


总结:多元变量的论证口诀
先辨主次,再分上下,两两调控,三三回复
先辨主次
- 一旦涉及多元变量在同一篇文章里,首先要做的是分辨主变量和因变量
- 主变量的信息一般在题目里就能分辨出来,绝大多数情况下主变量都在题目前半句,很显眼
- 识别了主变量,那么顺理成章的是,单变量论证的12字对于主变量依然是有效的,规则前后兼容
- 但对于因变量来说没有必要,因为因变量一般都是明星分子,它跟表型之间的关系前人文章如果已经证明过,省略这部分论证反倒可以突出重点
再分上下
- 确定主变量和因变量后,下一个要做的事分清这俩之间的上下游关系
- 上游可以调节下游, 反之下游是不能调节上游的
- 下游机制解答分子为什么有表型的问题,上游机制解答分子为什么出现表达差异的问题,它们的功能有所不同
两两调控
- 在三元变量或者更多变量组合的情况下,变量间最基本的关系还是两两配对建立调控关系。
- 凡是看到了文章里操作一个分子,检测另外一个或者多个分子的表达,这就是变量间上下游关系的因果证明环节。操作一个上游的变量,看下游变量变化,是“你动我也动”——“两两调控”
三三回复
- 调控关系是操作一个变量,而Rescue一定是操作2个变量,一个上游, 一个中游,观察的是第三个指标——要么是最终表型的变化,要么是下游的变量。
- 多元变量的Rescue验证是三个环节组成的,比调控关系多了一环
变量交互的直接机制:用分子类型归类
- RNA和蛋白与DNA、RNA和蛋白分别连线,形成2✖️3=6种分子交互模式
- 这样分类的好处:直接机制的实验也是按照分子的类型来分类的,比如同样是RNA,无论是不是编码的mRNA,只要是研究与蛋白的结合,研究的套路都是一样的
第一个简单模式:RNA调节RNA
- 比如之前说到的miRNA靶向于功能基因mRNA的3’-UTR,影响分子的转录
第二个简单模式:转录因子
- 转录因子是蛋白,结合的启动子序列是DNA,影响的是靶基因转录,从DNA产生mRNA的过程,效应结局是mRNA量的多少变化,造成靶基因蛋白量的上调或者下调
复习:基因的转录
- 转录transcription,指的是遗传信息从DNA转移到RNA的过程,这里的RNA是 信使RNA,又叫mRNA,即messenger RNA,合成mRNA是合成蛋白质的前面 一步,从mRNA到蛋白术语叫翻译,Translation
- 在转录过程中DNA是模板,RNA是100%完美的复制品,抄完了序列是完全一样的,但是笔迹不一样。 DNA用脱氧核糖核酸,RNA用核糖核酸
- DNA很稳定,存个几万年都没问题,分子人类学利用母系来源的线粒体DNA和父系来源的Y染色体分析人类的起源和迁徙演化就是靠它。而RNA不太稳定,半衰期几分钟到几小时,最长几天,很容易降解,一般是需要用了就新鲜加工,保质期很短。
- 转录过程跟DNA自身复制有很多相似的地方,DNA复制要用到DNA聚合酶,转录需要RNA聚合酶,它们都需要以DNA作为模板。有区别的地方是转录过程还需要一些特殊的调控性蛋白参与,而DNA复制基本不需要。这些调控的蛋白与RNA聚合酶形成复合物,共同调控整个转录过程。尤其是在转录起始和终止的时候,这些调节蛋白发挥至关重要的作用,我们把在转录起始过程中起到协助作用的蛋白称为转录因子 (transcription factor,TF)。
- 转录因子TF是转录这个story中的主角,因为它起到调控性的功能,相对的,真正执行转录的RNA-pol只是没有决策权的“打工人”。
- 转录因子的功能是两面的,促进转录、抑制转录正反派都行。
- 一个奇妙的比喻:当转录因子促进转录的时候,就像小弟拍老大马屁,上厕所把门帮着拉开,拉完了还给递个纸,恨不得帮老大把屁股也擦了。时间一长,老大一想到上厕所就会想到这个小弟,成了刚需,形成了固定套路。当转录因子是正向作用时,等于说没有它的帮忙,RNA聚合酶启动不了mRNA的合成。在大部分情况下, 转录因子对转录起到的是正向促进作用,这是一种思维定式。
- 一般我们喜欢研究致病因子,也就是在疾病中高表达的分子。高表达的原因是什么呢?上游受到某个特异性的转录因子驱动,这是一种自然而然的逻辑,是基础科研里条件反射一般的推理过程。
- 人类基因里已知预测了有2000+,不到3000个转录因子,占到整个编码基因的接近10%,这可不是一个小数目,如果把转录因子看成一个蛋白家族,它就是最大的家族。在这样一个庞大的family里,除去那些默默无闻的幕后工作者,也就是没有特异性的普遍转录因子,大部分成员受到特殊信号调控、或者具有组织细胞特异性,就像开关。而开关很容易在科研中成为大众情人,是百搭的变量对象。
- 抑制转录的主要模式是转录因子结合DNA序列,从而阻止RNA聚合酶与启动子的结合。促进转录的蛋白又可以叫激活子(activator),而抑制转录的又叫抑制子(Repressor)。在原核生物里, 发挥转录抑制作用的蛋白还有一个专有名词叫阻遏蛋白,也是差不多的机制。
- 招募或者稳定RNA聚合酶与DNA的结合只是转录因子最常见的功能,除了帮忙或者捣乱外,它也有其他作用机制,比如转录因子还可以招募对组蛋白进行修饰的酶,组蛋白修饰也是基因转录的重要调控对象。
转录因子在变量嵌套中的作用
- 在我们的多元变量组合的体系里,向上找上游驱动因素,向下找下游效应环节是固定的逻辑闭环。转录因子是其中最常见的一种驱动因素,同时它还是信号通路三大基本元件之一,位于受体和激酶的下游,受体接受信号,激酶放大信号,最后执行生物学效应的开关就是转录因子,它是通路的明星Biomarker。
- 文章里经常看到的套路是:发现了个新分子,为了解答它为什么表达上调,找到一个已知的转录因子的变化,证明它们调控关系作为上游机制;下游做通路的时候,把几个明星的转录因子表达检测一下,就算交代了Why的问题。
- 除了做因变量,转录因子也是很热门的研究对象,一个课题高通量筛完,候选分子里面出现了新颖的转录因子,可以直接拿来做主变量。转录因子是个全能选手,可以胜任多元变量上中下任何位置,上游的驱动因素可以找明星的转录因子来担当,下游效应机制里也可以用转录因子的明星站台,如果它自己有创新性,跟表型的关系没有报道,单独唱一台戏也行,灵活多变。
补充知识
- 转录因子有一个显著的结构特征,所以我们才知道有两千多个蛋白可能是转录因子。这个特征是所有转录因子都包含一段DNA binding domain,也就是与DNA结合的结构域,这个结构域能够识别和结合DNA序列。
- DNA是带负电荷的,在20种常见氨基酸里,赖氨酸、精氨酸和组氨酸、 这些带正电氨基酸是产生DNA binding domain的特异性序列,正负相吸。同时,这一段结构域还会形成特定的空间结构,与DNA骨架相互匹配。什么样的氨基酸序列和结构喜欢结合什么样的DNA序列有一定规律的,这种规律是预测转录因子调控靶基因的理论基础。
复习:真核生物的结构基因
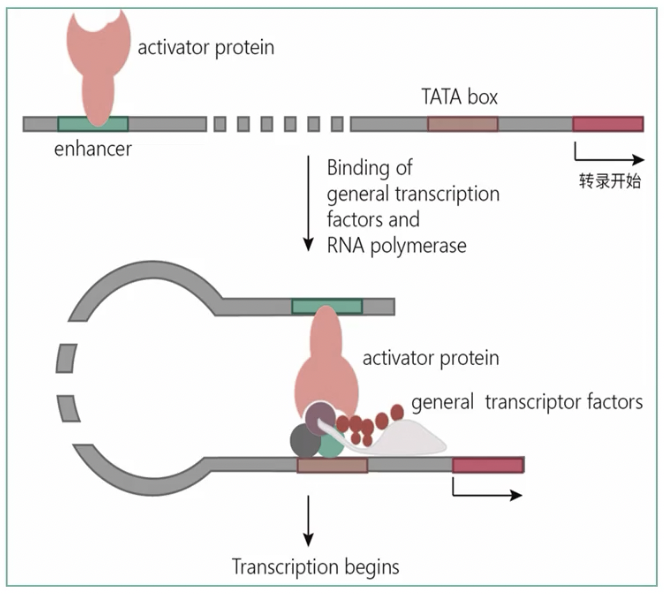
- 基因是一段DNA,这段DNA可分为编码区和非编码区。
- 编码区叫CDS,coding sequence,指的是用来编码产生mRNA的一段序列。
- 基因还有非编码区,称为noncoding sequence,这跟非编码RNA(noncoding RNA)不一样,noncoding RNA是指不编码产生蛋白,而DNA的非编码区连RNA都不编码。
- 这段序列用于执行转录的调控功能,它的位置是位于编码区的5’-端和3’-端的邻近区域,跟编码区挨着,所以这些非编码序列也称之为侧翼序列flanking sequence。
- 侧翼序列包含了基因的启动子promoter、增强子enhancer、终止子terminator这些转录调控元件。这其中研究的最多的就是promoter。启动子里含有RNA聚合酶的特异性结合序列,同时可以跟转录因子结合,控制基因的转录活性。
- 就像像受体和配体是一对搭档,转录因子和启动子也是一对搭档,找一个基因上游调控的转录因子,其实是找这个基因启动子序列能够结合的转录因子,而找一个转录因子能够调控的下游靶基因,也是找转录因子能够结合的启动子序列,从而判断它到底调节什么基因。
转录因子相关的科研怎么做
- 如果你已经获得了一个有功能的分子,你想上游找个转录因子用来解答它被谁调控的问题, 那么第一步应该是去找这个基因的启动子序列。
- 我们前面讲过需要查基因序列的话,可以用NCBI的Gene和Nucleotide数据库,用来设计引物,构建克隆等等。但是,查启动子序列的话, 我推荐另外两个数据库UCSC和Ensembl。
UCSC数据库简介
- UCSC是University of California Santa Cruz的缩写,UCSC基因组浏览器就是这个大学开发的,里面有多个物种的基因组信息,很全面,检索非常方便。

Ensembl数据库简介
- Ensembl是一个基因组注释的数据库,是欧洲的一个科研项目,是一个整合型 的数据库,整合了很多来自于其他数据库的源数据。当我们想查突变、转录本、同源蛋白、包括查启动子,用UCSC或者Ensembl,要比NCBI好用一点。
分析基因的启动子
- 启动子并不像基因的编码序列一样,具有特征明确的起点和终点
- 我们有时候一时确认不了Promotor区域有多长,一般选取基因翻译起始位点 ATG密码子上游至少1000bp,保险起见2000-3000bp的区域作为启动子候选序列,把这段序列拿出来再进行进一步分析。分析启动子可以用 promoterscan或者promoterInspector这两个在线的工具,使用搜索引擎即可
克隆/购买基因的启动子
- 明确启动子序列之后,接下来要把它克隆出来,后面的实验里要用到。有些基因的启动子克隆是可以商业化买到的,这就更加方便了。
预测与靶基因启动子结合的转录因子
- 明确基因启动子序列以及获得它的克隆,是研究转录因子调控靶基因的前置步骤,下面还要预测有哪些转录因子可能跟你的靶基因启动子存在结合,这里也需要用数据库
- 一个较为常用的数据库:JASPAR
- JASPAR是收集有关转录因子与DNA结合位点基序(motif)的最全面的公开数据库,它总结了大量转录因子能够结合的DNA序列特征,这样一段特征性的DNA序列叫motif。只要我们给定的启动子序列里面包含某些motif,它就能预测可能结合的转录因子
- 这个数据库是由University of Copenhagen制作的,在转录因子与启动子结合预测方面很权威。
- JASPAR的缺点是界面不太友好,有一堆数据库自定义的术语,用起来很伤神,不过我们也有单元课教程。
- 就像miRNA预测靶基因一样,同类的数据库会有好多个,一般文章里的做法是几个数据库一起预测然后取个交集。当然关键还是后面实验验证要成功,哪怕只用了一个数据库预测,只要能验证出来, 也行。
证明转录因子和靶基因启动子之间存在直接结合
- 如果想偷懒,只做一个实验验证,那就选择Luciferase assay,因为这个最简单,也是转录因子文章里面的标配
- 但是,一般来说,两个相同目的但不同原理的实验相互佐证,是基础科研严谨论证的基本要求。就像要选2株细胞重复实验确认表型,或者细胞动物体外体内双重验证一样,ChIP和EMSA常规来说,要选一个作为荧光素酶报告基因实验的补充验证才能让文章审稿人满意
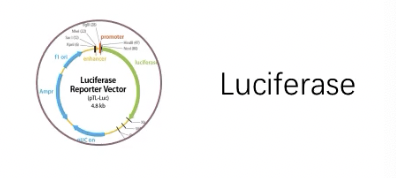
经典实验1:Luciferase,也就是荧光素酶报告实验
- 复习三十六策 Lesson 11
- 用于miRNA靶基因检测的荧光素酶报告基因:载体的插入位点在荧光素酶编码区的3’-UTR,也就是把靶基因的3’-UTR替换到荧光素酶报告基因的3’-UTR。这样如果miRNA对3’-UTR有调控的话,荧光素酶的翻译表达就会改变,在实验中检测荧光信号就知道了
- 用于转录因子研究的荧光素酶:载体的多克隆位点在启动子区域,是把靶基因的启动子给克隆到荧光素酶编码区的5’-端,用于启动荧光素酶的转录。如果转录因子能调控这个启动子,当转录因子和这个报告基因载体共转染的时候,荧光素酶的表达也会改变
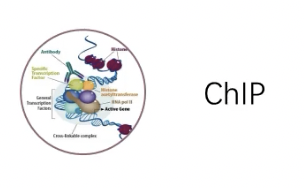
经典实验2:染色质免疫共沉淀ChIP实验
- 和基因芯片chip完全不是一个东西。
- 凡是分子交互的对象中有一个是蛋白,那么免疫共沉淀就是一种重要的研究方法。
- 免疫共沉淀的设计原理:用抗体把蛋白拉下来,同时把蛋白结合的东西也拉下来,然后去鉴定,看拉下来的结合物是什么。
- 具体来说,ChIP实验的过程是先用交联剂固定蛋白和DNA复合物,然后超声破碎把基因组打成小片段,再利用特异性抗体富集靶蛋白和DNA的复合物,富集完后再解交联,对目的DNA片段进行纯化与检测,这样就可以获得转录因子与DNA相互作用的信息了。
经典实验3:凝胶迁移实验EMSA

- 原理:蛋白与核酸探针的一旦结合形成复合物, 在凝胶电泳过程中迁移会变慢。
- 实验的过程是设计一个特异的同位素标记探针,然后把探针和样本蛋白混合孵育,样本中可以与核酸探针结合的蛋白形成蛋白-核酸复合物。复合物分子量大,在凝胶电泳时迁移较慢,而没有结合蛋白的探针跑得快,通过条带就能判断蛋白与探针是否发生互作。
证明转录因子和靶基因之间存在某种功能调控
- 为了证明上游调控的转录因子与靶基因存在功能上的联系,还要做一个过表达或者沉默转录因子,观察下游靶基因mRNA、蛋白表达水平变化以及表型变化的内容,再严谨一点,还得来一个Rescue
- 直接机制不意味着前面间接机制研究的数据可以不做,多元变量上下游关系判定的“你动我也动+我不动,你动也不动”的研究套路也是要做的。
- 好文章是数据堆出来的。
总结与回顾
- 在多元变量体系里,主变量需要解答它调控谁以及被谁调控的两个机制的问题。往下游走靠明星通路这一类间接机制的做法,我们在三十六策 Lesson 13和三十六策 Lesson 14介绍过了,往上游找间接作用机制是比较别扭的,因为你没法通过操作主变量,观察上游变化来发现,下游会随之而动,而上游并不会。
- 这种情况下,更多可以考虑从直接机制上入手。直接作用机制可以从基因水平、转录水平、转录后水平、翻译水平和翻译后水平五个层次来执行调控,并且搭配成蛋白结合DNA、RNA和蛋白,RNA结合DNA、RNA和蛋白,一共6种分子交互形式来细化套路的认识。
- 这其中,转录因子是蛋白结合启动子DNA,调节靶基因mRNA转录表达的经典研究框架,在文章上游机制的解释中应用比较广泛。
