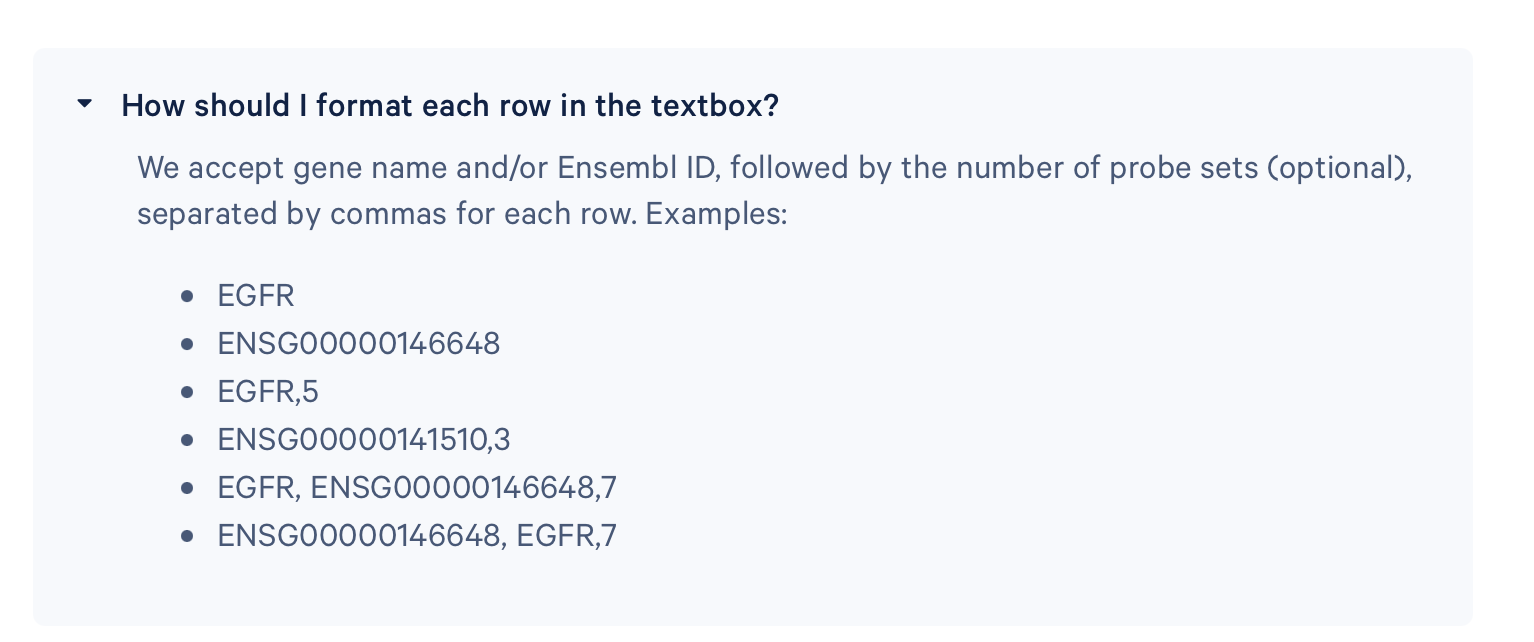
- 进入第4步,这里我们需要添加基因的信息,这里有三个给大家的一个小提示,我们可以输入基因的名称,也可以输入Ensembl ID的名称,也可以既有基因的名称也有Ensembl ID的名称,后面的数字代表预先希望这个基因被设计多少对探针
- 此外,我们会希望这个list上的基因排列按照重要性由高到低的顺序,也就是最关注的基因放在最前,最不重视的基因放在最后
- 10x建议各位老师在100个基因的基础之上,多输入10到20个作为备选,一旦前100个基因里面有一定数量的基因因为optical clustering的问题被剔除掉了,算法就会从10到20个基因里面补充一些数量的基因,保证最终达到100个基因。
- 还有一条要求,就是基因的ID或者基因名称应该有唯一性,并且这个名称来源于参考基因组,可以参考Ensembl最新的发布格式。
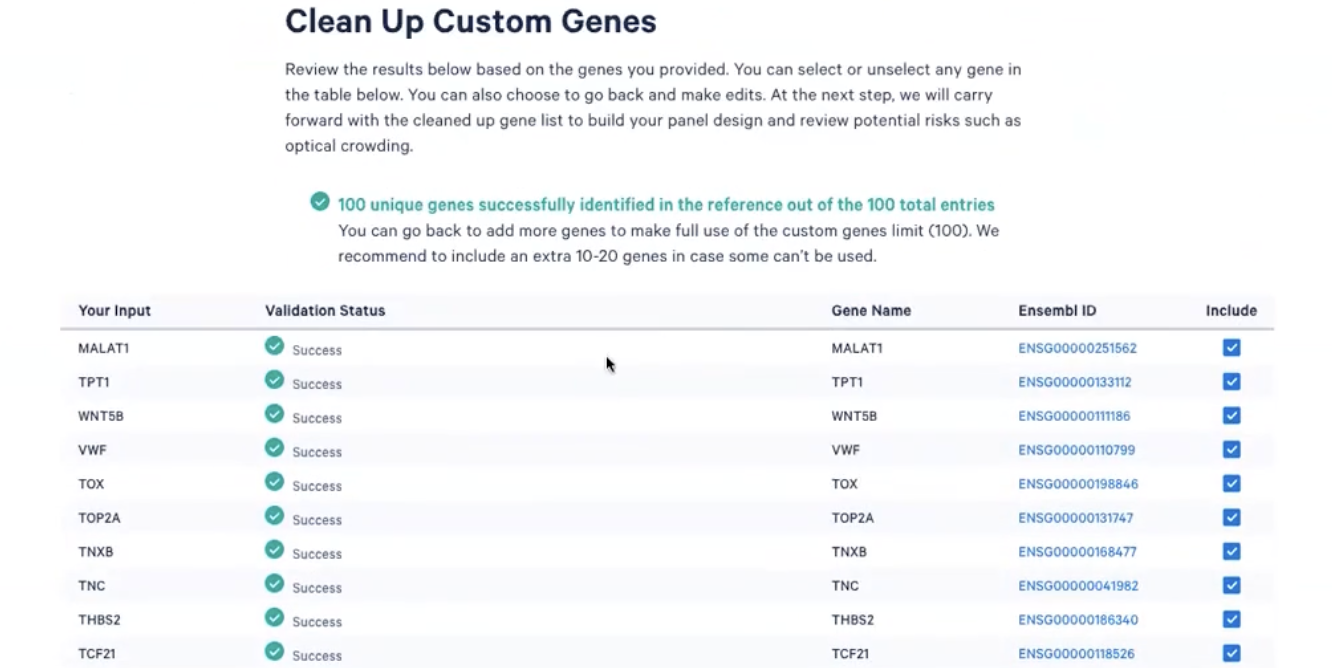
- 在我们输入基因后,系统会对我们输入的基因进行校对(比如是否和参考基因组中的内容对上,Ensembl ID等),校对完成之后才能进行下一步的操作
- 我们可以在这一步中,最后一次对基因进行确定,需要的基因在Include中打”✅”,不需要就空着
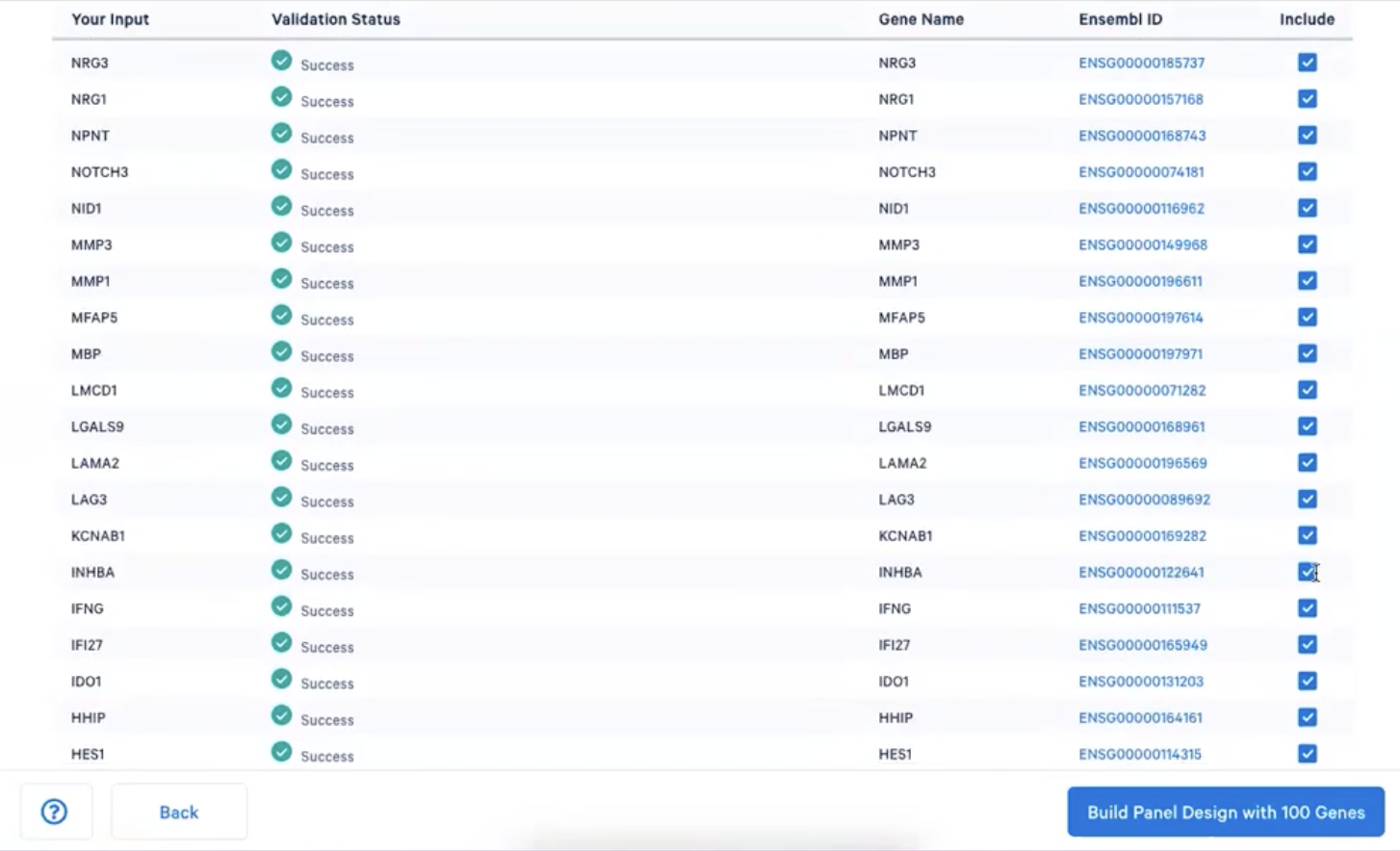
- 如果老师们已经确定感兴趣的基因核对无误,那就可以点击页面下方的”Build Panel Design with XX Genes”(XX为基因数目),之后需要等待一段时间让计算机的算法去完成对应的工作,如下图所示
- 程序分析完之后会显示如下的页面:
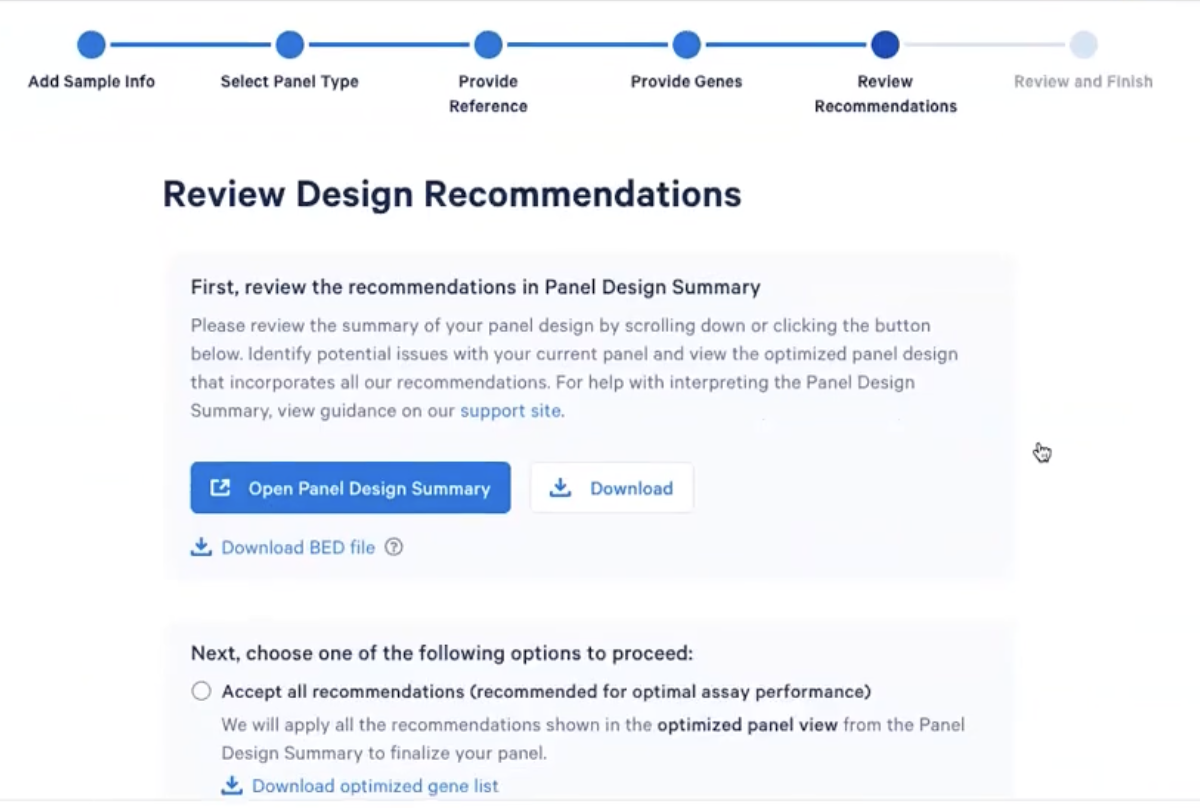
- 程序分析和设计完会展示出这样的结果:页面首先展示review,review部分是10x对我们设计的panel的建议,对此我们有如下的三种选项
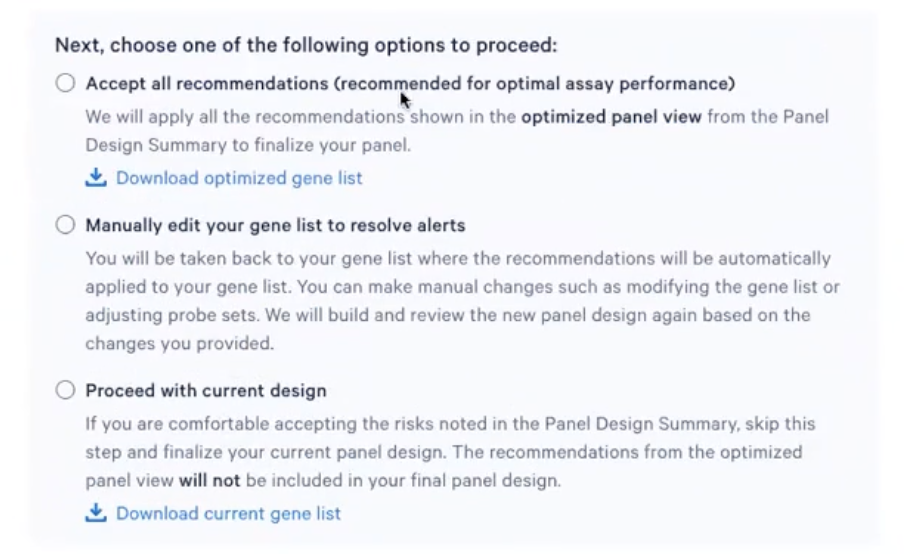
- 首先,老师们可以全盘接受10x给的建议,可能会存在一些基因被删除,或者有些基因的探针对数目被降低了;如果老师们想要知道哪些基因被修改了,可以点击”download optimized gene list”去下载修改后的表格
- 其次,老师们还可以选择手动去修改gene list,逐条审阅10x给出的建议,并且直接在之前提交的版本上进行修改(比如老师们如果认为10x的算法剔除了某个真的很重要的基因,就可以通过手动edit的方法去添加)
- 最后,老师们当然可以完全忽视10x给的意见,按照之前的设计去进行panel的定制
- 在做出决定之前,我们还是可以看一下Xenium Custom Panel Design Summary,如下图所示
- 首先我们会看到一个叫Panel Utilization per Cell Type的参数
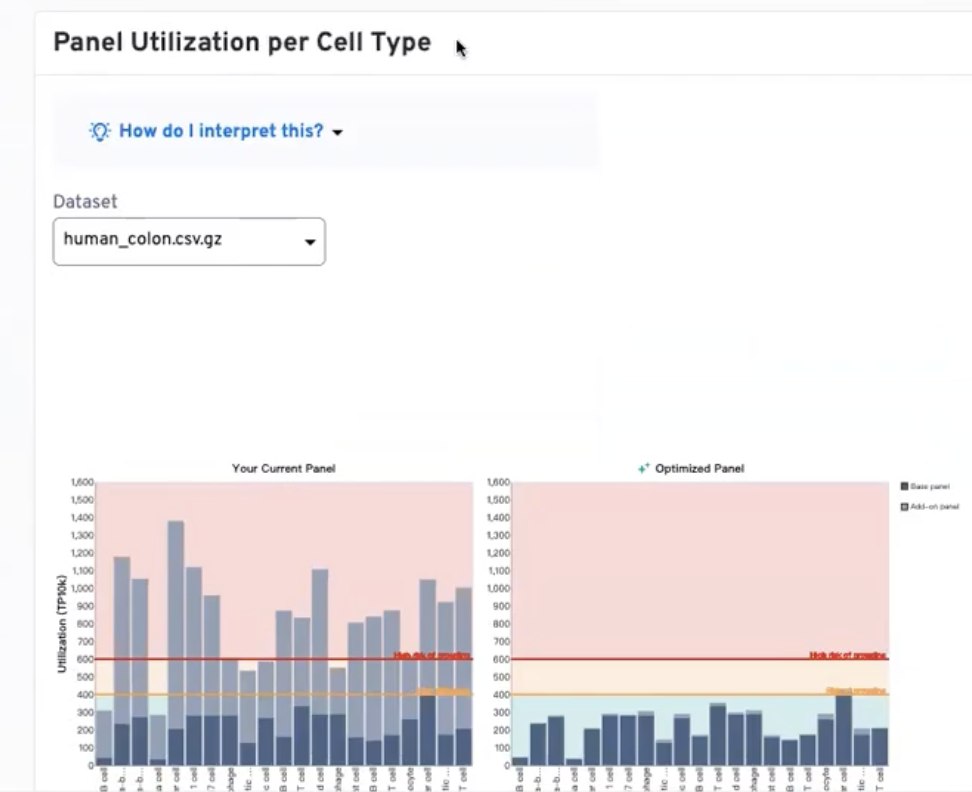
- 对于每一个我们选择的数据集(无论是10x官方提供的,还是老师们自己上传的),左边的图是没有经过10x算法处理的(也就是老师们原本上传的),而右边是经过了10x算法优化了的。
- 对于每个图,横坐标是细胞类型,纵坐标是TP10K,是10x在设计Panel时获取的一个经验性的指标;一般来说,10x希望各位老师在设计panel时,每个细胞类型的TP10K避免超过400,如果一定要超过400,那也一定不要超过600

- 对于示例中的人肠道panel,如果按照直接设计,也就是不参照10x给的一些建议,在下图中深蓝色的是Pre-design Panel的TP10K数值,而浅蓝色的部分是add-on基因产生的TP10K类型,两者相加就是每种类型产生的TP10K数值,我们可以看到几乎所有的TP10K都高于400,且有很多高于600,这是我们不希望得到的
- 于是,10x根据算法进行了optimize,让老师最终看到的每个细胞类型的TP10K都没有超过600,且大部分没有超过400
- 下图所示的部分所示的内容展示了算法做了什么去避免optical crowding的情况出现

- 接着我们进入下一个参数Panel Utilization for Highly Expressed Genes,这个参数预测的是每个基因的捕获情况,图中的每个点都代表一个基因,对于单个基因而言,我们希望TP10K的数值不要超过120,超过120时Xenium设计的相关算法就会介入。
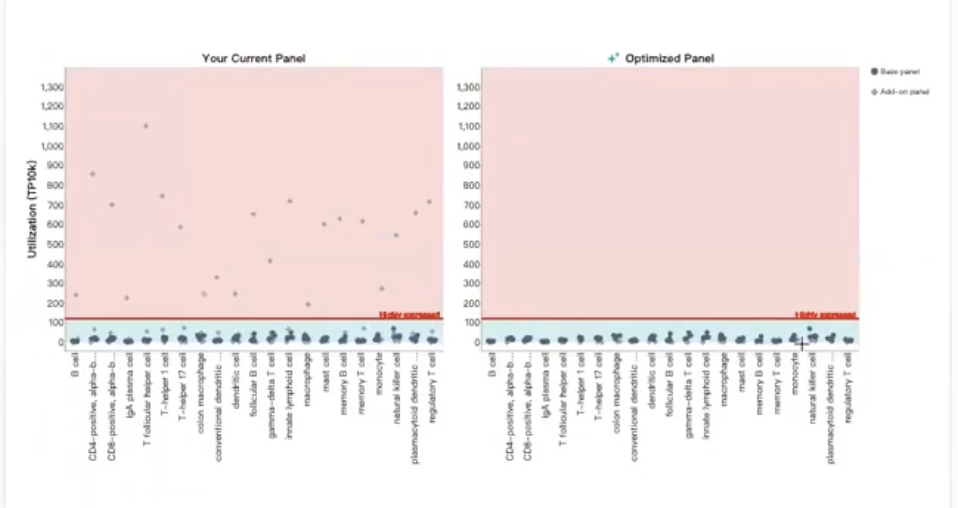
- 算法会有下述的3种处理方式
- 首先,对于表达量特别高的基因,算法会直接去掉这个基因的所有探针,也就是直接不检测这个基因

- 其次,对于有潜在optical clouding风险的基因,算法也会选择去掉

- 最后,对于一些基因,算法会适当减少探针组的数量,具体结果会显示出来,如下图所示

- 页面还会提供第三个参数Sample Cell Type Composition,这个仅对于老师自行上传的单细胞数据有展示,对于某些有optical clouding风险的基因,如果这个基因高表达的细胞类型占总体细胞的比例不高,那可能optical clouding的风险略高一些也是可以接受的
- 最后,我们可以看到Probeset Summary,如下图所示,我们可以看到每个数量的探针对有哪些基因,每个方框对应了一个基因,探针数为0的基因会被移除
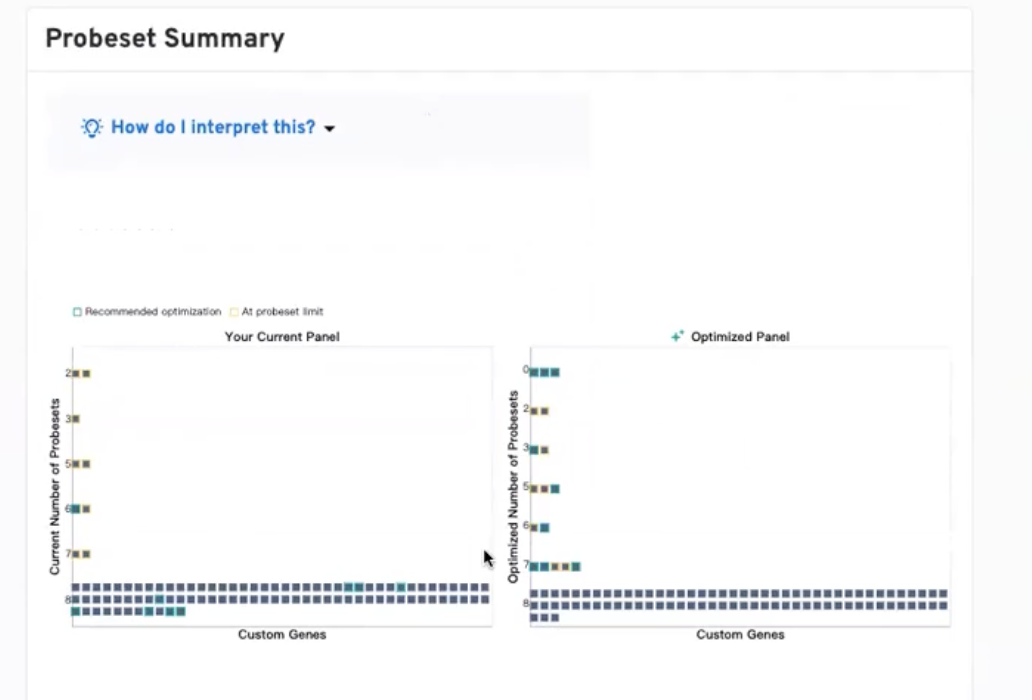

- 此外,虽然算法推荐每个基因设计至少3对探针,但对于某些基因,可能只有1-2对探针,这是因为这个基因与其他基因间的同源性过高,或者这个基因有很多重复序列,多样性很差,或者基因的区域非常短
- 最后,我们可以看到表达热图Expression Heatmap,我们主要能看到调整前后的结果能否主要区分我们想要得到的细胞类型,如果能算法处理后的结果能区分开所有的细胞类型,并且去掉的基因没有对最后的结果处理产生较大的影响,那这样的结果就是我们可以接受的。
- 在最后,当我们对算法展示出的结果进行了选择,最终会生成下图所示的网页,包含Design ID,可以点击下面的”Contact Your Sales Representative”去与销售联系进行下单
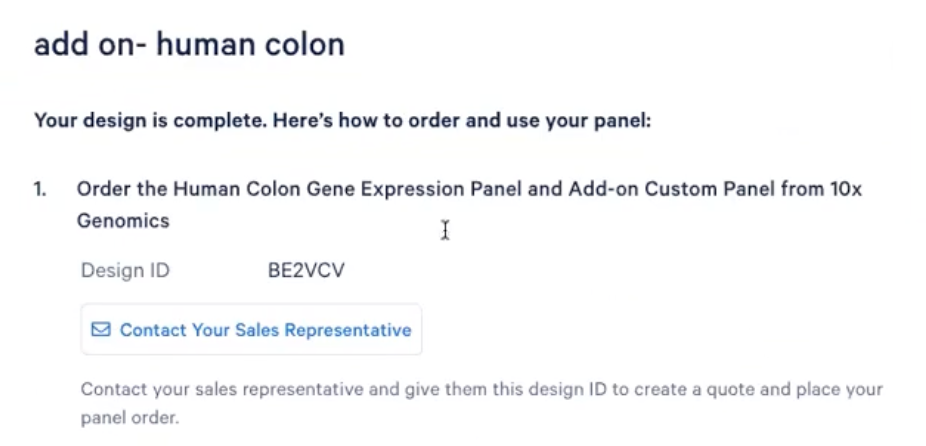
- 此外,各位老师还能看到作为用户收到的信息,比如下图所示的图片介绍了用户会收到两个panel,分别是结肠基因的表达panel和定制的panel,定制的panel有ID和涉及的基因数
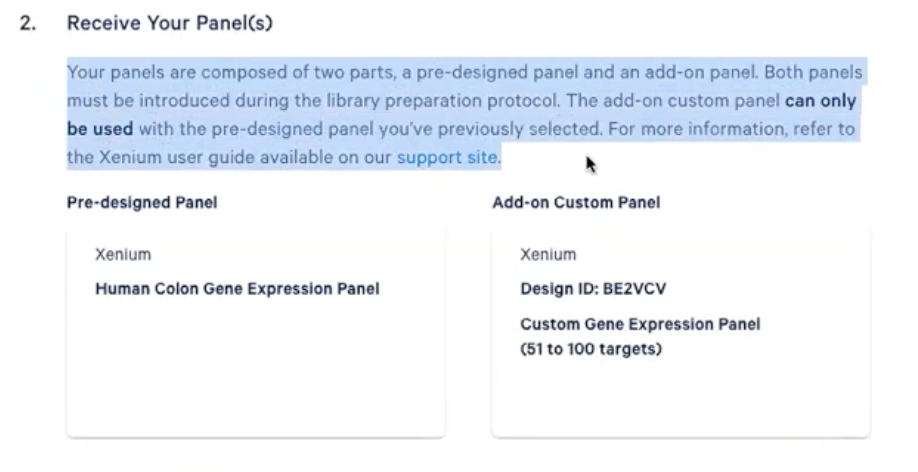
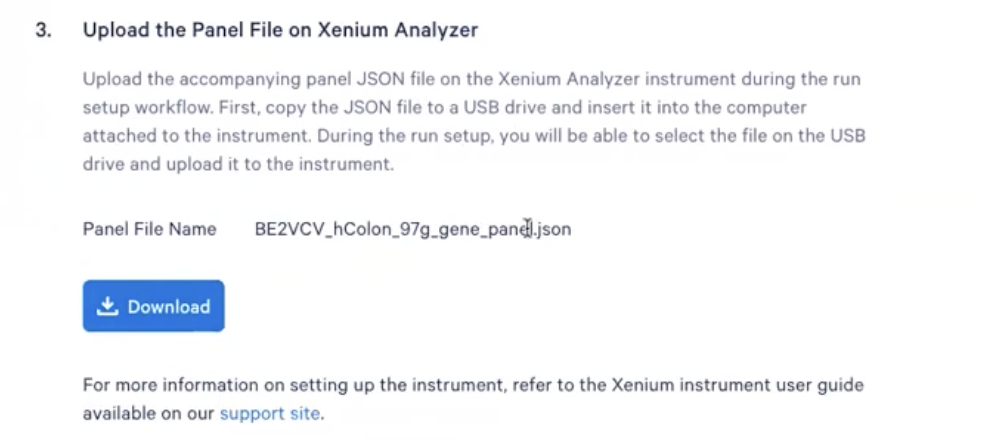
- 此外,各位老师还能得到json文件,这个文件可以直接在当前网页下载,下载后可以把这个文件导入Xenium Explorer用于实验
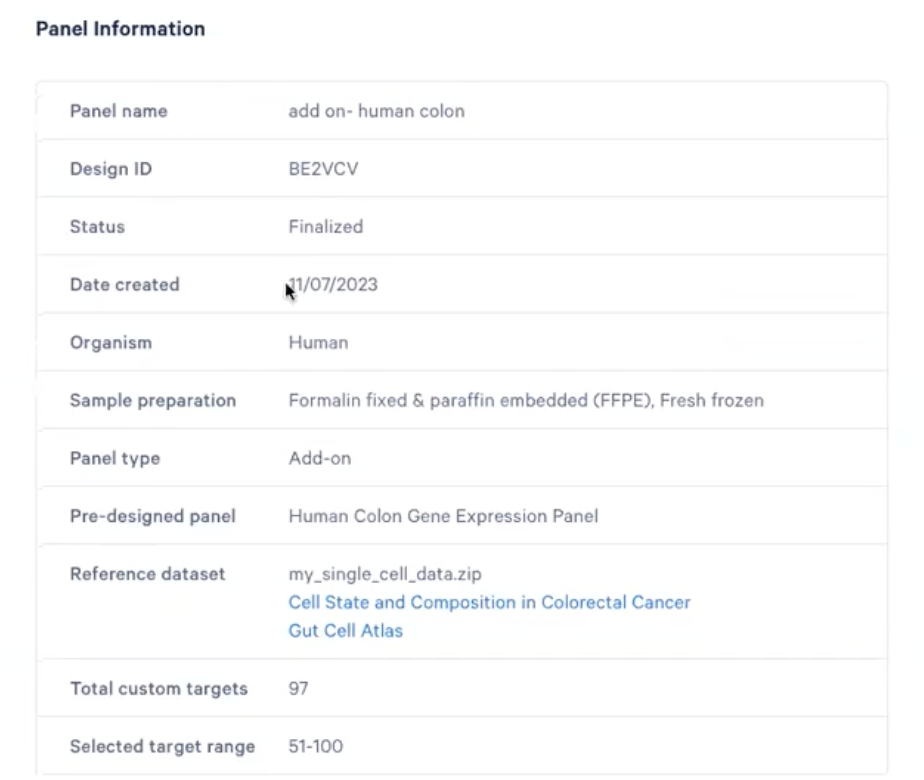
- 老师们同样可以在这个页面看到Xenium Panel的信息,如下图所示
- Xenium Panel Designer在这一步会输出一些文件,我们可以选择下载
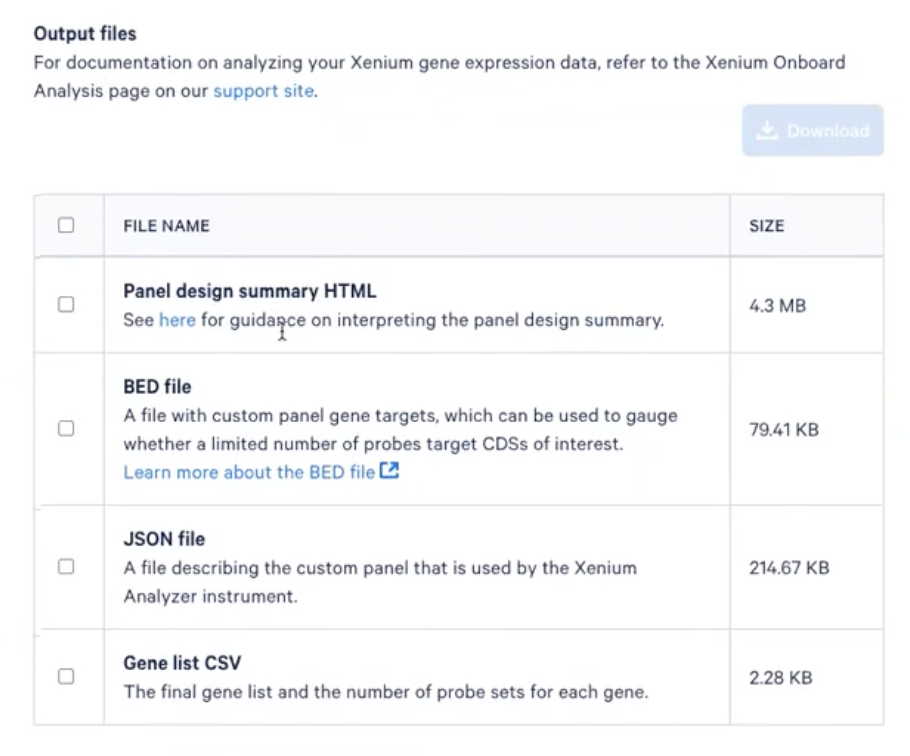
- JSON文件在Xenium仪器运行时会有需要
- BED文件包含了探针的序列信息,老师们在想要探索序列信息时可以下载这个文件
对于Standalone Panel的设计
- 以小鼠大脑为示例
- 首先在”Tell us about your panel”页面中填入我们感兴趣的信息
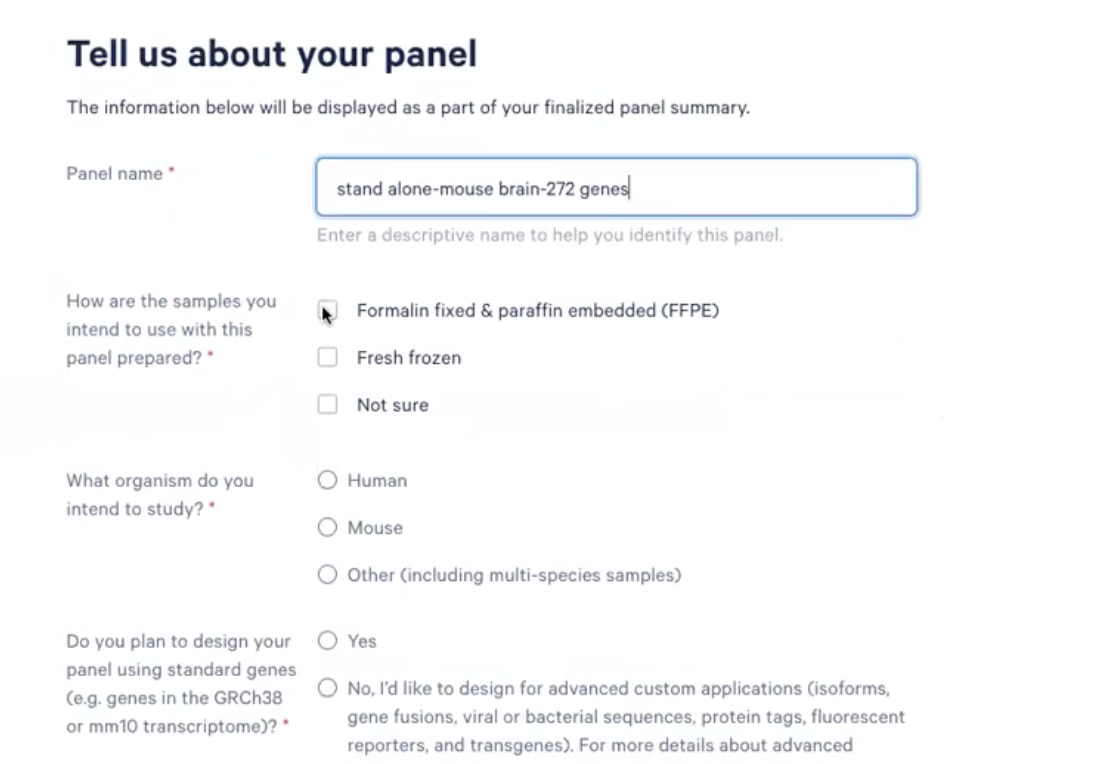
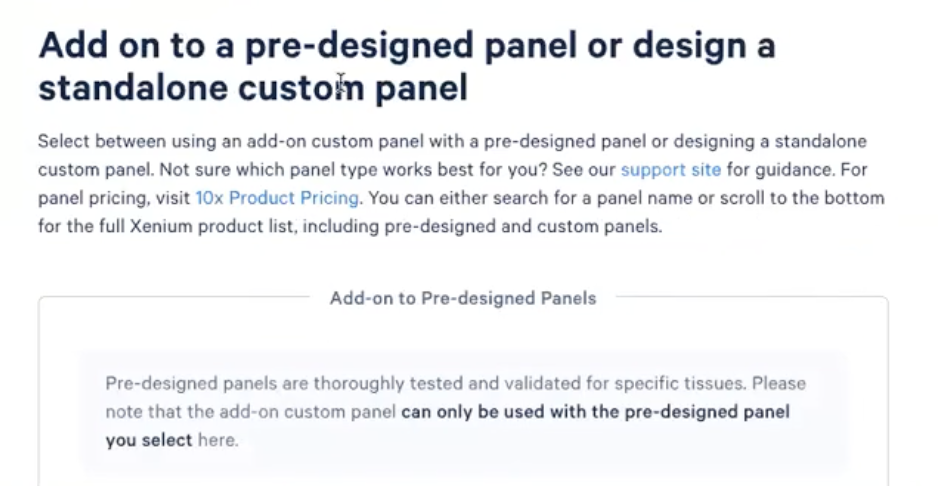
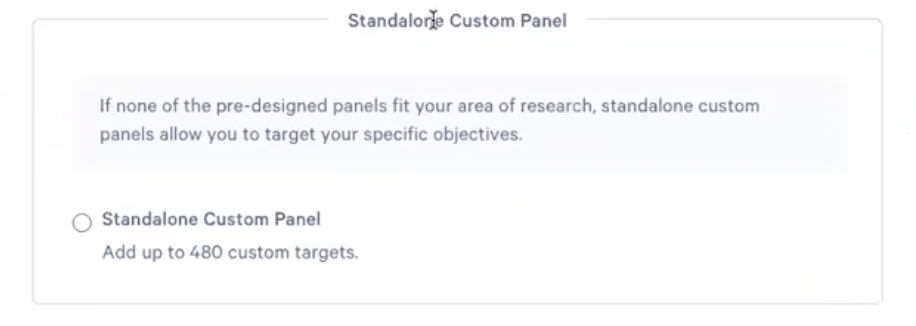
- 在接下来的”Add on to a pre-designed panel or design a standalone custom panel”页面中,老师们需要选择”Standalone Custom Panel”部分的内容,如下图所示
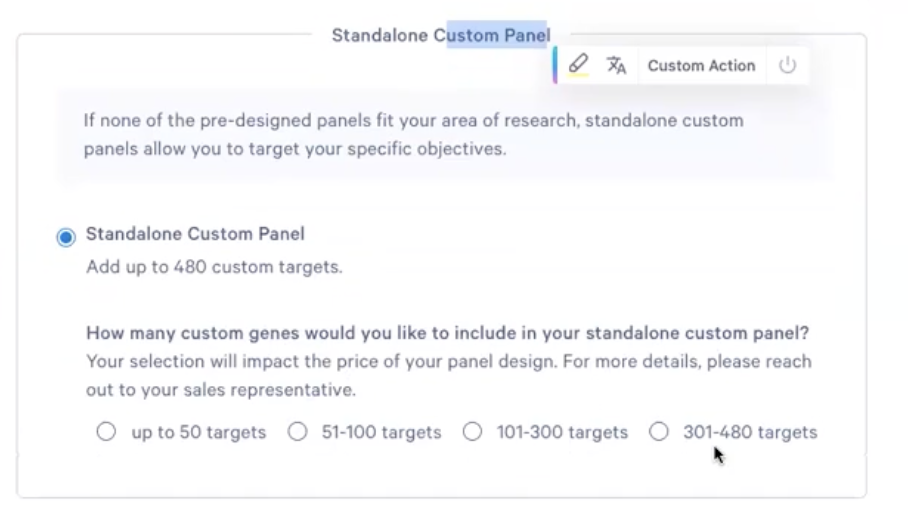
- 对于standalone类型的panel,我们需要选择这个panel想要检测的基因数目,一共有4个档次
- 接着,我们需要提交参考数据,我们可以提交10x的官方参考数据,和/或上传自己的参考数据,具体步骤见上
- 类似的,我们需要上传自己感兴趣的基因列表,我们也需要对每个基因进行核对,与之前的内容是基本相同的,需要确认基因数量没有报错才能进行下一步的”Build Panel Design with XX Genes”
- 之后,算法同样会根据我们上传的参考数据和感兴趣的基因名单,显示出Panel Utilization per Cell Type、Panel Utilization for Highly Expressed Genes、Probeset Summary和Sample Cell Type Composition、Expression Heatmap这些指标供我们对算法给出的结果进行决策
- 对于某些有Optical Crowding风险的基因,老师们如果对这些基因的表达情况很感兴趣,可以尝试手动修改基因列表,也就是选择”Manually edit your gene list to resolve alerts”选项,如下图所示
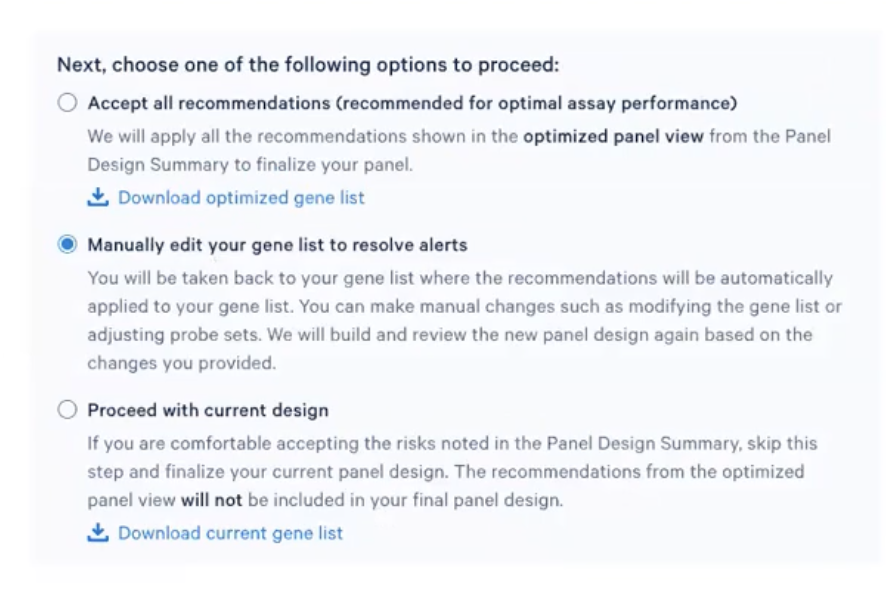
- 然后,在弹出的页面中把删掉的基因的信息重新补齐(参阅您感兴趣的基因列表补上Ensembl ID),然后把探针数目减少一些,比如减少到3
- 其他的内容都是相同的,包括Xenium Panel Design输出的文件也是一样的> 来源:


