- 在直接机制部份,按照分子交互的类型来归类,有蛋白-DNA交互作用、蛋白-蛋白交互作用、RNA-RNA交互作用、蛋白-RNA交互作用以及相应的三元组合直接作用(蛋白-蛋白-DNA;RNA-miRNA-RNA以及RNA-蛋白-DNA)。学会了分子归类,逻辑思路就能始终保持清晰。在上一节课中,我们还针对直接机制的纵向细节模式,介绍了除了分子修饰的另一种常见形式——可变剪切。我们可以把全部的直接机制,总结成“分子交互,修饰剪切”这八个字。修饰剪切与分子交互略有不同,聚焦点在于分子本身状态的变化,而不是与其他分子的相互结合。横向多元变量组合加上纵向分子状态改变,这样的套路已经达到了基础科研的高深境界,职业科学家的水平。职业选手当然不是那么好当的,要消化这些知识还需要补充文献阅读的体会。凡是领悟透彻的学员,基本都药经历文献的实践检验,在举一反三之后,方能升华成自己的科研方法论。
- 在三十六策与大家讨论的科研逻辑方法论体系,已经揭开了一大半,直接机制到了基础研究的深水区。在前面分子交互、修饰剪切基础上,今天最后一策“秋毫之末”,我们要把分子相互作用的结合位点验证策略作为直接机制的收官内容来讲。
对这一讲标题的介绍
- “秋毫之末”,听名字就是细节,本身分子交互就是机制的细节,而位点验证是细节中的细节,基础研究没有比位点验证更加细节的维度了。证明了两个分子有结合,再进一步探讨它们结合的姿势,就是位点验证,作用位点是基础科研能够到达的最细微的观察角度。
- DNA和RNA的基本单元是碱基、脱氧核糖或者核糖+磷酸,而蛋白进一步细分到一级结构是一条氨基酸组成的链条,如果这些生物大分子之间有直接结合,结合部位可以最终落实到具体某个碱基位点或者氨基酸位点,这是现今我们解释分子机制的最小单元。细细数一下,从疾病到表型,到分子,到调控关系,到直接结合,到结合位点,逻辑上层层递进一共是嵌套了六层。疾病是临床上可以判断的一种现象,它转化为科学视角就是表型的特征。表型已经在组织、细胞的层次了,肉眼看不到,但某些特征显微镜可以看到。再接下来到分子层面,连常规的显微镜都观察不了,分子之间的作用关系更没法用肉眼来观察,那就需要用一套客观的评价体系来解释分子对表型的影响。好在我们掌握了操作分子的能力,有了Gain of Function和Loss of Function手段,这样才能在分子层面来理解其中的规律。操作一个变量观察另一个变量的“你动我也动”是最基本的调控关系证据,也从分子信号传递的角度对表型进行了注释。分子与分子间如果有直接的结合会比调节作用更进一步,从间接对象升级到了直接对象,这种科研故事的水平可以轻松突破五分,属于比较高级的学术框架。最后,不但有直接结合,还知道结合的核酸/蛋白区段、位点,我们就已经可以说下潜到基础科研的马里亚纳海沟了。
位点验证的若干策略
序列分段策略
- 有直接机制必然有结合位点,结合都证明了,位点肯定跑不了。大不了一个一个碱基,一个一个氨基酸的撸,无非是工作量的问题。当然一个个撸还是太粗暴了一点,怎么确认结合的部位呢?序列分段是一种常见的实验策略。
- 对于DNA(的启动子)和RNA(中的LncRNA),当研究它们跟蛋白结合的时候,常常可以采取分段的策略。一段序列很长,比如1000bp,可以考虑分成4段,每段250个bp,然后再去重复前期做过的分子互作的实验。
- 当我们用直接作用的分子交互实验验证了两个分子有结合,下一步的策略就是把DNA启动子和LncRNA序列分段,重复验证一下,看他们具体结合在哪个区段上。理论上,通过分段的方法,是可以逐步缩小范围,最终锁定到结合区域序列的,250bp还可以再分段嘛,这样两次切完就是很小的序列了,一步一步缩小范围。
- 一段分多长合适其实没有金标准,一般不超过500bp,分成三段四段的都比较常见,这是因为有效率的做法最受欢迎。你们可以自己测算一下,一段1000bp的序列每次分4段,第一次解析率是250bp,第二次把阳性的再分段解析率等于62.5bp。一种不太聪明的办法,比如第一次就分成8段,这样的解析率就只有125bp,效率整整差了一倍。
点突变策略
- 通过分段缩小了范围,最终核酸上的结合位点还可以用点突变的策略来验证。
- 在分子生物学中,对序列中的一个或多个核苷酸位点进行突变是一个很成熟的技术。这样既可以验证核酸的结合位点,也可以改变蛋白的氨基酸密码子从而突变一个氨基酸,毕竟蛋白也是通过构建质粒上的核酸序列过表达出来的,密码子我们又掌握了,所以操作氨基酸序列也不在话下。这时候我们对分子结合的研究程度已经到达了单个核苷酸和单个氨基酸的水平,这就到头了,两个分子在一起的一切都淋漓尽致地呈现在我们前面,窥探到这个地步,已经没有更深入的故事可以讲,戏该散场了。
- 除了分子交互,前面谈到的各种分子修饰,DNA甲基化, RNA甲基化,蛋白的糖基化、磷酸化、泛素化、酰基化都可以具体到位点验证的层次。分子的直接相互作用,DNA和蛋白,蛋白和蛋白,蛋白和RNA,RNA和RNA,RNA和DNA,也都可以通用于结合位点验证的策略,通过位点突变来确认结合序列的特异性。定点突变是一项伟大的技术,没有这个技术做完结合验证就结束了,没有办法深入到单个核苷酸和氨基酸的水平。定点突变英文叫site-specific mutagenesis,它能够实现在体外高效特异地改变DNA序列中特定某一个或几个核苷酸。这项技术的发明人是加拿大科学家Michael Smith,时间是1985年,并且在1993年获诺奖化学奖。
- 在发明定点突变方法之前,突变的产生需要经由自然界长时间的筛选或者用化学等方法诱导突变。突变的发生是随机的,而且突变株必须在生物性状上有所改变才能被观察到,然后再去鉴定到底发生了什么突变。可以说是一个研究的对象,一个科学问题,而不能称之为研究方法。Smith教授发明的定点突变技术可以有目的的设计特异性的核苷酸序列,在任何一个基因片段上进行随意替换。其实原理不复杂,人为在PCR扩增的引物上加入突变,形成错配的引物,然后通过酶切把不包含突变的质粒给破坏掉,这样就能转化出来包含突变序列的质粒。定点突变技术有很多的变种,一次性引入多个突变位点也是可行的,总之按照试剂盒的protocol来操作,这种做工具的活交给公司来办是比较适合我们医生做科研时间稀缺的现状,构建突变质粒费用不贵,省下来时间做关键的细胞表型和机制实验,多重复几次。
不同的分子组合如何进行验证
第一类分子组合:使用Luciferase
- 我们在这里使用“第一类”这个有些模糊的说法,是因为这一类是通过排除了更复杂的第二和第三类(见下)产生的,也因为验证这些组合都需要使用Luciferase,主要包括接下来的三种
- 转录因子+miRNA
- DNA的启动子区域+转录因子
- miRNA+mRNA的3’-UTR
- DNA的启动子区域很长,一般来说用分段策略做就可以了,大致定位到结合的区域,很多文章里面并不需要一定明确到位点。也就是说启动子和转录因子的结合验证,主要策略是把启动子区域分段,然做荧光素酶报告基因实验,看有没有调节Luciferase的转录作用。如果我们还预测了到转录因子结合的motif,当然也可以点突变再验证,有了结合位点的分析就比单论证有没有结合的Luciferase加上ChIP/EMSA实验的结果更进了一步。
- miRNA本身就只有20+碱基,没什么分段的必要性,结合的关键位置叫SEED Region种子区,也叫seed sequence,它是miRNA结合mRNA的必要序列,一般是miRNA的5’-端2-7位的碱基,这段序列需要与靶基因完全互补配对,而且一般来说很保守。毫无疑问,我们可以采取点突变的形式,把影响结合的位点给筛查出来。在miRNA的研究中,做一个突变的表达载体以证明结合的特异性,然后表明它失去对靶基因的抑制作用后,功能会显著受到影响,说明miRNA结合靶基因对功能发挥很重要,这都是常规论证思路。我们在三十六策 Lesson 21里提到的ceRNA调控模式,本质也是miRNA结合靶基因,所以其中的位点验证道理一样,也可以归在第一类里。
蛋白-蛋白相互作用:使用co-IP
- 利用co-IP验证存在结合的两个蛋白,根据结构域domain可以分段,或者根据预测的关键位点进行氨基酸的点突变,然后我们重复co-IP实验,看还有没有结合作用,这就能够报告在结合序列的特性上两个分子是什么情况。蛋白结合是经典分子互作模式,所以第二类位点验证的结果在文章里频繁能看到。
- 大家需要弄明白一件事:在验证位点的时候,操作的对象是过表达的载体,也就是质粒,不是直接改蛋白,改的是表达蛋白产物的DNA,不管你是RNA还是蛋白,反正改了DNA,都得乖乖听话,这是所谓的“擒贼先擒王”,中心法则这套原理被我们充分利用了。直接修改蛋白里面氨基酸的方法还没有开发出来,因为生物体本身的机制,调控就主要发生在DNA、RNA水平,到了蛋白就覆水难收了,只能加点修饰标签微调一下。基因操作的技术像CRISPR、RNAi、TALEN等层出不穷,已经到了造物主的能力阶段,突变、删除、添加碱基随心所欲。所以当我们药在蛋白水平进行氨基酸位点上的精细研究时,把内源的蛋白干掉,导入一个改造过的外源蛋白就可以实现。
RNA-蛋白相互作用:使用Pulldown
- 在这个模式里主变量往往是LncRNA,LncRNA创新性强,新的分子做主变量承担创新任务是常规。lncRNA和蛋白都可以做突变操作,这里就有个问题,验证结合的时候突变哪个为好呢?要考虑两个因素:突变核酸方便还是突变蛋白方便,以及蛋白和核酸那个是主变量的问题,谁是主角谁就承担主要的戏份,从这两个要素来判断都应该对着LncRNA下手才对。LncRNA很长,就算可以用计算机预测结合位点也不一定很准确,上来就做点突变风险太大了,先做一个分段的操作是很合理的策略。分了段之后再去做RIP,RNA pulldown,其实道理跟前面一模一样,进一步缩小区域范围,然后有必要的话,再去做结合位点的突变。到了这一步拼的就是一个工作量,结合都已经确认了,结合位点还会远吗?
总结
- 从间接作用机制的调控关系,到直接作用机制的结合关系,逻辑层次上是从知其然不知其所以然,提升到了知其然知其所以然的层次,有了大幅度的加分。在实验的难度上也从观察“你动我也动”的qPCR,western,最多加个Rescue双操作看表型,观察Biomarker的变化,提升到了luciferase assay、ChIP,co-IP,RIP,pulldown这些颇有难度的实验上,很明显是一个门槛了,是用来区分IF=5往上和IF=5以下的一个巨大鸿沟。
- 这些高端分子互作实验,操作流程比较复杂,需要注意的细节很多,不是一个新手随随便便就能掌握的,也没什么技术公司真的能外包服务做得特别好。考虑到医生做科研都是断断续续的非正规实验室训练,实验的难度显然会阻碍我们向高分的攀爬进军。所以以发IF=10的水平的文章为目标的话,这种直接机制的实验要么自己花苦功啃下来,要么找到合作资源,找实验高手帮代劳一下,总之是必须突破才能一览众山小。结合位点验证是当我们已经获得了关键性的结合实验证据之后,凭借工作量在论证逻辑上再进一步的完美策略。这里工作量不可小视,很多人这一步位点验证要做个半年以上,构建无数个质粒,重复无数次实验。结合位点就在那里,但不是一个轻巧的发现,背后是挖地三尺的韧性,大不了我一个个序列撸也要把你撸出来。
- 当然很多IF=5-10的文章里面,做到了结合位点,就做一个分段验证就点到为止了,甚至连分段也没有,只有交互作用的经典实验,不过工作量和高端实验设计没有了,IF也就下去了。用最精炼的数据发最有性价比的文章,这是医生做科研普遍的想法。策略的关键是数据层次上要深入,各个维度都要展,示但工作量上要追求简约,每一步都用经典的实验数据证明,不做多组数据的重复验证,稍微耍点滑头。这种思路不符合科学的初心,但能够满足现实的需求,也无可厚非。
- 读懂10分文章的论证套路还是短期可以实现的,半年左右的学习就能有显著的效果,但是真的能把读懂文章变成发表同一档次的文章,那还需要经过一年两年甚至更长时间的实验室摸索才能有所突破。
- 当我们在文章里看到了直接作用机制的典型数据,看到了luciferase、IP、input这种关键词,就要注意它后面可能会跟着结合位点验证的数据,心里有个预期。阻断了结合可能影响分子的功能,也可能影响它下游调节的分子,这就跟我们做调控关系的Rescue时,需要观察表型失而复得,并且看看下游分子的回复情况,道理是一样的。
- 位点对于结合的必要性,通过位点突变之后不结合了的功能变化来证明。熟悉了这些套路,就能做到内心的平和淡定,面对数据举重若轻,直达背后的逻辑规律。要做到不被数据表象的复杂性迷惑很难,不是被动跟着作者的思路走,是你建立一套不变的框架,看文章有哪些规定动作,哪些是支线剧情和自由发挥。自由发挥的地方,有哪些是值得借鉴的套路,让我们的框架越来越完整。
至今为止的课程总结
- 在三十六策Lesson 1至Lesson 6,我们讲解了科研中五恒量三变量的模块要素结构。五恒量+三变量是基础科研的基本模块。
- 三十六策Lesson 7到Lesson 12中,我们讲解了筛、猜二字诀,也就是分子这个变量从哪里来的问题,然后梳理功能基因、miRNA、LncRNA三种分子类型的单变量研究模式以及分子本身的一些修饰变形,到这里重点是理解单变量代入五恒量组成一篇文章的内容结构。单变量论证有12字口诀:表达差异,正反回复,细胞动物,指导的是如何编排数据和组织故事。
- Lesson 13到Lesson 18是第三部份,我们开始进阶到多元变量,上下游调控关系,论证的时候,先辨主次,再分上下,两两调控,三三回复,这是关于多元变量论证套路的16字口诀。同时关于Rescue实验设计,还有正正反,正反正,反正正,反反反,12个字的心法。间接作用机制是知其然不知其所以然,A调节B,B调节C,串成一串珠链,彼此间能相互调节,但具体怎么影响的不太确定,保留了想象空间。间接作用机制的要点就是“傍大款,靠明星”,把你新发现的变量分子跟明星通路这么一搭,科研的创新性立马就提升了。科研界当然也有流行趋势,有明星大佬,这帮掌握话语权的人创造研究方向,制造研究热点,我们跟在后面混吃混喝,跟随战略是简单有效的,毕竟我们是医生是兼职而不是全职干科研。
- Lesson 19到这节课是最新的部份,我们专注在直接机制的内容上,致力于解剖分子交互的秘密。分子机制除了上下游调控还有分子修饰、可变剪切的一锅炖,在一篇文章一个课题里存在横向+纵向二维展开模式。这些规律总结起来同样是16字口诀:直接交互,分子归类,横向纵向,二维展开。
- 汇总一下,基础科研外乎62字=五恒量三变量6 个字+单变量论证12字口诀+多元变量论证16字+Rescue策略12字+直接机制16字。到了这里,三十六策系列课程的三分之二就结束了,基础科研论证规律总结起来就是这62字。掌握了目前为止我们讨论的内容,科研在逻辑上就没什么能够难到你的地方了,这是内功。同时外家套路也要修炼, 大量的常识需要自己查资料背下来。医学科研方向那么多,要把全部边边角角都照顾到,需要好几年的时间,我们只能是先把大方向的常识整理好,再把一个个疾病和表型逐步来攻克。
一张图
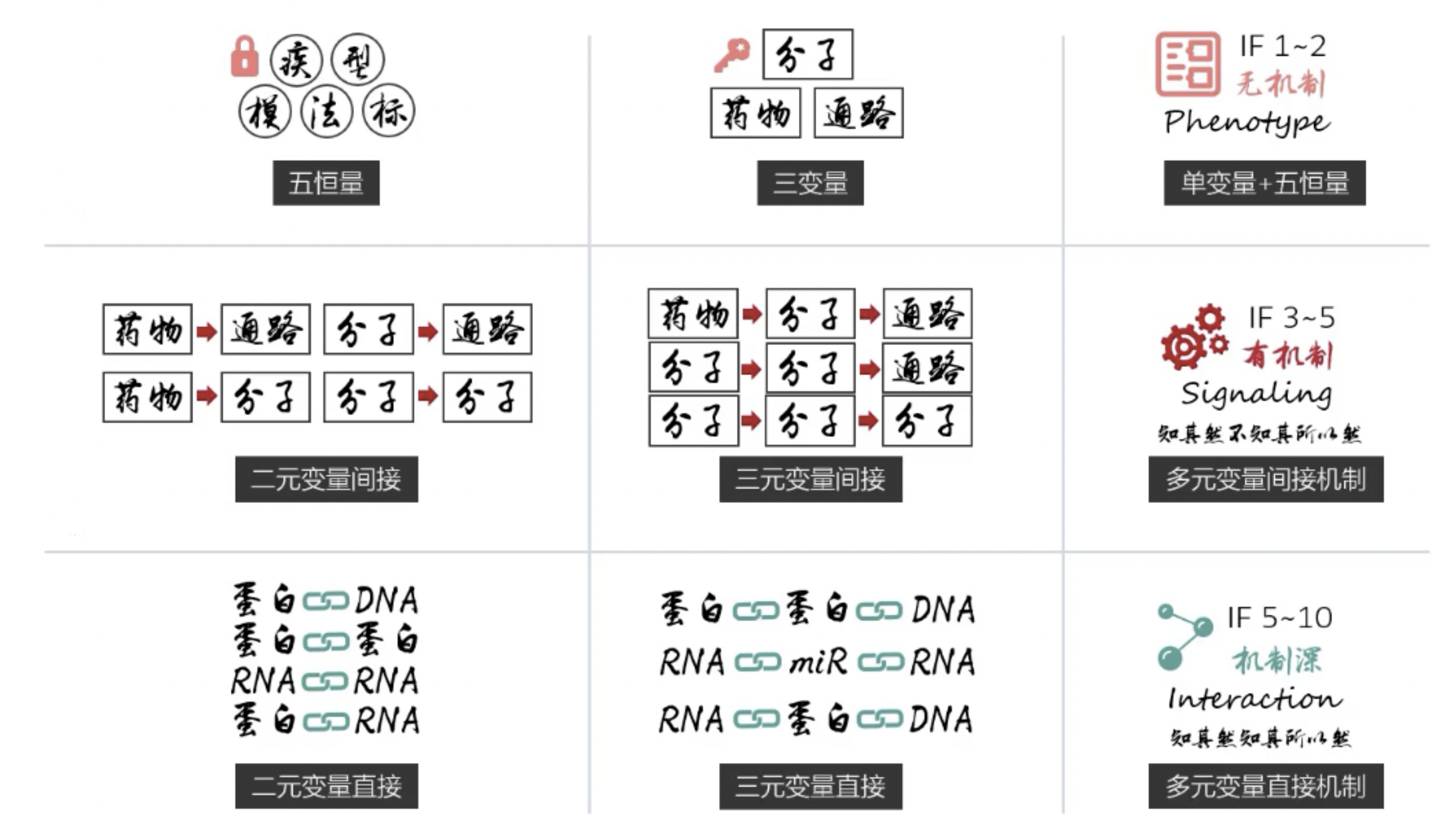
- 前面的课程中我们搭建了一套体系,可以把科研逻辑提炼成上图所示的九宫格。九宫格一共三层,对应了SCI文章水平/含金量爬坡的过程。
- 零基础入门的时候,很多人目标是发IF=3以下的文章灌灌水,那么第一步是掌握恒量套路,把常规的模型、检测方法、标志物都搞清楚,再学会筛、猜找分子,把没人做过的新分子往表型里一套,就是一篇SCI文章。
- 到了IF=3以上就肯定要求有机制了,最简单的机制是下游找通路形成二元结构,这样就能过IF=3,这是九宫格的第二层。如果想发IF=5的文章可能光有下游还不够,最好再上游找个驱动因素形成三元结构,间接机制到了三元上下游都有就顶配了,以Rescue作为数据的质量标准,这是我们36策上半部讲解的逻辑套路,理解了之后IF=5以下的文章能够游刃有余。IF=5以上一直到10分是九宫格第三层,进入了直接作用机制的领域,里面的实验都比较难做所以有门槛。直接作用机制就是分子交互作用,A结合B,B通过文献已经报道的机制影响C或者介导表型,这样你等于在整个信号通路的拼图上填上了自己的一块,增加了非常可靠的证据。这一节课中介绍了用结合位点特异性验证这个主题作为直接作用机制研究策略的结尾,它是所有直接机制的终极一步。
- 间接的调控关系,有没有Rescue证据强度差别很大,而在直接机制研究中,有位点验证的数据完全可以替代Rescue验证,因为位点验证同样是一种必要性证明,并且已到了单个核苷酸/氨基酸水平。直接机制已经是文章细节难度的顶点,文章发到10分以上套路还是只有这些,剩下是思路问题。


