医学统计的任务
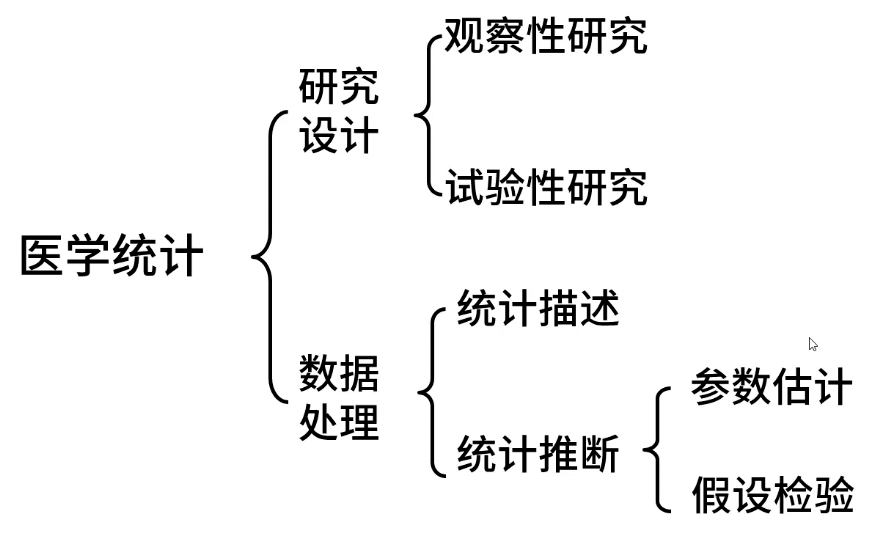
研究设计的种类
试验性研究设计
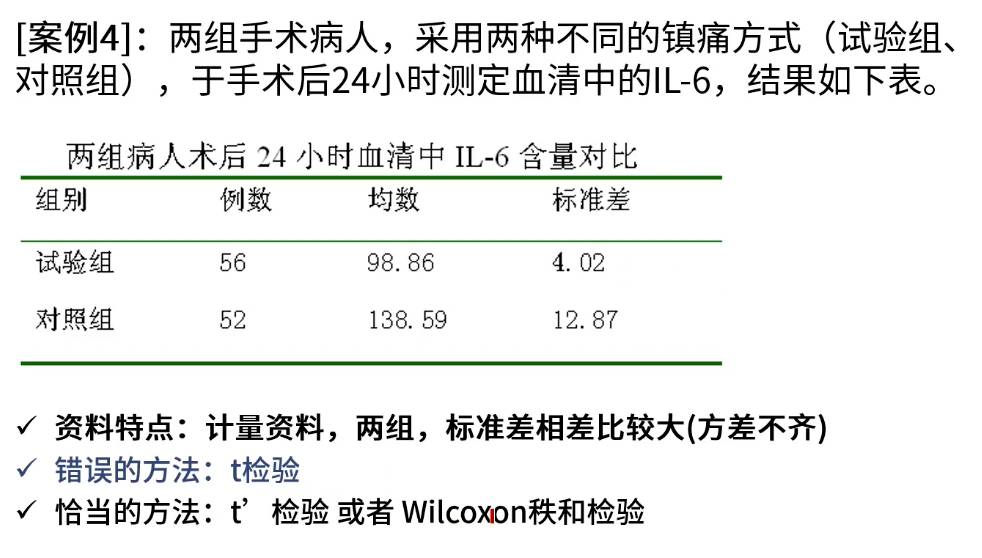
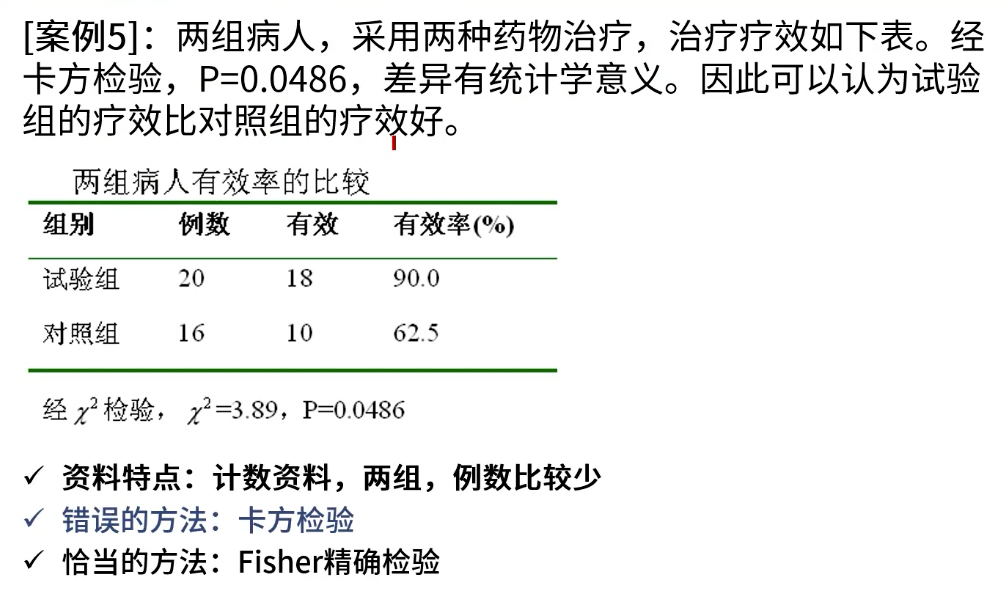
完全随机设计(成组设计)
- 最常见,最容易实施的试验设计方案
- 将研究对象随机分配到几个组,然后进行试验
配对设计(区组设计)
- 将两个具有相似特征的研究对象配成对,然后将每对的对象随机分配到两个组进行试验:
- 同源配对(样品一分为二)
- 异源配对(按照性别、年龄、体重配对)
- 自身前后配对(试验前后的对比)
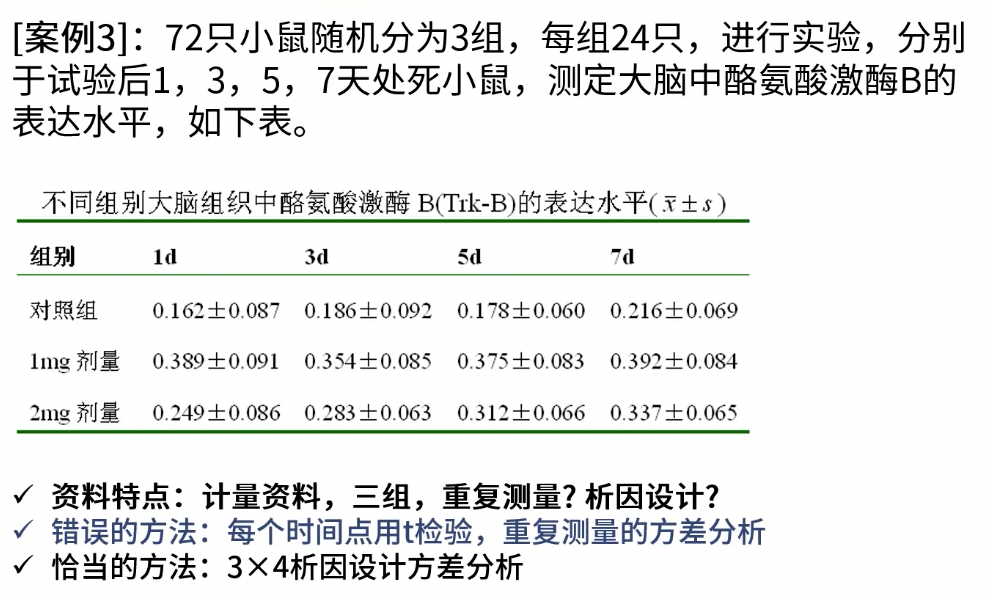
析因设计
- 同时研究多个试验因素对结果的影响
- 例如,研究药物剂量(3mg、6mg)及给药方式(口服、肌注)对结果的影响,每种组合均需要做试验(3mg+口服,3mg+肌注,6mg+口服,6mg+肌注),为2×2析因设计
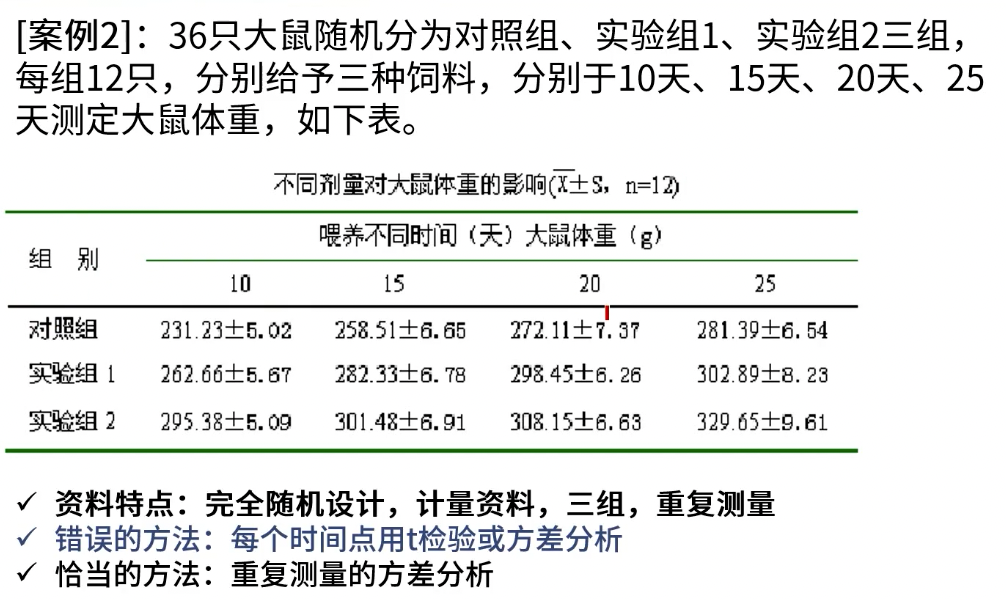
重复测量设计
- 同一对象在不同时间点上进行某个指标的观测,来分析这个指标在时间上的变化,或者同一个对象在不同状态下进行多次测量
交叉设计
- A、B两种处理
- 将受试对象随机地分为两组,第1组在时期1接受A处理,时期2接受B处理,试验顺序为A-B,第2组相反,试验顺序为B-A
- 这是2种处理,2个序列,2个阶段的交叉试验
- 时期1和时期2之间会有洗脱期
成组序贯设计
- 主要跟序贯设计进行区别
- 序贯设计每增加一对受试者就进行分析,但是成组许冠设计在完成一定比例的样本比例或时间间隔后才会进行中期评价
临床研究的分类法则
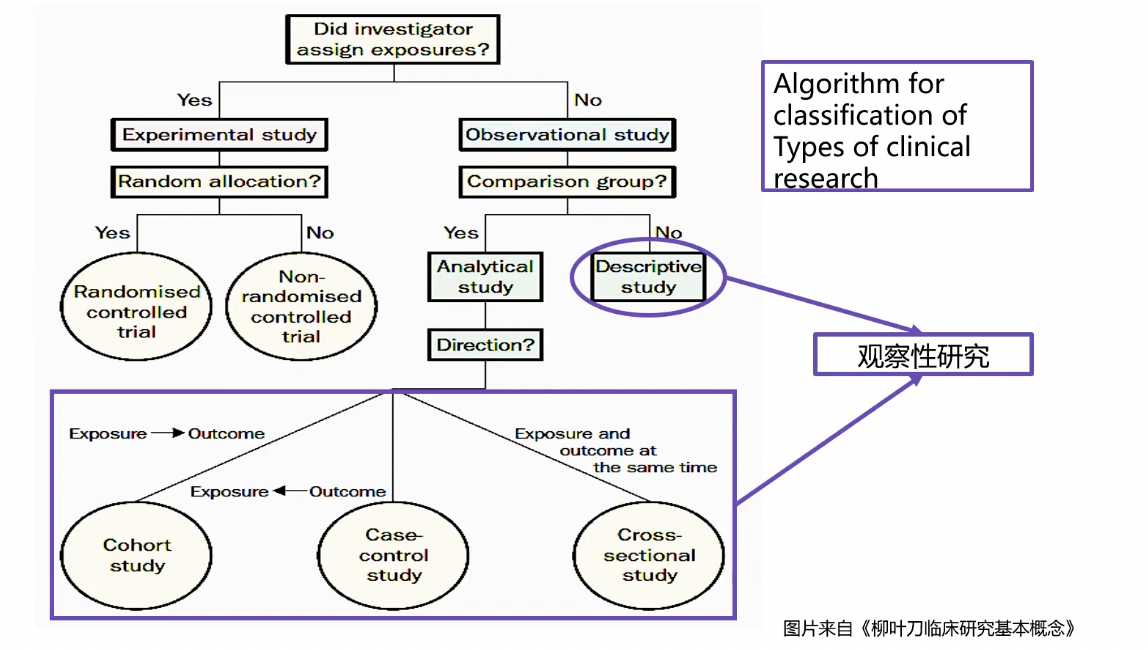
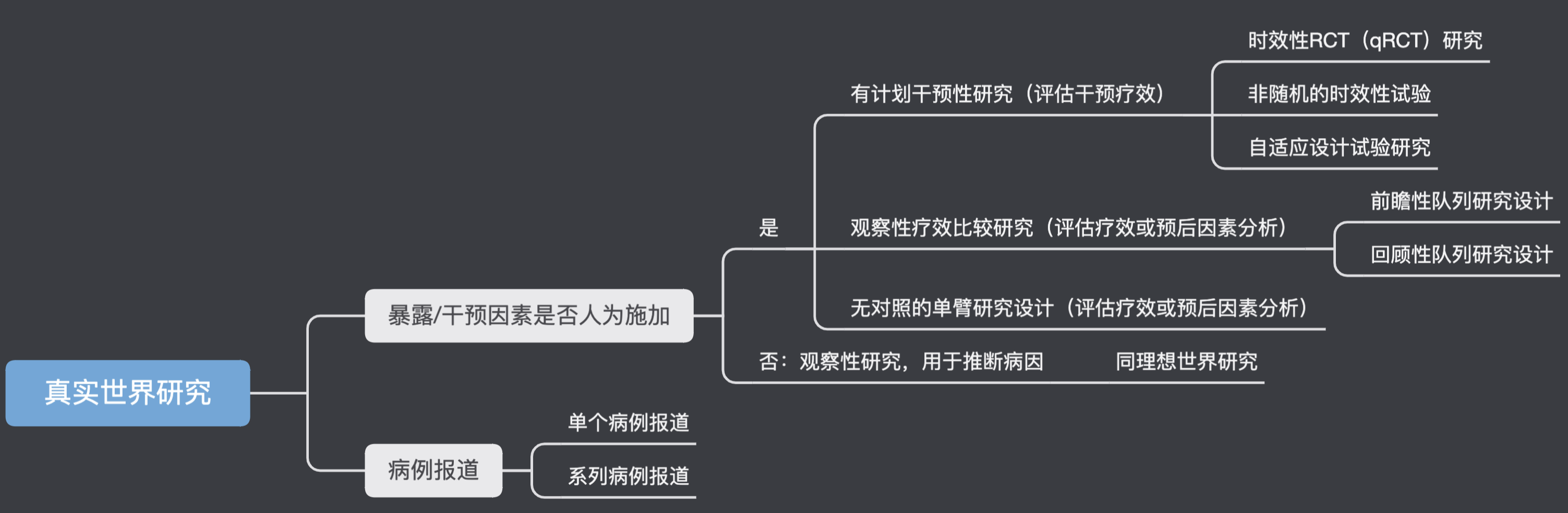
实验性/干预性研究
观察性研究
分析性研究
- 根据因果关系
- 由因到果:队列研究
- 由果推因:病例-对照研究
- 因果同时出现:横断面研究
更加复杂的临床研究分类法则
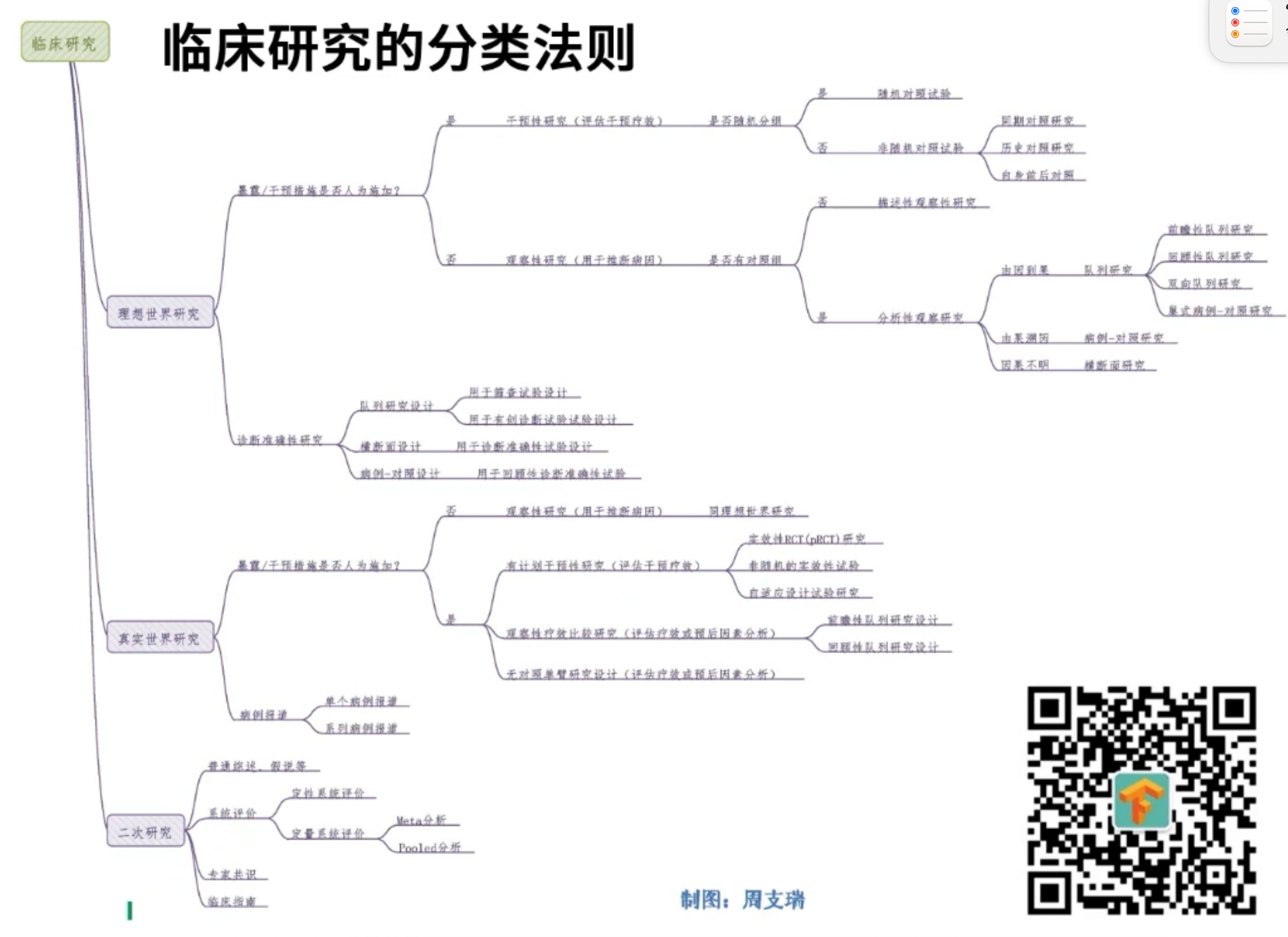
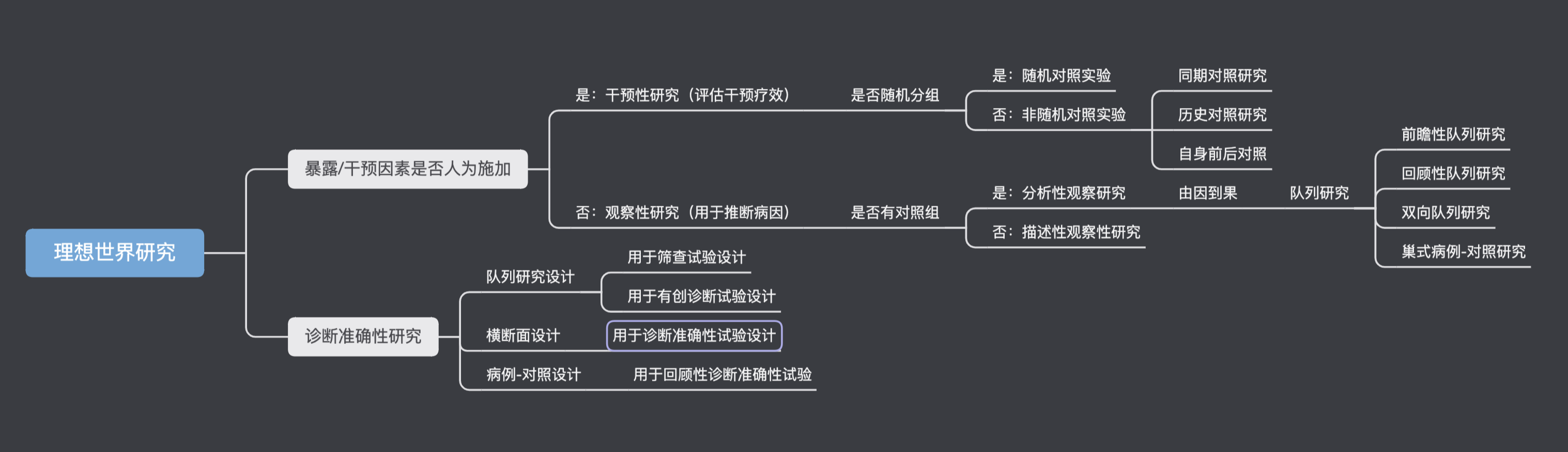
理想世界研究
真实世界研究
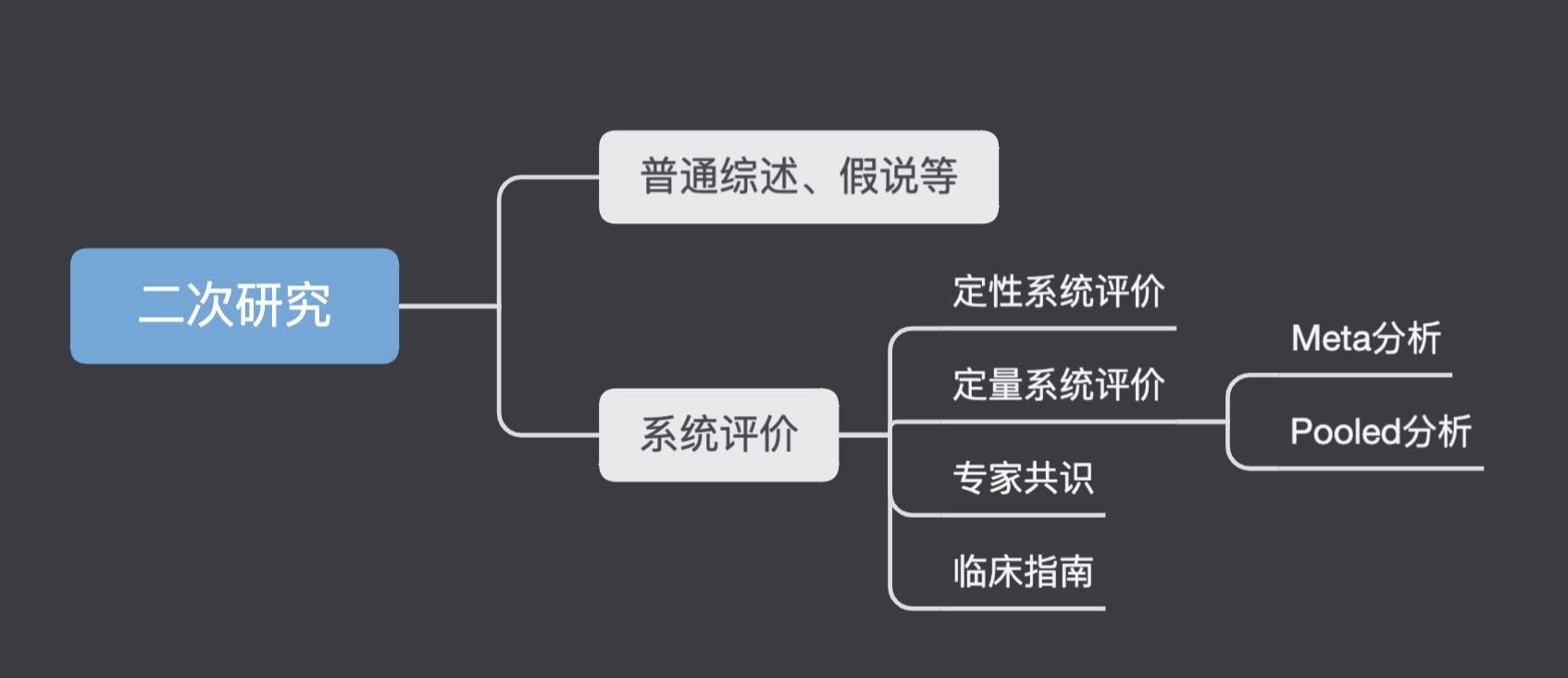
二次研究
混杂因素如何处理
- 随机对照实验中,不需要考虑混杂因素,因为经过随机化分组之后,实验组和对照组已经完全均衡了
- 观察性研究需要考虑混杂因素,因为没有经过随机化分组,混杂因素在实验组和对照组不均衡,有可能影响实验结果,需要控制和/或矫正
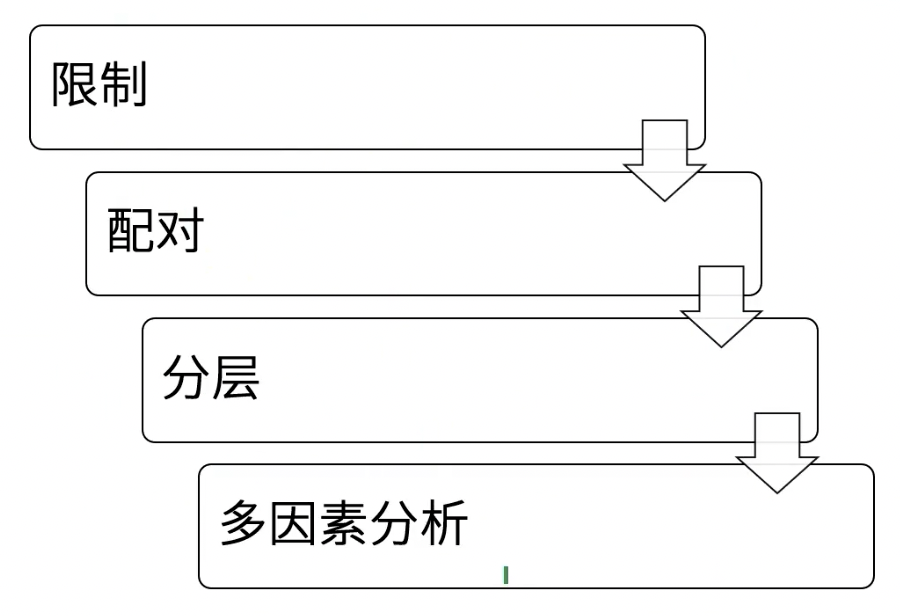
- 限制:对实验组和对照组的研究对象进行筛选,让实验组和对照组由一定的同质性,比如规定实验组和对照组都需要是60岁以上的吸烟男性
- 配对:根据试验组(或对照组)的混杂因素情况,去“量身定制”地寻找一个混杂因素基本相同的人作为另一组试验设计,进行观察
- 分层/亚组分析:在试验组和对照组有效率有差异的
- 一种可能的情况:试验组男性占比比较高,对照组女性占比比较高,也就是性别这个混杂因素并不完全统一,这个时候我们就可以采取亚组分析
- 如果我们在
男性的试验组检验有效率,发现没有差异,在女性的试验组检验有效率,也发现没有差异(比如上面两种情况都是p>0.05),那这中情况下我们就可以说导致差异的是性别这个混杂因素
- 多因素分析:只要样本量够,可以一次考虑非常多的混杂因素,在文献中最常看到的,也是控制混杂因素最彻底的方式
校正混杂因素的方法
- 也就是通过统计分析控制混杂啦
- 多重线性回归
- Logistic回归
- Cox比例风险模型
- 倾向匹配分析(psm,虽然严格意义上说属于匹配)
统计方法的选择
- 通俗理解:一般根据因变量(也就是初中课本中的
Y)来选择
定量结局单因素分析
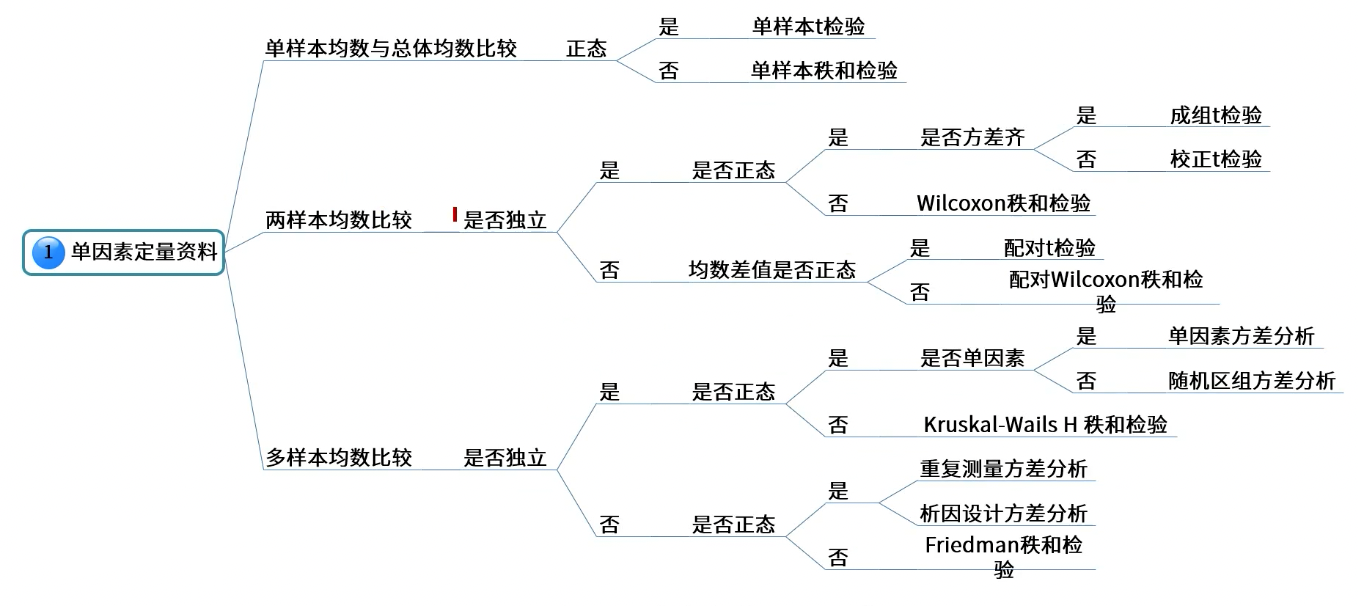
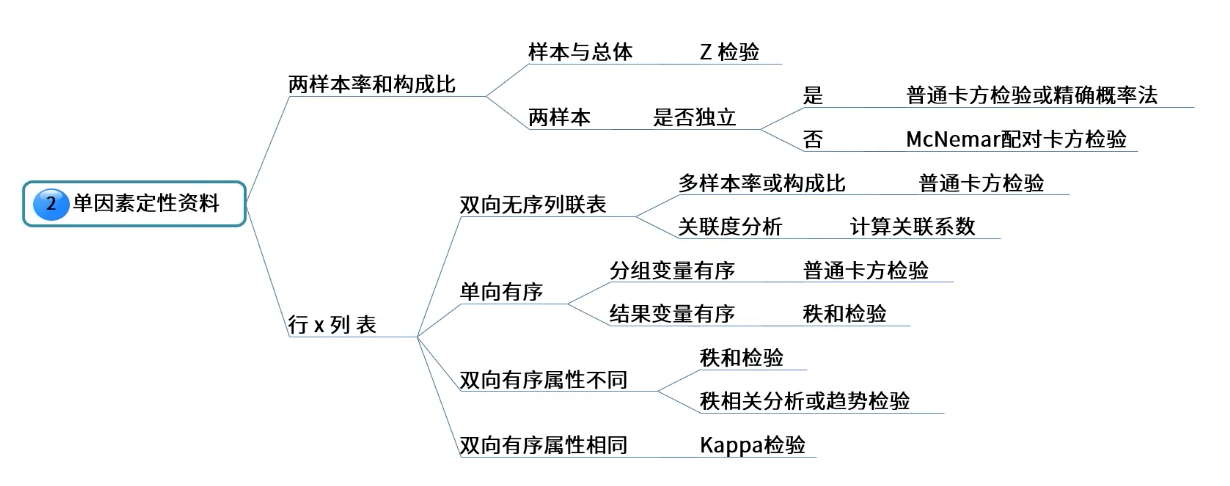
定性资料结局单因素分析
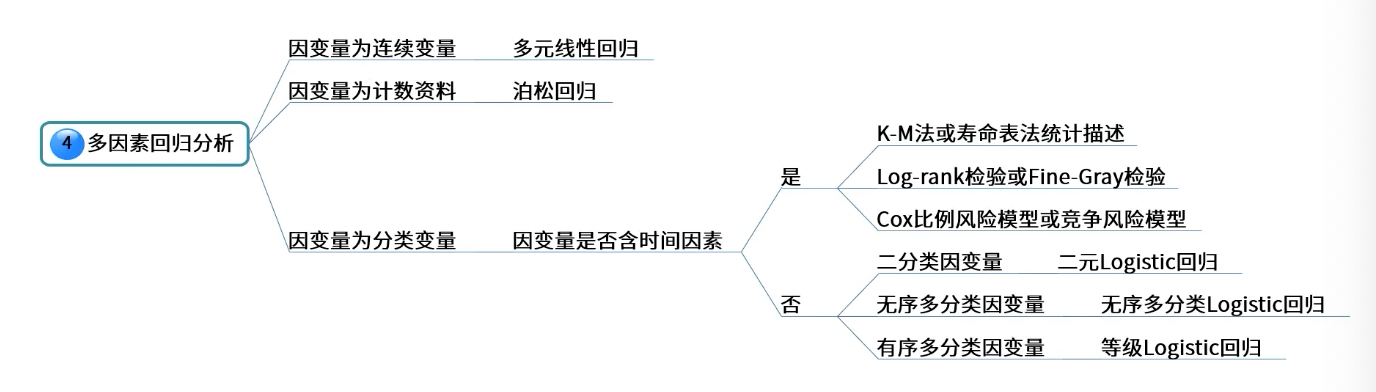
定量/定性/生存资料的多因素分析
示例