富集分析基本介绍
- 随着高通量技术的发展,生物医学相关研究领域进入了组学时代,单个基因的研究已经不能满足研究人员的需要。
- 然而,如此庞大的数据给信息的有效提取和分析带来了新的挑战。以测序数据为例,测序结果分析往往会得到差异表达的基因或蛋白列表。但对许多研究人员来说,将这一长串基因或蛋白与某个待研究的生物学现象及其潜在机制联系起来是很困难的。
- 应对这一挑战的一种方法就是将基因或者蛋白列表分成多个部分,从而减少分析的复杂度。研究人员为了解决分成哪些类,开发了多个注释数据库。
- 为了解决怎么分成不同种类,研究者通常会对基因功能进行富集分析, 期望发现在生物学过程中起关键作用的生物通路, 从而揭示和理解生物学过程的基本分子机制,并且在这实现过程中开发了多种软件。
- 功能富集分析,可以将成百上千个基因、蛋白或者其他分子分到不同的通路中,以减少分析的复杂度。我们常说的基因集富集分析,英文名Gene Sets Enrichment Analysis,主要目的就是用各种方法去获得所得基因列表的生物学解释,无论这个基因列表你是通过实验获得的还是从相关公共数据库上得到的
- 经过富集分析之后,研究人员们寻找到一组有用的基因,以及这组基因集合共享的生物学意义的属性解释,比如说它们都属于某个基因的本体范畴,或者同为染色体某个臂的一部分,或者单纯就是由研究人员人为定义的一个有意义的基因集合。
- 在过表达或敲减等不同实验条件下筛选出来的通路,比单一条件筛选得到的基因或蛋白列表更有说服力。
- 基因集富集分析,其主要目的就是用各种方法去获得所得基因列表的生物学解释。通常是将获取的基因列表与数据库里的种属生物学背景进行比对,之后赋予输出结果相关的生物学意义。
富集分析方法介绍
- 四种主流的富集分析方法
- ORA:Over-Representation Analysis:过代表分析
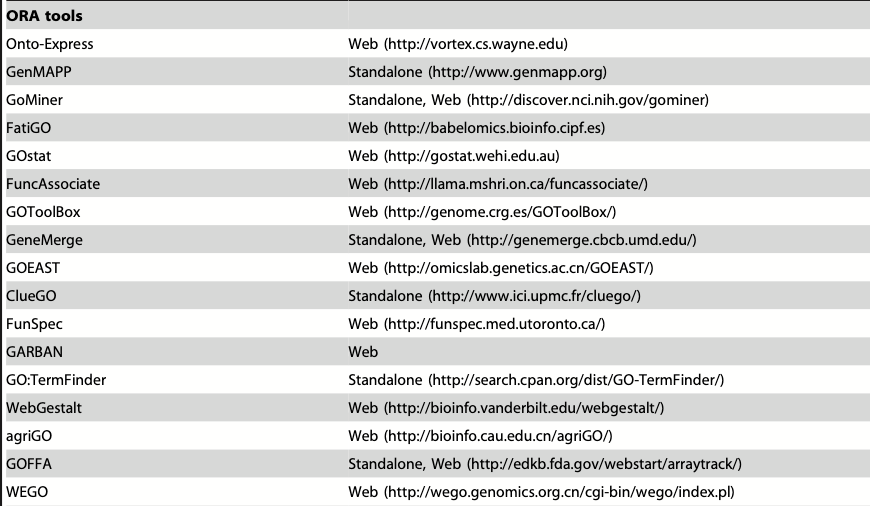
- FCS:Functional Class Scoring:功能集打分
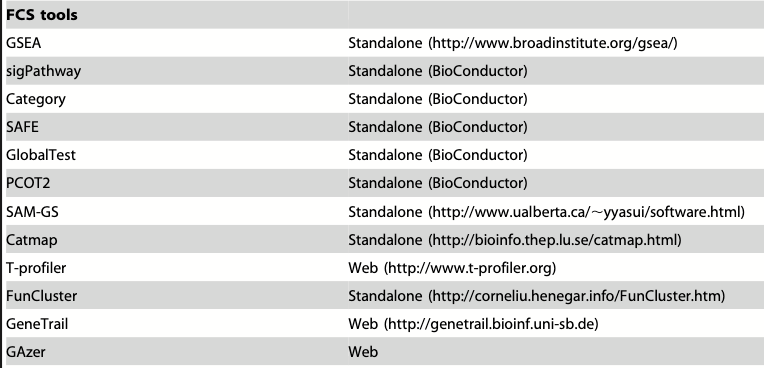
- PT:Pathway Topology 通路拓扑结构分析

- NT:Network Topology 网络拓扑结构分析
4大富集分析类别以及大致流程
得到基因数据作为富集分析的输入数据来源
- 以下图为例,来自于筛选,结果表示为基因列表或者基因表达谱

- 以下图为例,来自于功能注释数据库,例如GO、KEGG、MSigDB等

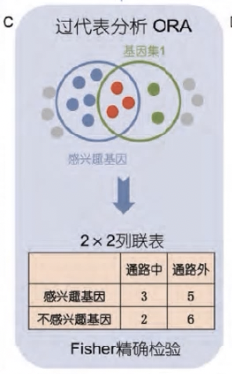
过代表分析ORA
- 先计数基因列表与基因功能集共同的基因, 并利用2×2列联表, 进行Fisher 精确检验
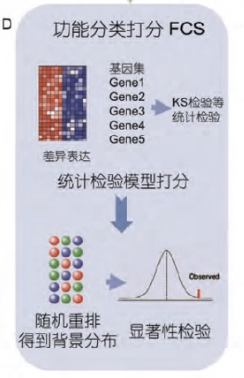
功能分类打分FCS
- 以GSEA为例
- 首先,对基因表达谱中的所有基因按照与表型的差异表达程度排序, 再利用KS检验对待测功能基因集打分, 利用随机重排得到背景分布, 找出有显著富集的功能基因集
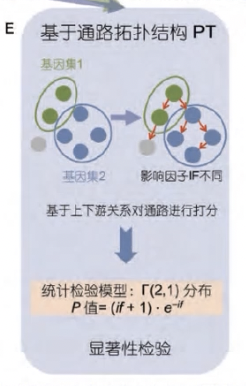
基于通路拓扑结构PT
- 以Pathway-Express为例
- 根据上下游关系对通路进行打分,上游通路的影响因子较大
- 对待测基因的功能集根据影响因子进行打分,然后根据统计检验模型计算显著程度
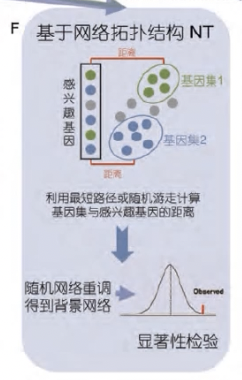
基于网络的拓扑结构NT
- 以NEA为例
- 将基因列表或基因表达谱和待测基因功能集放入生物网络中,计算感兴趣的基因与待测基因功能集在网络之间的最短距离
- 通过对网络重调得到背景分布,找出显著富集的基因功能集
四大富集分析类别的优缺点
过代表分析ORA
- 优点:有比较完备的统计学理论,输出结果稳健而可靠
- 缺点
- 需要人为去设置阈值,不太客观
- 忽略差异不显著的基因,可能会丢失显著性较低但比较关键的基因
- 忽视了基因在通路内部生物学意义的不同,以及基因间复杂的相互作用
- 假设通路与通路间是独立的,这是不太准确的
功能分类打分FCS
- 优点
- 考虑到了基因表达值的属性信息问题;
- 以待测基因功能集为对象来进行检验,使得检验结果更加灵敏以及更有针对性
- 缺点(基本同ORA)
- 独立分析每一条通路,但同一个基因可能涉及多条通路
- 忽略了基因的生物学属性和基因间的复杂相互作用关系
基于通路拓扑结构PT
- 优点:对于研究一些比较完善、拓扑结构完整的通路会有更加强的显著性
- 缺点:对于研究较少、信息不完善的通路时,稳定性较差
基于网络拓扑结构NT
- 优点:加入了系统层面的基因重要程度,以及关联信息等属性数据,使得预测结果更加准确可靠
- 缺点:算法过于复杂,计算速度比较慢,实现难度也更大,也需要更好的硬件水平
GO/KEGG富集分析原理和实现手段
简单介绍GO和KEGG
GO
- GO的全称是Gene Ontology,即基因本体论
- 科研人员创建GO的初衷是希望提供一个能对基因和基因产物特性相关的术语或词义进行描绘及解释的工作平台,从而使生物信息学研究者对基因和基因产物的数据能够进行统一的归纳、处理、解释和共享,便于我们理解和沟通
- 基因本体涉及的基因词汇和基因产物词汇分为3大类,涵盖生物学的3个方面
- 细胞组分cellular component:细胞的每个部份和细胞外环境
- 分子功能molecular function:可以描述为分子水平的活性activity,如催化catalytic和结合binding
- 生物过程biological process:由一个或多个分子功能有序组合而产生的系列事件,一般一个过程由多个不同的步骤组成
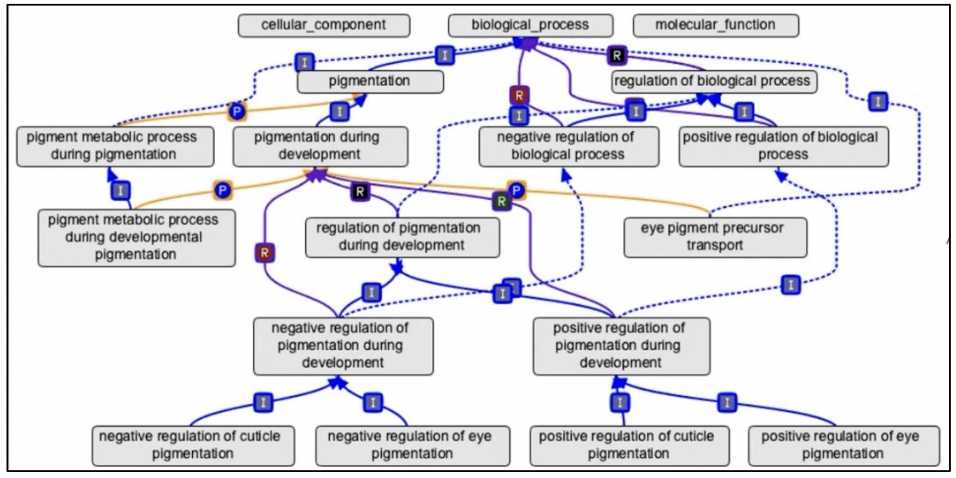
- 在这三个基因本体层次下面可以独立出不同的亚层次,层层向下构成一个gene ontologies的树型分支结构,如下图以生物过程为例的GO树状分支结构,我们把GO理解成生物学的统一化工具,是一套统一的描述生物学行为的语言就可以了
KEGG
- 引入KEGG的目的:对富集结果进行生物学解释
- KEGG是一个整合了基因组、化学和系统功能信息的,基因组破译相关的数据库,可以对更高层次和更复杂的细胞活动和生物体行为作出计算推测
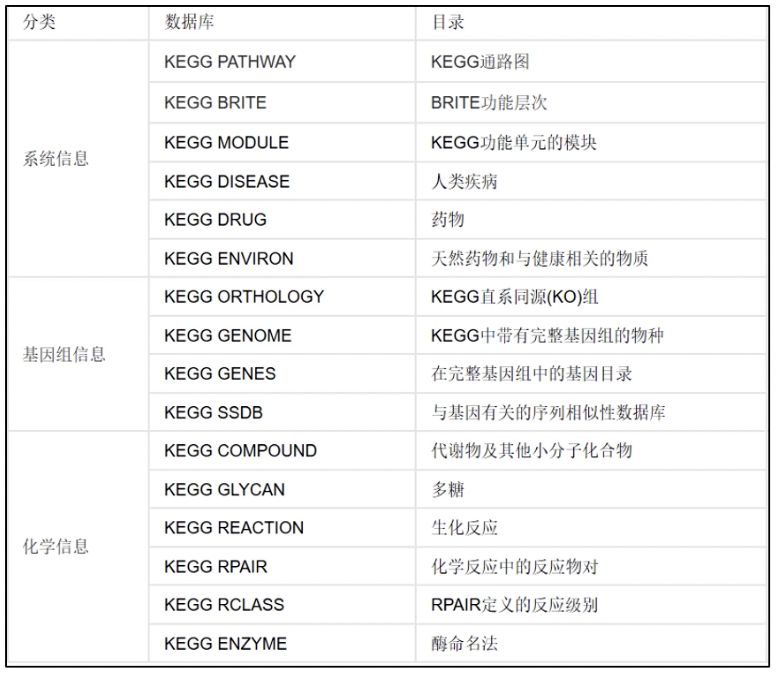
- KEGG 的系统信息中PATHWAY数据库整合当前在分子互动网络,存储了一些更高级的功能信息,包括了细胞生化过程如代谢、膜转运、信号传递、细胞周期,还包括同系保守的子通路等信息通道
- KEGG的基因组信息中GENES、SSDB、KO数据库可以提供关于在基因组计划中发现的基因和蛋白质的相关知识,其中基因组信息存储在 KEGG 的 GENES数据库里,包括完整和部分测序的基因组序列,而 KO这个系统通过把分子网络的相关信息连接到基因组中,从而发展和促进了跨物种注释流程,实现了跨物种分析基因信息;KEGG的化学信息中COMPOUND、GLYCAN、REACTION等数据库则提供生化复合物及反应方面的知识
- KEGG还有几个补充数据库,其中一个叫LIGAND,里面还包含有化学物质、酶分子、酶反应等信息。
- 把从已经完整测序的基因组中得到的基因目录与更高级别的细胞、物种和生态系统水平的系统功能关联起来是KEGG数据库的特色之一
- KEGG利用图形而不是繁缛的文字来介绍众多的代谢途径以及各途径之间的关系,这样可以使研究者能够对其所要研究的代谢途径有一个直观全面的了解。而我们可以将 GO富集分析的数据结果录入 KEGG不同的次级数据库中进行分析,也许可以得到不同维度的结果信息,使我们能够挖掘更多的数据信息,
- KEGG还提供了Java的图形工具来访问基因组图谱,比较基因组图谱和操作表达图谱,以及其它序列比较、图形比较和通路计算的工具,这个是可以免费获取的。
GO/KEGG富集分析原理以及实现手段
使用GO富集分析工具
输出解释结果表
富集分析结果输出
KEGG分析
数据要求
- 一列基因名/基因ID序列
- 在进行测序数据下游分析时,我们常常需要用到不同的数据库,而这些数据库的分析的输入文件经常是各有区别,因此我们常常需要将各类ID,如ensamble ID、Entrez ID、gene symbol等进行转换。
- 其他基因属性信息
- 时间相关的基因表达值
- 实验组、对照组、背景比较
- 其他
ORA类数据
- 以DAVID为例:要求为一列基因ID,一行一个,不区分大小写
- 一列芯片ID,也可以转换成gene symbol/ensembl_gene_ID等等,这时select identifier也要做对应的改变

FCS类数据
- 以GSEA为例:每个基因一行,每个基因需要我们输入3部份
- 基因的ID
- 基因描述(不重要但必须有)
- 不同样本的表达值(打分的关键),如果缺失也是允许的
- 不同的上传格式,缺失值的表达方式是不同的
- PCL: Stanford cDNA file format的excel表格 cDNA 相关的,出现缺失值,那一个位置就空着
- 如果是GCT: Gene Cluster Text file format基因聚类的,缺失则需要在那一格中注释 NA或NULL
ID转换数据库
- 基因名向基因ID的转换
- bioDBnet
- g:Profiler
- bioMart