直接机制的论证口诀
- 在三十六策 Lesson 16中我们曾经总结过多元变量论证的十六字口诀,那就是“先辨主次,再分上下,两两调控,三三回复”。这十六字也可以理解为间接机制的论证思路。
- 关于直接机制,我们也总结一个十六字的口诀:“直接交互,分子归类,横向纵向,二维展开”。
- 前八个字“直接交互,分子归类”,相信大家在学习完之前几节课的内容后都很容易理解了,那就是要以交互的分子类型来归纳作用模式,与实验研究方法一一对应。结合“先辨主次,再分上下”,对于机制研究的核心抓手点就有了。凡是看到了文章里出现多个变量,先把谁主谁次的角色分清楚,再把谁上游谁下游的调控关系弄明白,接下来就可以分辨是间接还是直接了。
- 两个分子之间有交互作用并不一定代表他们调控关系,所以有时候文章会跳过调控关系的论证,直接到分子相互作用的实验内容。这时候也不要乱了阵脚,马上想起来口诀还有下半部。“直接交互,分子归类” ,我们需要把什么分子结合什么分子的框架提炼出来,这样对后续出现的数据结果就会产生一定的预判性。
- 然而,直接机制除了分子交互外还有一种展开的形式,在三十六策 Lesson 10中,我们讲分子修饰的时候,提到过纵向的概念。横向是变量间上下游串联,而纵向是变量向内部拓展细节,各种分子修饰就是机制纵向展开的细节模式。
- 在三十六策 Lesson 19中,我们还提到了半套直接机制的做法,修饰属于直接机制,仅仅讨论修饰状态的变化,不揭露施加修饰的上游因变量,这属于直接机制的减配——半套,约等于间接机制的论证强度。所以,纵向拓展也属于直接机制范畴。“横向纵向,二维展开”,这句口诀是告诉你:分子机制研究到了至深的境界是两个维度的叠加,既有横向也有纵向。纵向里面除了分子修饰还有另外一种重要的类型,其实在第10策也提到过,叫可变剪接,alternative splicing。
对标题的解释
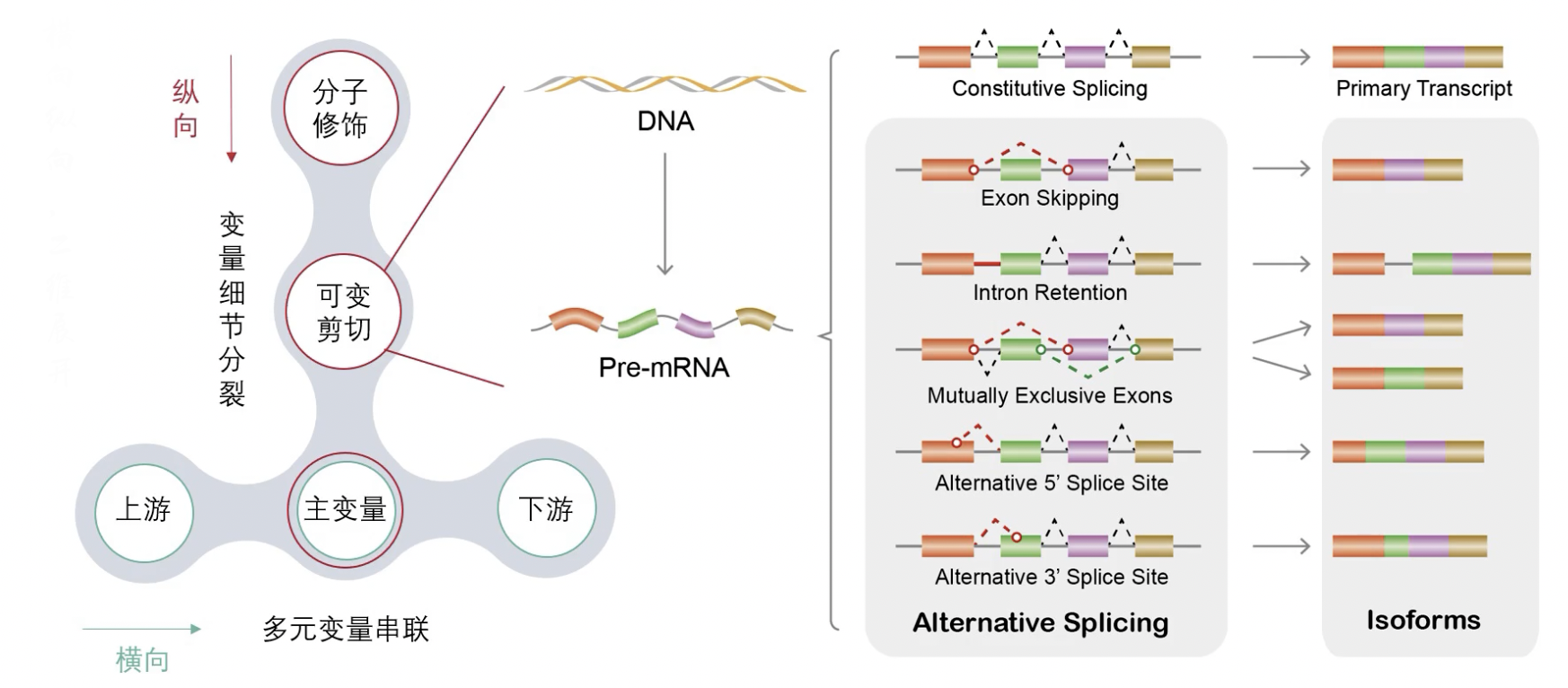
- 本节课的内容“阳奉阴违”形容的是一个基因通过mRNA的转录后加工,形成多个长短不一蛋白的情形。表面看上去一个基因就只是一个变量,但实际上执行这个基因的生理功能的是多个蛋白,也就是不同的变量。
- 可变剪接虽然属于知其然知其所以然的直接机制范畴,但不是之前讲的DNA、RNA、蛋白相互之间做连线,它是mRNA转录出来加工成熟的过程中产生的,RNA水平的变化。我们把转录的初级产物,也就是mRNA前体上,去除内含子,并把外显子连接起来,成为成熟mRNA的过程称为剪接splicing。可变剪接在概念上强调的是,同一个前体mRNA通过了不同的剪接方式,产生不同的mRNA剪接异构体transcript variant。这种同一个基因生出来的亲兄弟,也被称为不同的转录本亚型isoform。注意用语的规范性,isoform一般指的是蛋白亲兄弟,而mRNA水平的亲兄弟叫transcript variant。 所以在文章里看到可变剪接、选择性剪接、剪接异构体、转录本亚型、蛋白亚型其实说的都是一个事情。
- 不同外显子拼接组成不同的转录本形成不同的蛋白亚型,这是生物体Economy原则的体现,优化效率。一个基因编码多个不同转录产物和蛋白产物,能够产生丰富的多样性。
- 可变剪接现象发现的很早,alternative splicing是由Walter Gilbert在1977年提出的,但一直发展的比较慢。到2000年左右,用分子生物学的方法也只发现了数百个有可变剪接的基因,由此推测在高级真核细胞生物中约存在5%的基因有可变剪接。这是受制于技术手段的落后,通量太低造成的误解,后面发生什么事情大家可以猜得到:二代测序来了。高通量测序技术不仅揭开了非编码RNA的大幕,对可变剪接事件的发现也是颠覆性的,根据测序和生物信息学分析结果提示,整个人类基因组大概有35%-60%的基因存在可变剪接形式。为什么是一个范围?因为不同的组织和发育阶段,很有可能存在有不同的剪接变异体,但我们目前还没有办法把所有的组织类型都做全。经由这些高通量研究, 我们可以获得一个结论,可变剪接是具有普遍性的机制,一半左右的基因都有多个转录本,这是一个常规现象,大家习惯就好。
可变剪接类型的课题设计
探索基因的可变剪接形式
- 在三十六策 Lesson 18我们讲数据库类型的时候,讨论了样本数据库、信息数据库、通路数据库和互作数据库4个大类,基因的可变剪接形式就在信息数据库里的三大基因组数据库中,也就是NCBI、UCSC、ensembl。
- 以NCBI为例,查基因一般用GENE这个子数据库,信息比较全,输入一个基因名称,比如说PTEN——PI3K/AKT信号通路的负调节因子。在检索结果界面里第一个,种属是homo sapiens的就是人的PTEN,点进去可以看到基因的介绍,往下拉有很多信息,包括相关的文献等等。其中有一个内容叫NCBI Reference Sequences(RefSeq),就是NCBI数据库里相关序列信息的链接,里面的mRNA and Protein(s),就是这个基因的mRNA和蛋白序列。这些序列是标了序号的,第一个NM_000314.6→NP_000305.3,M就是mRNA,P是蛋白。NCBI里面序列非常多,请大家认准NM和NP,这是经过官方Review过的,品质有保障。后面数字每个序列是唯一的,小数点后的数字是版本号。
- NM号比较重要,因为检测目的基因表达常规操作第一步设计PCR引物,需要知道mRNA序列,给公司设计也要提供NM号才行。检测蛋白倒没那么麻烦,订购抗体往往给个基因名称就行,不用提供序列号。所以,NM号是非常重要的一个基因研究必备的序列信息。我们可以在PTEN基因详情页Refseq板块, 看到有3个NM对NP的已知转录本isoforms,每一个都有description。第一个写了The most abundant isoform,表达丰度最高的,也就是常规意义上的PTEN。它还有另外两种剪接形式,一种更长一点叫PTEN-L,也叫PTENɑ;另一种是更短一点叫PTENβ。 这么明星的分子就没人做转录本功能差异吗? 查了下,2017年3月就有报道 PTENβ 的功能,发在Nature communications上。课题思路便是这么来的,一瞬间的思想火花就可能是一篇文章,都是套路里的常规操作罢了。
- 这里还有一个知识点,大家看基因名称后面有时候有数字,1234。比如我们在文献一点通里面有一篇DDR1和DDR2双变量的文章。DDR1、DDR2是同一家族的两个基因,是因为有结构和功能上的相似性才被编成同一组,1234这样排下去形成family家族。如果在基因名称后面看到跟着αβγδ这种拉丁字母,或者是小写的abcd,这就不一样了,属于同一个基因,因为不同的剪接变异形式产生的不同转录本、蛋白亚型。当在一篇文章里面涉及多个变量之间 的调控关系的时候,我们称为二元、三元变量。而同一篇文章里面研究123、αβγ这样同一家族或者同一基因的不同亚型,它们不是调控关系,而是平行结构,这个可以称为双变量、三变量。在一个课题中研究不同转录本的功能差异,属于多变量的层次(注意不是多元变量),是讲兄弟关系同一辈分,不是下游上游的因果关联。多变量当然工作量也是翻倍上去的,自然对文章也有显著的加分效果。尤其是多变量执行功能还存在不同的时候,故事会更加精彩。
可变剪接对课题创新性的贡献
- 领悟了可变剪接的纵向展开,我们在分子的认识层面就多了一个考虑问题的崭新角度。之前很多人做过一些创新性不是那么好的蛋白,文章发得比较水,申请基金就发现吸引力不足,如果从可变剪接的角度重新挖掘一下,往往能造出一个创新性高出很多的课题来。
- PTEN在17年还发Nature communications,我们选的分子再老能有PTEN老吗?这种套路在国自然里早就有人用,但一直不温不火的小众品类,每年不到 20 项资助的样子。可变剪接很普遍,所以这种研究模式对于很多分子都可能适用,不过一个基因转录本太多的情况下,你做起来还是有点头疼。最好的数量是2个或者3个已知转录本,一旦超过3个以上,就不是在一个课题里面能cover的了,应该通过预实验确定某一个具有特别的表达分布或者是功能表型的亚型来聚焦研究。
- 我们可以推理一下不同的转录本可能造成什么样不同的功能结果
- 第一种情况,不同转录本编码同样的蛋白,但是mRNA的非翻译区不一样,所以翻译调控不一样
- 第二种,编码不同的蛋白但功能一样。这没意思,文章没人看,课题做出这种结果属于悲剧,工作量上去了但是故事的复杂性毫无贡献。
- 第三种,编码不同的蛋白,且功能不一样,属于各司其职。我们经常发现一个蛋白具有多样的功能,比如肿瘤里面一个基因跟增殖有关,跟转移有关,跟细胞干性有关,恨不能各种表型百搭,那不同表型背后的机制肯定是不一样的,用不同转录本执行不同功能来解释不同机制,就有一种 “哇,原来如此”的揭晓谜题的感觉。
- 第四种情况,编码不同的蛋白,功能不但不一样而且相反,具有拮抗作用,这剧情就更跌宕起伏了。一个基因可能是好的,也可能是坏的,至于处在好还是坏的一面,是因为不同转录本表达调控的细节决定的。当转录本的表达发生反转,基因的功能也就反转了。我们有时候实验中会发现人家报道这个基因是癌基因,我偏偏做出来抑癌基因的功能,趋势是反的,有没有碰到过?这种情况其实并不少见,医学研究本身就极其复杂,你的数据跟文献矛盾,这即使是事实,在文章审稿人问起原因时还是不太好 回答,只能强行辩解说是模型的异质性,具体怎么回事,太多可能性了,没法说。但是,一旦你用不同转录本执行拮抗的功能这种机制模型,成功解释了分子介导表型矛盾现象的原因, 这文章就完美的自圆其说了,瞬间有一种土鸡变凤凰的体验。
- 看到这里心里又痒痒的了?不要太冲动,这种双变量的文章,等于机制也要做两套,可没那么简单。不过换种思路, 解决不了问题,就解决提出问题的基因,大部分人遇到这种困难,换个分子避开矛盾就继续灌水去了,没有几个人能真正锲而不舍经得起这种折腾,这也使得此类题材的文章尤为稀少,物以稀为贵。
可变剪接的课题设计
- 在双变量、三变量论证的过程中,单变量的一套逻辑依然是通用的。
- 先检测变量的表达差异,在细胞水平中表达有差异是功能有意义的前提。在不同组织中,不同转录本优势表达很可能不一样,这是已经被文章证实的。可变剪接既可以在同一细胞中产生多种蛋白,也可以在不同细胞中呈现不同的剪接方式,表现出组织特异性。有些情况下是在不同发育时期或特殊条件下采取不同剪接方式,表达不同蛋白,介导精细调控。
- 理解了转录本在时间、空间上的特性,选好了组织标本、细胞株对象,实际检测起来还比较简单,设计引物定量PCR一下。蛋白水平没有针对每个亚型的特异性抗体可能检测不便,mRNA水平,序列不一样就能设计出来特异性的引物,进行分别的转录本检测。
- 表达差异做完之后,下一步是一正一反操作观察表型,Gain of function 还好,都是构建过表达载体,编码框CDS是人为装进去的,不同的剪接变异体可以分开做。但Loss of function可能RNAi做不了,因为siRNA必须针对特异的序列来设计,才能保证靶向沉默。然而有些情况下,两个转录本之间只有几十个碱基的差异,或者长的版本覆盖短的版本,导致可以设计siRNA序列的空间不足。这里就有一种非常聪明的方法, 做转录本的文献里经常能看到,先沉默再过表达的Rescue。特异性的siRNA设计不出来是因为转录本之间同源区太多了,那么索性针对同源区设计一段siRNA,把所有转录本都敲了,然后一个一个Rescue过表达进去,看功能情况,问题就解决了。这里用CRISPR把基因在DNA水平敲除掉,再一个一个表达不同的转录本观察功能也是可以的。 常规的实验设计策略就是这些,根据需求灵活配置才是王道。
可变剪接课题的工作量
- 我们来体会一下单变量设计的研究和做转录本双变量甚至三变量的研究工作量的区别。单变量是表达差异,一正一反,2株以上的细胞做表型,再用动物模型验证,最后加上机制探讨 升级成二元调控关系,找一个间接或者直接作用的因变量分子。
- 转录本研究在组织表达上就多了检测对象,工作量翻倍。然后到了表型实验还要加分组,假设3个转录本,除了3个单独表达之外,严谨起见也要做两两组合的分组。这么一弄工作量就很吓人了。表型做出来了,不同转录本也有差异,就这么发表没机制有点浪费,好歹也要探讨一下不同的通路和明星分子,聊一聊Why和How的问题。既然转录本功能不一样,机制肯定是不同的,这样才能自圆其说。本来可以发几篇文章的工作量都并到一篇文章里了,之前老树开新花的喜悦已经荡然无存。不过如果真的都做完了,这样恢弘的一个story到10分还是可以指望的。
- 实际上,作为主变量的分子分裂一下,出来很多个亲兄弟,在同一篇文章里作为双变量、三变量研究,本质上可以看成是单变量的一种升级模式,平行展开。这样的纵向突破一样可以搭配上游和下游的二元、三元调控关系,加上横向的展开维度形成一个极为立体的结构。可变剪接的下游,主要是为了解释表型,还是找明星分子或通路。可变剪接的上游,可以找 参与可变剪接的蛋白酶,这跟分子修饰找相应的蛋白酶一样,是个固定搭配。小范围的筛一下已知的调控可变剪接的酶里面哪个调控了研究的这个主变量的可变剪接,使得不同转录本表达丰度发生变化,这就是上游机制的问题。
- 前一篇文章把表型功能下游机制发掉,讲的是不同转录本功能不同的故事,后面申请基金就可以找上游某一个酶,调控这个基因可变剪接的过程,形成一个有延续性的课题,这种设计国自然还比较喜欢。
- 有些同学要说了,我这个基因转录本非常多,没法弄。转录本多于3个,想一次性研究清楚工作量会变得超越极限,怎么办呢?只有一个办法,选其中一个转录本来研究。人家都做PTEN,你做PTENβ也是有新意的,这种套路基金申请时候也能看到。有的研究者做了高通量筛选,本身筛选结果里面就会提示某个转录本表达有显著差异,这是前期工作的提示。如果没做高通量,干脆猜也是个硬办法,碰碰运气。这种情况下其实就是一个新的分子代入五恒量,然后上下游做机制,回到了前面的套路规范里。
总结与复习
- 分子作为主变量,最复杂的地方就在于它的纵向展开。可变剪接是一种,让一个分子变成了多个亚型。分子修饰是另外一种,从DNA到RNA到蛋白有好多修饰形式。RNA水平有一种常见的修饰形式叫m6A甲基化,如果一个选择性剪接的转录本上面还有RNA甲基化调控,这会不会是一篇很牛逼的文章?m6A甲基化可以作为可变剪接识别的一个信号,这种cross-talk绝对是非常新的领域。除了可变剪接+分子修饰的纵向两层嵌套,新的分子类型——非编码RNA也有可变剪接的展开模式,连最新的分子类型circRNA可变剪接的文章也都有。其实搞基础科研构思的时候,说穿了就是在做拼图,各种可能性组合一下,思维模式有一定惯性规律。横向纵向的二维展开也进入了直接作用机制的范畴,加上分子交互的细节,基础科研的逻辑模型就到了一个非常复杂的程度。
- 单变量没机制的文章一般过不了3分,很多学员会觉得这种文章很简单,确实,因为逻辑上有点像是非判断题,有功能还是没有功能,表型实验来验证。只要记住有组织、细胞、动物三个维度的数据可以呈现,逻辑就完整了。
- 多元变量就是有机制的文章,要做到条理清晰,哪个是主变量,哪个是因变量的主次关系不能混淆。围绕主变量来论证是一篇文章的核心逻辑, 因变量论证一定有省略的步骤,不要把对主变量的套路用到因变量上,在这里区别对待是一个基本原则。主次之后,关于上下的问题就是搞清楚到底谁调节谁。“你动我也动”是一个金标准,也就是说人为改变上游,下游应该随之而动,主要是上下调的变化,也包含一些特殊的分子修饰变化。反过来操作下游,上游是不会变的,所以一旦出现过表达或者干扰一个变量检测另外一个变量,进行分子操作的这个一定是上游,发生变化的必然是下游,绝对不会错。
- “你动我也动”只能证明间接,如果是直接机制那就一定有co-IP、RIP、pulldown、Luciferase这些经典实验,看到这些实验标志,脑子里立马反馈一个信息,知其然知其所以然的直接机制出现了,文章的档次也上去了。要把直接机制搞清楚,依据分子类型来逻辑归类是最好的方法。但是直接机制不仅仅有分子交互,今天我们介绍了直接机制中的可变剪接模式,就跟分子交互有些许的不同,是一种平行的变量叠加,而且变量间还有亲缘关系。不同的转录本产生不同表达形式,这就像我们说虚岁是按爸爸身体里出来算的,周岁是按照妈妈身体里出来算的,两套机制两种结果。
- 之前有学员问decoy机制里LncRNA竞争性结合转录因子是怎么做到的?转录因子怎么会把 RNA误认为DNA呢?我的回答是因为太像,原本不一样的两样东西,却相互替代、相互竞争,被看成一样的,这是一种分子机制模式。而可变剪接是把原来认为是一个蛋白执行的复杂功能,转化成不一样的蛋白分工协作,又构成一种分子机制模式。不一样的看成一样的,一样的原来是不一样的,看透了逻辑上是换汤不换药。既有上下游多个分子嵌套,又有主变量的可变剪接精细调控,这是高分文章才会采用的豪华路线,能洞悉这一切需要修炼蛮长时间,修炼到了,你靠科研吃饭也没有什么问题。
- 高分文章基本都是秉承着剧本要有反转才精彩、逻辑要绕到你看不懂才高端这样一个套路,非要把真相掩饰得不可捉摸,可是说到底再复杂的分子机制研究,也不过是横向+纵向的二维展开而已。如果你自己能领悟我说的知识内涵,相信再读文献会有一种一览众山小的“傲娇之气”。



